
Sunday Puzzle: Find a Word With a ‘T’ Pronounced as ‘ZH’
A tough one from listener Joe Becker, of Palo Alto, Calif. The “zh” sound can be spelled in many different ways in English — like the “s” in MEASURE; like the “g” in BEIGE; like the “z” in AZURE; like the “j” in MAHARAJAH; and like the “x” in LUXURY as some people pronounce it. The “zh” sound can also be spelled as a “t” in one instance. We know of only one common word this is true of, not counting its derivatives. What word is it?
Link to the challenge
Synopsis
Once again, a sweet easy one 😁. Easy because I happen to have the magic key to solving it: a phoneme dictionary! Carnegie Mellon University has released the CMU Pronunciation Dictionary. Because I have that dictionary, I solved it with just 49 lines of code. And most of those lines were infrastructure.
Definition
phoneme fō′nēm″ noun
- The smallest phonetic unit in a language that is capable of conveying a distinction in meaning, as the m of mat and the b of bat in English.
Their Dictionary is a File that Looks Like This
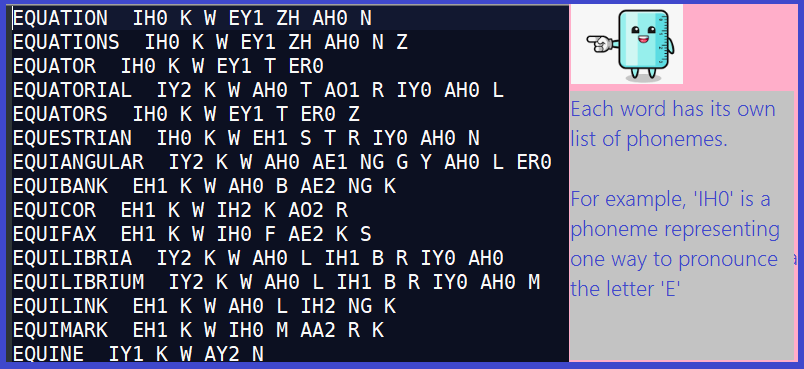
To solve the puzzle, we simply read this file and seek a word having a ‘ZH’ phoneme in the same position as a ‘T’ in the original word. Sounds simple? It basically is.

But there was a tricky part that I could only avoid because I got lucky. I’ll discuss it below!
While examining my code below, see if you can spot the assumption my code makes before I explain it.
I elected to use WPF (Windows Presentation Framework, a type of .NET solution) as the environment to solve the puzzle. Rationale: I need to process a file, so web solutions are out. WPF looks nice and .NET has a powerful set of string manipulation functions that I already know.

Techniques Used
- String manipulation
- File IO
- A tiny bit of Regular Expressions
Video Explaining the Code
Sometimes it’s more fun to watch a video than to read through code, so this time I made a video explaining it, here’s a link! It’s just 13 minutes long, and by watching, you may learn a couple tricks you can use in the debugger.
Here’s the Code!
Since the algorithm is so simple, I will just list my code. Note that numbered comments in the code correspond to explanations listed below.
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
txtResults.Clear();
// 1) Open the file for reading
using (var sr = File.OpenText(DICT_PATH)) {
string aLine = "";
// 2) Skip the top of the file, looking for a line
// which starts with a letter, which represents the file payload
while (sr.Peek() != -1) {
aLine = sr.ReadLine() ?? "";
if (aLine.Length > 0 && char.IsLetter(aLine[0]))
break;
}
while(true) {
// 3) Every word is separated from its phonemes by a double space
var p = aLine.IndexOf(" ");
if (p > 0) {
// 4) Every phoneme is separated by a space, build a list of them
var phonemes = aLine[(p + 2)..].Split(' ').ToList();
// 5) Find the index (if any) of the phoneme represented by 'ZH'
var zhPos = phonemes.IndexOf("ZH");
if (zhPos >= 0) {
// 6) Grab the word and strip off anything that looks lke '(2)'
var aWord = Regex.Replace(aLine[..p], @"\(\d\)", "");
// 7) Check if the index of 'T' is the same as the index of 'ZH'
if (zhPos < aWord.Length && aWord[zhPos] == 'T') {
txtResults.Text += $"Word: {aWord}, Phonemes: {aLine[(p + 2)..]}\n";
}
}
}
if (sr.Peek() == -1)
break;
aLine = sr.ReadLine() ?? "";
}
}
Mouse.OverrideCursor = null;
}
Comments Explained
- Open the file for reading. ‘DICT_PATH’ is a constant, defined above, holding the file path of the dictionary, such as “c:\cmudict.0.7a”. The variable
sris aStreamReaderthat can read a line of text. - Skip the top of the file, looking for a line which starts with a letter, which represents the file payload. Note that the first 121 lines of the file are comments and explanations, not part of the dictionary per se. Those lines start with a space or punctuation mark. Note that
aLine[0]represents the first character of the line (data typechar)- char.IsLetter is a built-in method that returns
truefor letters andfalseotherwise
- Every word is separated from its phonemes by a double space. For example, EQUATION IH0 K W EY1 ZH AH0 N. It might be hard to see, but there are two spaces after ‘EQUATION’. The variable
prepresents the position of the first space. Now we know where to find the end of the word, and the beginning of the phoneme list. - Every phoneme is separated by a space, build a list of them. There is a lot happening in this short line, let’s examine each carefully:
aLine[(p + 2)..]This code grabs a substring out of the original line, effectively the last half of the line, starting at the 2nd letter afterpand running to the end of the line. If the double space starts at position 10, then(p + 2), i.e. 12 is the starting position of everything after the double space.Split(' '). This built-in method builds an array out of the substring I gave it, splitting on the space character. Every time a space is encountered, we start a new entry in the array. If the input to split is “IH0 K W EY1 ZH AH0 N”, then the array will look like [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”]. Meaning that the first entry is “IH0” and the last is “N”.ToList(). This converts the array to a list. Why?ArraysandListsare very similar, but they don’t have the same methods available to them. In particular, I want to use the methodIndexOf, which is not available toarrays.
- Find the index (if any) of the phoneme represented by ‘ZH’. For our example array, [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”], the index will be 4, meaning we can access that entry with the line of code
phonemes[4]. If the list doesn’t have a ZH, then zhPos will be assigned -1. - Grab the word and strip off anything that looks lke ‘(2)’. Once again, there is a lot going on with this line:
aLine[..p]. Remember, p is the position where we found the double space. This code fragment grabs a substring starting at the beginning of the line, up to positionp.Regex.Replace. Regular expressions are a handy, but tricky, way to match patterns in strings. If you download and examine the CMU Phoneme dictionary, you will see some lines that look like the following:- ERNESTS ER1 N AH0 S T S
- ERNESTS(2) ER1 N AH0 S S
- ERNESTS(3) ER1 N AH0 S
- Note the two entries “(2)” and “(3)’. We want to replace these with an empty space, i.e., delete them.
Regex.Replacewill do that if we give it a string to start with, a pattern to match, and a replacement string (in our case, an empty string). @"\(\d\)"This is the pattern we will look for- @” means this string contains \ characters
\(represents an open parenthesis. Because ( is a specal character, we need to preface it with \ so that .NET will look for that character in the string, instead of starting a capture group. Capture groups are an advanced topic which we don’t need to understand today. There are a few special characters which we need to preface with \, so we can avoid confusion; the \ is called an escape character.\dThis is a pattern element signifying “capture any digit“, i.e., the characters 0-9- \) This represents the close parenthesis. As before, the backspace is used as an escape character.
- The upshot is that, if aLine contains “ERNESTS(2) ER1 N AH0 S S”, then
aWordwill be assigned “ERNESTS”, because we replaced (2) with “”
- Check if the index of ‘T’ is the same as the index of ‘ZH’. Note that, within the string ‘EQUATION’, ‘T’ has index 4 (remember, indexes start at 0, not at 1). Similarly, ‘ZH’ also has index 4 within the list [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”]. Since the index is 4 in both, we are pretty confident that T is pronounced ‘ZH’ in the word equation.

The Tricky Part Explained!
You’ve now read my code. Have you managed to guess what I meant when I said I got lucky?
Answer: My code assumes that every letter in the original word is represented by a phoneme. But that isn’t actually true. Sometimes a pair of letters are used to make a sound, like the pair “sh”, “th”, or “ch”. I don’t know how many letter pairs are used that way, but it makes things complicated when you try to determine whether the letter ‘T’ is represented by the phoneme ‘ZH’ by determining that both are at position 4.
Since I found a good solution without taking this issue into account, and since dealing with it makes my blog entry a lot harder to understand, and since the whole thing is just for fun, I elected not to deal with the issue. Once again, I leave it as an exercise to the reader.
Get the Code
You can get a copy of my code from my dropbox account at this link. Note that you will need to create a free DropBox account to do so. Use the link above to get the CMU phoneme dictionary, and remember to revise my code to point to the file path on your machine.
