
SQL Server
SQL Server Function: TitleCase
T-SQL TitleCase Function: Beyond the Obvious
Periodically, you may need to convert text into mixed-case in SQL Server. I needed it because our legacy database stores all our customer names in upper case. For example, one of our customers might look like the following:
- Legacy sample customer: “ACME CLIENT, LLC”
- Desired customer name: “Acme Client, LLC”
Anyone can write a simplistic title-case function pretty quickly. I enhanced mine to handle the following special cases:
- State initials ID/WA/OR/WY/UT/NV/MT are capitalized
Select dbo.TitleCase(‘This is id and it is better than mT or Wy’)
This Is ID And It Is Better Than MT OR WY
- Leaves most 3-letter abbreviations capitalized
Select dbo.TitleCase(‘RYO CORRECTIONAL FACILITY’)
RYO Correctional Facility
- Removes repeated spaces
Select dbo.TitleCase(‘Had double spaces’)
Had Double Spaces
- Preserves special characters
Select dbo.TitleCase(‘Has special character ‘ + NChar(8631) + ‘ embedded’)
Has Special Character ↷ Embedded
- Runs reasonably fast (but would run faster if we built a table to hold my list of 3-letter English words)
In order to preserve 3-letter abbreviations, I had to get a list of English words. When my function encounters a 3-letter word, it checks to see if exists in my list. If so, convert to mixed case; otherwise leave all upper case.
Here’s the script
-- Author: ActualRandy
-- Create date: 1/06/2016
-- Description: Sends a string to Title Case while preserving abbreviations, also cleans-up repeated spaces
/*
Usage:
SELECT dbo.TitleCase('This has "quotes" in it. AND IS MIXED upper AND LOWER CASE.')
Select dbo.TitleCase('THIS IS WA')
Select dbo.TitleCase('Has special character ' + NChar(8631) + ' embedded')
*/
ALTER FUNCTION [dbo].[TitleCase] (@InputString NVARCHAR(4000) )
RETURNS NVARCHAR(4000)
AS
BEGIN
DECLARE @Index INT --Position within the input string
DECLARE @Char NCHAR(1) --The character we are examining
Declare @Word NChar(3) --3-letter word that might need to be upper case
DECLARE @OutputString NVARCHAR(4000) = '' --What we return
Declare @IsStartOfWord TinyInt = 1 --When 0, we are in the middle of a word
Declare @StateAbbrv NChar(2) --2-Letter string that might be a state
Declare @LastChar NChar(1) = '' --Previous character we examined
If @InputString Is Not Null
Begin
Set @Index = 1
While @Index <= Len(@InputString)
Begin
Set @Char = Substring(@InputString, @Index, 1)
--If we found repeated spaces...
If Not (@Char = ' ' And @LastChar = ' ')
Begin
If @Char = ''''
Begin
Set @OutputString = @OutputString + @char
End
Else If @Char in (' ', ';', ':', '!', '?', ',', '.', '_', '-', '/', '&', '(' )
Begin
Set @IsStartOfWord = 1
Set @OutputString = @OutputString + @char
End
Else
Begin
If @IsStartOfWord = 1
Begin
--Are we 2 letters from the end?
If (@Index = Len(@InputString) - 1)
Or
--Are we more than 2 letters from end of InputString, but just 2 letters from end of the current word?
(
@Index < Len(@InputString) - 1
And
SUBSTRING(@InputString, @Index + 2, 1) in (' ', ';', ':', '!', '?', ',', '.', '_', '-', '/', '&', '(' )
)
Begin
Set @StateAbbrv = Substring(@InputString, @Index, 2)
If @StateAbbrv in ('ID', 'OR', 'WA', 'MT', 'NV','UT', 'WY')
Begin
Set @OutputString = @OutputString + Upper(@StateAbbrv)
Set @Index = @Index + 1
Set @IsStartOfWord = 1
End
Else
Begin
--We have a 2-letter word, but it is not a state abbrv
Set @OutputString = @OutputString + Upper(@char)
Set @IsStartOfWord = 0
End
End
--Are we looking at a 3-letter word?, i.e. are we within
-- the string and the 4th character hence is not a letter
Else If (@Index <= Len(@InputString) - 2)
And
SUBSTRING(@InputString, @Index + 3, 1) in (' ', ';', ':', '!', '?', ',', '.', '_', '-', '/', '&', '(' )
Begin
Set @Word = SUBSTRING(@InputString, @Index, 3)
--If it is a 3-letter word in English
--For brevity, I shrunk-down my list of words, which is actually quite huge
If @Word In ('aah', 'ace','act','add','adj','ado','zoo')
Begin
--Set it to normal casing because it is an english word:
--uppercase on letter 1 and lowercase for the last 2:
Set @OutputString = @OutputString + Upper(@Char) + Lower(Substring(@InputString, @Index + 1, 2))
Set @IsStartOfWord = 0
Set @Index = @Index + 2
End
Else
--Probably some initials or abbreviation; i.e. a 3-letter string, but not an English word
Begin
Set @OutputString = @OutputString + Upper(@Word)
Set @Index = @Index + 2
End
End
Else
Begin
--We are at the beginning of a word, and it is not state abbrv or 3-letter word
Set @OutputString = @OutputString + Upper(@char)
Set @IsStartOfWord = 0
End
End
Else
--Not beginning of a word, so send it to lower case
Begin
Set @OutputString = @OutputString + Lower(@Char)
End
End
End
Set @LastChar = @Char
Set @Index = @Index + 1
End
End
RETURN @OutputString
END Comments
The method makes a single pass through your string, so it is reasonably efficient in that regard. Of course, the slowest part of the function is determining whether a 3-letter word is an abbreviation or an English word. If speed is crucial, you can save all the words in a table and put an index on it. As I said above, it runs reasonably fast. When I tested it, it converted roughly 20,000 names in one second.
Usage
Because it is a function, you can use it in any query you use for moving data around. It works great when you have data from older sources that is all upper case. Naturally, my function is not perfect. One enhancement you could make would be to insert handling for 4-letter words, since I have seen some company names with 4-letter abbreviations.
T-SQL Cross Apply
Great for De-Normalized Tables!
SQL Server has a nice statement ‘Cross Apply’ that is super handy when working with old-fashioned, badly designed data. And I’m doing a lot of that now as we import legacy data into our new CRM.
Specifically, it helps when your old table has a lot of columns with the same data repeated over and over. Like
- Separate columns, in your table ‘People’, for PhoneNumber1, PhonwNumber2, PhoneNumber3
- Or Separate columns, in your table ’employees’, for Employee1, Employee2, Employee3, etc.
- In my case, separate columns for call and demand, named “Call01… Call25” and “Demand01…Demand25”
The data in these badly designed tables is not in the First Normal Form. I won’t talk about the problems with that here, but my task is to convert this data into normalized data. If I was working with phone numbers, I would want one row for each phone number. Similarly, I want one row for each Call-Demand pair.
Get Off Your Soapbox and Show me the Query Already!
The following query will return one row for each call/demand pair, as long as the value is non-zero.
Select Select Select leg.ItemId, v.ColNum, leg.Qty, v.Calls, v.Demands
From PCPPIST0
Cross Apply (Values (1, clmo01, dmmo01),
(2, Call02, Demand02),
(3, Call03, Demand03),
(4, Call04, Demand04),
(5, Call05, Demand05),
(6, Call06, Demand06),
(7, Call07, Demand07),
(8, Call08, Demand08),
(9, Call09, Demand09),
(10, Call10, Demand10),
(11, Call11, Demand11),
(12, Call12, Demand12),
(13, Call13, Demand13),
(14, Call14, Demand14),
(15, Call15, Demand15),
(16, Call16, Demand16),
(17, Call17, Demand17),
(18, Call18, Demand18),
(19, Call19, Demand19),
(20, Call20, Demand20),
(21, Call21, Demand21),
(22, Call22, Demand22),
(23, Call23, Demand23),
(24, Call24, Demand24),
(25, Call25, Demand25)
) as v (colNum, Calls, Demands)
Where Calls <> 0
And Demands <> 0The results look like the following:
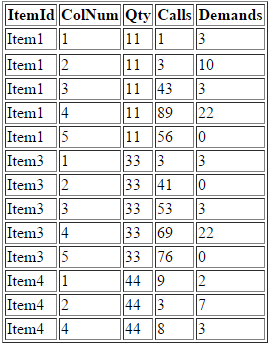
I created the query on SQL Fiddle so you can experiment with it: Link to SQLFiddle.
Basically, I took a really wide table and created a result-set with one row for each item and its calls and demands.
Dissecting the Query
“Values Clause” – Here you specify the column names that will become rows. You can specify as many column names as you like. In my example, I have one for each call/demand pair. I also hard-code a number as a value, different for each pair.
“Table Alias” – In my query, the phrase is ‘as v‘, where ‘v’ stands for the “virtual table” which is created from your columns.
“Column Aliases” – in my query above, they look like this:
(colNum, Calls, Demands)
this allows me to treat each column in my values clause by a common name. Thus, ‘Call01″ becomes “Call” and “Call25” also becomes “Call”. Same thing for the Demand column and and my ColNum.
What Would You do Without Cross Apply?
One alternative would be to use a big, honking Union, like the following:
Select ItemId, Quantity, Calls, Demands
From (
Select ItemId, Qty, clmo01 AS [Calls], dmmo01 AS Demands, 1 As ColNum FROM LegacyCallDemand where clmo01 <> 0 and dmmo01 <> 0 union all
Select ItemId, Qty, clmo02 AS [Calls], dmmo02 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo02 <> 0 and dmmo02 <> 0 union all
Select ItemId, Qty, clmo03 AS [Calls], dmmo03 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo03 <> 0 and dmmo03 <> 0 union all
Select ItemId, Qty, clmo04 AS [Calls], dmmo04 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo04 <> 0 and dmmo04 <> 0 union all
Select ItemId, Qty, clmo05 AS [Calls], dmmo05 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo05 <> 0 and dmmo05 <> 0 union all
Select ItemId, Qty, clmo06 AS [Calls], dmmo06 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo06 <> 0 and dmmo06 <> 0 union all
Select ItemId, Qty, clmo07 AS [Calls], dmmo07 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo07 <> 0 and dmmo07 <> 0 union all
Select ItemId, Qty, clmo08 AS [Calls], dmmo08 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo08 <> 0 and dmmo08 <> 0 union all
Select ItemId, Qty, clmo09 AS [Calls], dmmo09 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo09 <> 0 and dmmo09 <> 0 union all
Select ItemId, Qty, clmo10 AS [Calls], dmmo10 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo10 <> 0 and dmmo10 <> 0 union all
Select ItemId, Qty, clmo11 AS [Calls], dmmo11 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo11 <> 0 and dmmo11 <> 0 union all
Select ItemId, Qty, clmo12 AS [Calls], dmmo12 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo12 <> 0 and dmmo12 <> 0 union all
Select ItemId, Qty, clmo13 AS [Calls], dmmo13 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo13 <> 0 and dmmo13 <> 0 union all
Select ItemId, Qty, clmo14 AS [Calls], dmmo14 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo14 <> 0 and dmmo14 <> 0 union all
Select ItemId, Qty, clmo15 AS [Calls], dmmo15 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo15 <> 0 and dmmo15 <> 0 union all
Select ItemId, Qty, clmo16 AS [Calls], dmmo16 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo16 <> 0 and dmmo16 <> 0 union all
Select ItemId, Qty, clmo17 AS [Calls], dmmo17 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo17 <> 0 and dmmo17 <> 0 union all
Select ItemId, Qty, clmo18 AS [Calls], dmmo18 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo18 <> 0 and dmmo18 <> 0 union all
Select ItemId, Qty, clmo19 AS [Calls], dmmo19 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo19 <> 0 and dmmo19 <> 0 union all
Select ItemId, Qty, clmo20 AS [Calls], dmmo20 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo20 <> 0 and dmmo20 <> 0 union all
Select ItemId, Qty, clmo21 AS [Calls], dmmo21 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo21 <> 0 and dmmo21 <> 0 union all
Select ItemId, Qty, clmo22 AS [Calls], dmmo22 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo22 <> 0 and dmmo22 <> 0 union all
Select ItemId, Qty, clmo23 AS [Calls], dmmo23 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo23 <> 0 and dmmo23 <> 0 union all
Select ItemId, Qty, clmo24 AS [Calls], dmmo24 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo24 <> 0 and dmmo24 <> 0 union all
Select ItemId, Qty, clmo25 AS [Calls], dmmo26 AS Demands 2 As ColNum FROM LegacyCallDemand where clmo26 <> 0 and dmmo25 <> 0 union all
) as bigUnionAs you can see, the ‘Grand Union’ version is a lot more typing! Furthermore, it runs almost twice as slowly.
Related Technique
The SQL Server keyword ‘UnPivot’ is related to Cross Apply However, you can’t use Unpivot if you have more than one column to fix. In my case, I could have used UnPivot if I only wanted Calls or only wanted Demands. Since I need them both, Cross Apply is the technique to use.
Summary
Cross Apply works great when you are forced to work with denormalized data; it allows you to treat repeated columns as if they were in a separate related table. You could use a huge union statement to accomplish the same thing, but that is very lengthy and slower.
Enhance SQL Server With a CLR Function
Sometimes you can’t easily do what you need in T-SQL; fortunately you can create new functionality in a .NET project and invoke it from your stored procedures or SQL. You can build a Visual Studio project that you can publish to your SQL Server database and use like a normal function or stored proocedure.
In principal, it is not too hard to extend SQL Server, but there are several frustrating issues which I explain in the post below. You will save your own frustration if you learn from my efforts! For example, projects that won’t build but have no error messages, fixing apparent damage to Visual Studio, and explicitly turning-on CLR in SQL Server.
My Business Need: Enhanced String Comparison
I’m importing legacy data and discovered some data that should be identical but isn’t, due to similar punctuation marks! For example ASCII as at least three different single quote marks: a ‘straight’ single quote, an open single-quote and a close single-quote. Like the following:
‘`´
Also, there are a couple different ASCII hyphens: a normal version, and an extra-wide one. Presumably there are other punctuation marks that look similar to humans but aren’t the same to SQL Server
Names the Same Except for Punctuation
Normally I don’t care about the punctuation, but I have some key fields with different punctuation, such as:
- Joe’s Bar and Grill (straight quote)
- Joe´s Bar and Grill (close quote)
The problem arises when I try to prevent duplicates: the two names above are the same to me, but SQL Server says they are different, because of the differing punctuation.
At first, I thought I could avoid the issue by specifying a collate clause in my SQL, but that that is actually designed for comparisons in different languages and doesn’t help here.
.NET to the Rescue!
Fortunately, .NET has a CompareOptions object which allows you to compare strings with a ‘IgnoreSymbols’ setting. Not perfect, because it only ignores punctuation; it isn’t smart enough to compare the three kinds of single quotes against each other but not against other punctuation. However, I judged it good enough for my purposes. Now, I will use that capability to build a “SQL CLR C# User Defined Function in SQL SERVER”.
Start by creating a SQL Server Database Project
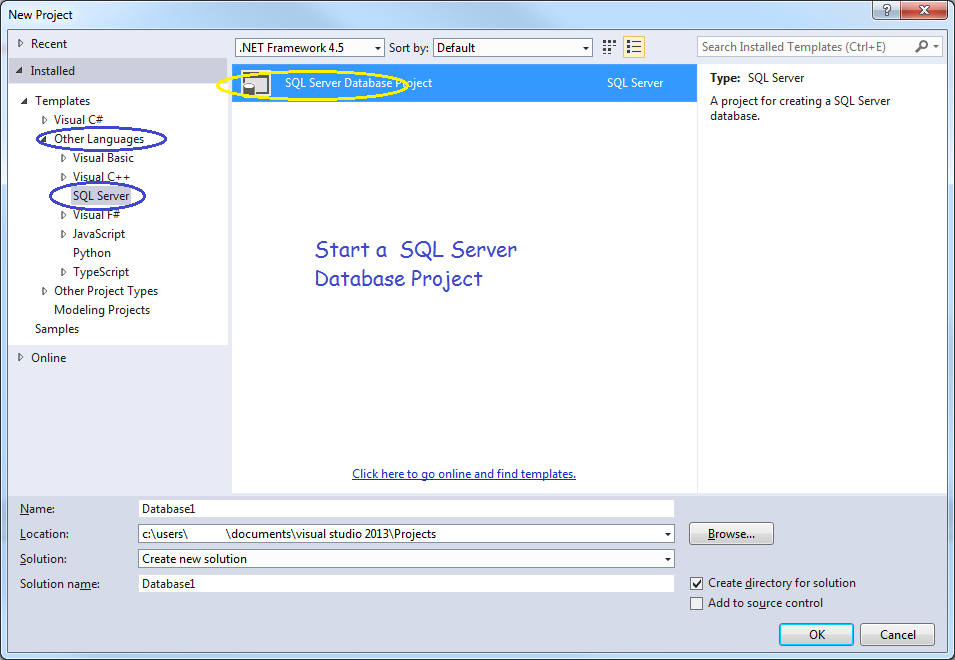
After starting your project, make sure you target the correct version of SQL Server, in my case, SQL Server 2012.
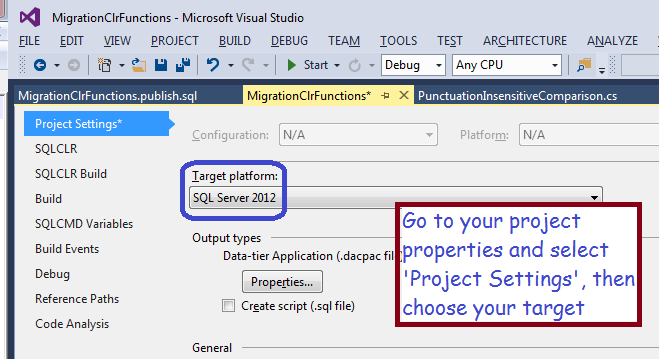
Now, choose the type of functionality you wish to add to SQL Server, in my case, a User-Defined Function. Add a new item to your project and choose the template indicated in the screen shot below.
Now, Write Some Code!
You will get a stub function; you should fill-in the functionality to meet your needs. In my case, I will return a 0 if two strings are equivalent, a -1 if the first string is smaller, and a 1 if the first string is bigger.
using System.Data.SqlTypes;
using System.Globalization;
using Microsoft.SqlServer.Server;
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction(DataAccess = DataAccessKind.None, IsDeterministic = true, SystemDataAccess = SystemDataAccessKind.None, IsPrecise = true)]
public static SqlInt16 PunctuationInsensitiveComparison(SqlString s1, SqlString s2)
{
try
{
if (s1.IsNull && s2.IsNull)
return 0;
else if (s1.IsNull)
return -1;
else if (s2.IsNull)
return 1;
else
{
CompareOptions myOpts = CompareOptions.IgnoreSymbols | CompareOptions.IgnoreWidth | CompareOptions.IgnoreCase | CompareOptions.IgnoreNonSpace;
CompareInfo ci = CompareInfo.GetCompareInfo("en-US");
SqlInt16 compareResult = (SqlInt16)ci.Compare((string)s1, (string)s2, myOpts);
return compareResult;
}
}
catch (System.Exception ex)
{
return -1;
}
}
Highlights
- The tag decorating the start of my function tells SQL Server what kind of usage to expect, I believe it is used for optimization
[Microsoft.SqlServer.Server.SqlFunction(DataAccess = DataAccessKind.None, IsDeterministic = true, SystemDataAccess = SystemDataAccessKind.None, IsPrecise = true)]
- Note the use of SQL Server data types, such as SqlString and SqlInt16. This is important for optimzation
- Also note that I took pains to check for nulls, for example:
else if (s1.IsNull)
- This will work when String.IsNullOrEmpty fails!
Avoid this Gotcha!
At this point, you can try to build, but, even though the syntax is correct, it failed for me. In fact, it failed without an error message! After some research, I discovered I needed to install SQL Server Database Tooling, which you can get at this url: https://msdn.microsoft.com/en-us/dn864412.
Next Problem
Installing this extension may mess-up your instance of Visual Studio, it certainly did mine! You may get an error ‘No exports were found that match the constraint contract name‘ After some research, I found the solution was to rename or delete the following folder:
- C:\Users\YourUserName\AppData\Local\Microsoft\VisualStudio\12.0\ComponentModelCache
Now Publish Your Solution
Right-click on your project and choose ‘Publish’ from the context menu.
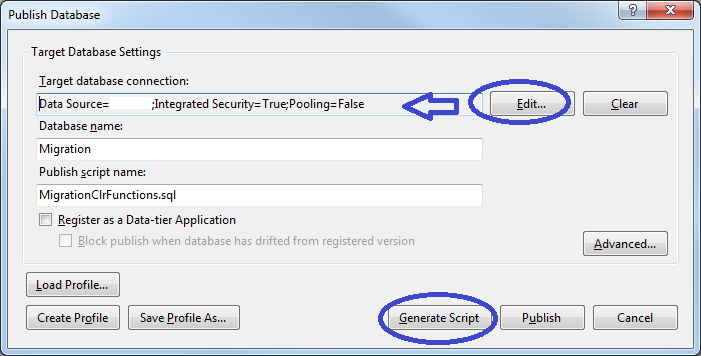
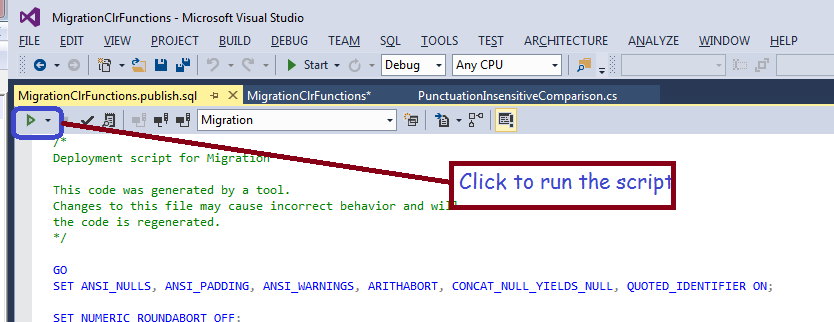
You will have to browse for your server/database by clicking the ‘edit’ button; afterwards, you can either generate a script or else click the publish button. If you generate a script, you can tweak it, afterwards you will need to run it by clicking the button indicated in the following screen shot.
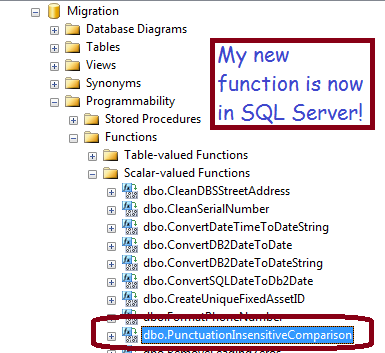
After publishing, your new function will appear in SQL Server!
One Last Step Before You Can Use it
The last thing to do is enable CLR functionality in your database instance, by running the following two commands:
sp_configure 'clr enabled', 1 Reconfigure
Now, you can use your new function in SQL, like the following simple example:
if dbo.PunctuationInsensitiveCompare('Jim''s Bar', 'Jim´s Br') = 0
Print 'Same'
Else
Print 'Different'
Microsoft documentation states that CLR functions can be more efficient than the equivalent in a normal Scalar-valued function, and my test confirmed that statement. However, if you aren’t careful about null checking, use the wrong data types, or generate errors, it can be much slower!
Summary
If you have a task that is hard in SQL but easy in .NET, you can build a CLR function and publish it to SQL Server. Things like string manipulation come to mind. You will build a SQL Server Database project, add an item ‘SQL CLR C# User-Defined Function’ and publish it to your database. There are several gotchas involved, so be careful and be sure to use System Restore Points and other backup techniques.
A Handy Query for SQL Server
Here is a nice query that you won’t find everywhere that could be rather useful
- A query to fix duplicates and clean-up your ‘look-up’ tables
Query: Clean-Up Your Duplicates!
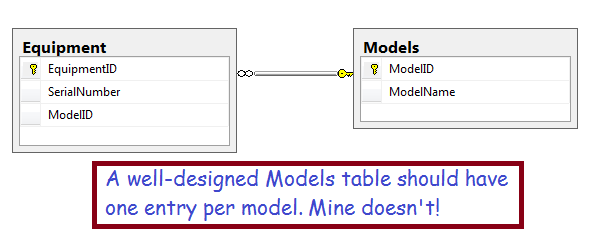
The diagram above illustrates the relationship between equipment and models. A well-designed Models table should have a unique-constraint on the ModelName column to prevent duplicates. My table doesn’t. This can happen if you get data from users who don’t understand the problems this can create!
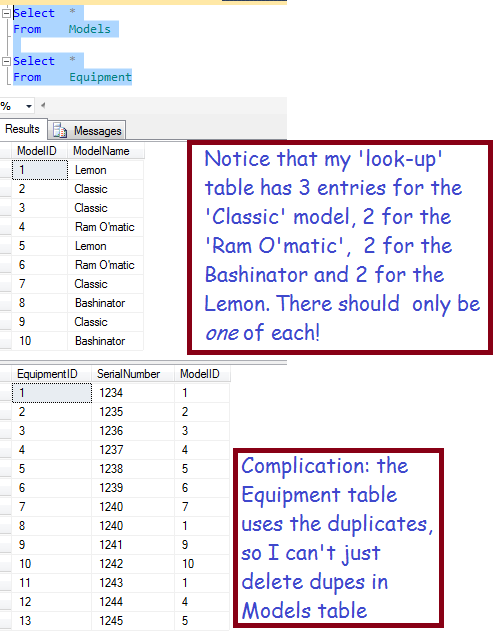
Here’s the Query!
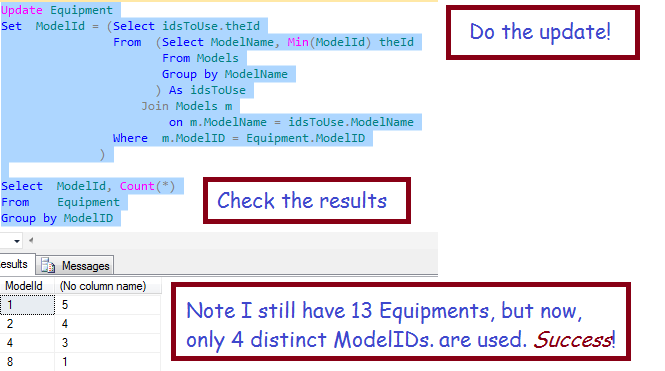
Update Equipment Set ModelId = (Select idsToUse.theId From (Select ModelName, Min(ModelId) theId From Models by ModelName ) idsToUse Join Models m on m.ModelName = idsToUse.ModelName Where m.ModelID = Equipment.ModelID )
Does that look like a bunch of impenetrable gobbledegook? Allow me to explain!
The following subquery (from above) is used to select the lowest model ID for each model name:
Select ModelName, Min(ModelId) theId From Models Group by ModelName
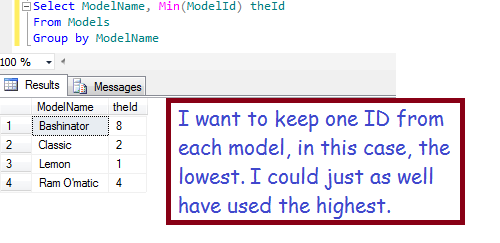
Notice that, in the main query, I convert the results of this subquery into a derived table, which I call ‘idsToUse’.
Having created a ‘derived table’ containing a list of IDs to use
- Join the derived table ‘idsToUse’ against Models on ModelName
- The result is a data set with every ModelID in use, associated with the ID we should use instead
- Now, select the good ID from the join results (in the where-clause)
- And use it to update the Equipment table, by matching against the ModelID from Equipment
- Resulting in every ModelId being replaced with the minimum
- Which is what we want!
The Last Step
At this point, we have fixed the Equipment table,
- Now, only one of each ModelId is in use
The easy part is deleting the duplicated model names form the Models table. We will delete every model ID except for the minimum of each group, with the following query:
Delete Models Where ModelId Not in (Select Min(ModelId) From Models Group by ModelName )
This query wouldn’t have worked unless we previously fixed the Equipment table, because referential integrity would have prevented us from making orphan records. It would have prevented deleting ModelIds that are in use in the Equipment table.
Summary
Cleaning-up your database is a good way to make sure you can generate good reports and keep your sanity. Cleaning-up duplicates is a tricky chore. Finding the dupes is not too hard, and my query showed how you can pick one ID from each repeated model name. Then I showed you how you can use those good IDs in a derived table, which you can then utilize as a way to look-up every model ID in the equipment table and map it to the correct ID to use.
