
Month: June 2015
A Handy Query for SQL Server
Here is a nice query that you won’t find everywhere that could be rather useful
- A query to fix duplicates and clean-up your ‘look-up’ tables
Query: Clean-Up Your Duplicates!
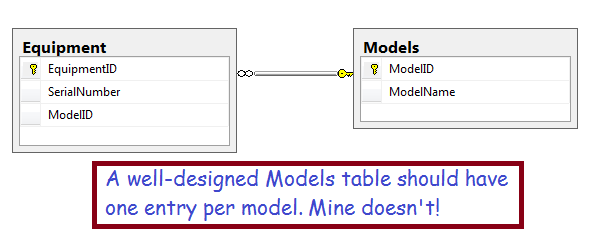
The diagram above illustrates the relationship between equipment and models. A well-designed Models table should have a unique-constraint on the ModelName column to prevent duplicates. My table doesn’t. This can happen if you get data from users who don’t understand the problems this can create!
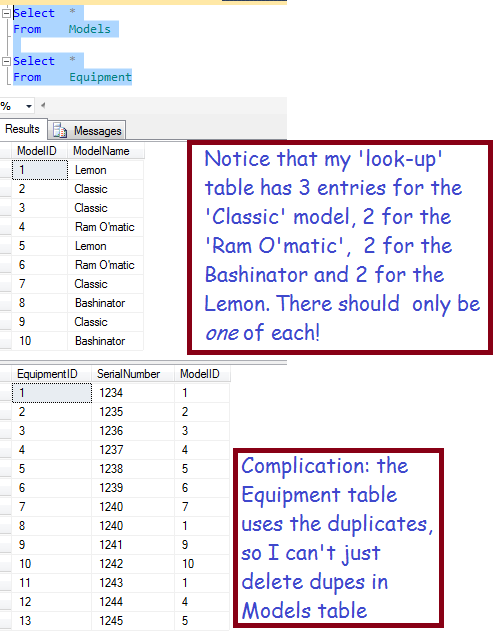
Here’s the Query!
Update Equipment Set ModelId = (Select idsToUse.theId From (Select ModelName, Min(ModelId) theId From Models by ModelName ) idsToUse Join Models m on m.ModelName = idsToUse.ModelName Where m.ModelID = Equipment.ModelID )
Does that look like a bunch of impenetrable gobbledegook? Allow me to explain!
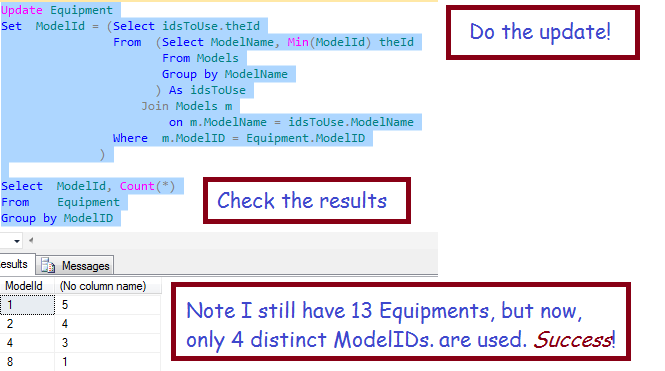
The following subquery (from above) is used to select the lowest model ID for each model name:
Select ModelName, Min(ModelId) theId From Models Group by ModelName
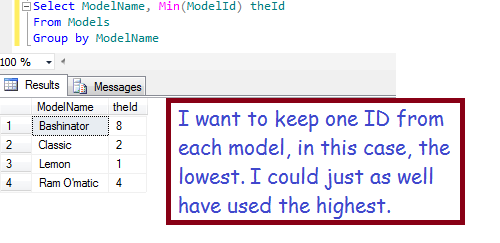
Notice that, in the main query, I convert the results of this subquery into a derived table, which I call ‘idsToUse’.
Having created a ‘derived table’ containing a list of IDs to use
- Join the derived table ‘idsToUse’ against Models on ModelName
- The result is a data set with every ModelID in use, associated with the ID we should use instead
- Now, select the good ID from the join results (in the where-clause)
- And use it to update the Equipment table, by matching against the ModelID from Equipment
- Resulting in every ModelId being replaced with the minimum
- Which is what we want!
The Last Step
At this point, we have fixed the Equipment table,
- Now, only one of each ModelId is in use
The easy part is deleting the duplicated model names form the Models table. We will delete every model ID except for the minimum of each group, with the following query:
Delete Models Where ModelId Not in (Select Min(ModelId) From Models Group by ModelName )
This query wouldn’t have worked unless we previously fixed the Equipment table, because referential integrity would have prevented us from making orphan records. It would have prevented deleting ModelIds that are in use in the Equipment table.
Summary
Cleaning-up your database is a good way to make sure you can generate good reports and keep your sanity. Cleaning-up duplicates is a tricky chore. Finding the dupes is not too hard, and my query showed how you can pick one ID from each repeated model name. Then I showed you how you can use those good IDs in a derived table, which you can then utilize as a way to look-up every model ID in the equipment table and map it to the correct ID to use.
