
Month: March 2022
Sunday Puzzle for March 13, 2022
Manipulate Words from a Common Phrase Containing ‘in the’
This week’s challenge comes from Tyler Hinman, of San Francisco. He’s the reigning champion of the American Crossword Puzzle Tournament, which is coming up again on April 1-3. Think of two four-letter words that complete the phrase “_ in the _.” Move the first letter of the second word to the start of the first word. You’ll get two synonyms. What are they?
Link to the challenge

Discussion
The code to solve the puzzle was easy. Getting the list of phrases was tough! Eventually, I built up a list of over 10,000 common phrases and used it to solve the puzzle. Once again, I elected to use python.
Skills and Techniques to Solve
- File handling
- String manipulation
Again, the code is quite short, just 57 lines, including 16 comment lines

Code Discussion
For simplicity, I will show the key code, saving 3 things for later:
- Building a list of English words called ‘wordLst’
- Defining a method ‘GetPriorWord’
- Defining another method ‘GetNextWord’
Here is the important, key word, skipping the three items above:
fName = 'C:\\Users\\Randy\\Documents\\Puzzles\\Data\\CommonPhrases.txt'
fHandle = open(fName, 'rt', encoding="utf8")
# Read each line in the file (about 10,000) and process lines containing ' in the '
for aLine in fHandle:
p = aLine.find(' in the ')
if p > 0:
#Remove trailing linefeed
fixed = aLine.strip()
previous = GetPriorWord(fixed, p)
if len(previous) == 4:
next = GetNextWord(fixed, p)
if len(next) == 4:
#At this point, we know both words have length 4,
#now manipulate them according to the instructions:
candidate1 = next[0] + previous
candidate2 = next[1:]
#if both candidates are valid words, print the result:
if candidate1 in wordLst and candidate2 in wordLst:
print(fixed, ' → ', candidate1, candidate2)First, we open the file with this code:
fHandle = open(fName, 'rt', encoding="utf8").
- ‘rt’ means ‘read’ ‘text’
- encoding=”utf8″ means expect and handle non-standard letters, like à la carte
Next, we loop through the lines in the file, we look for a line containing ‘in the’
p = aLine.find(' in the ')variable ‘p’ is the position where we find that substring; if not found, p will be -1. Only about 20 phrases qualify. Next, we get the words immediately before and immediately after the position where we found ‘in the’:
previous = GetPriorWord(fixed, p)
if len(previous) == 4:
next = GetNextWord(fixed, p)
if len(next) == 4:As discussed above, I will explain ‘GetPriorWord’ and ‘GetNextWord’ below. For now, the code above creates two variables holding the words we want, named ‘previous’ and ‘next’. If both have length 4, we proceed:
#At this point, we know both words have length 4,
#now manipulate them according to the instructions:
candidate1 = next[0] + previous
candidate2 = next[1:]
#if both candidates are valid words, print the result:
if candidate1 in wordLst and candidate2 in wordLst:
print(fixed, ' → ', candidate1, candidate2)‘candidate1’ is built by concatenating the first letter of next with previous. ‘candidate2’ is every letter following the first. If both are in my list of words ‘wordLst’, then we have a solution. Note that only one phrase matches this, so I didn’t write code to determine whether they are synonyms.
The Three Parts I Skipped Over
Here’s how I built wordLst:
# First load a list of English words
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\2of12inf.txt"
fHandle = open(fName, 'rt')
wordLst = []
for aWord in fHandle:
wordLst.append(aWord.strip())Here are the definitions of my two methods ‘GetPriorWord’ and ‘GetNextWord’:
#When given a position p in a string 'aLine', finds the word preceeding it
def GetPriorWord(aLine, p):
i = p - 1
while i >= 0 and aLine[i] != ' ':
i -= 1
result = ''
if i < p:
result = aLine[i + 1:p - i - 1]
return result
#When given a position p in string 'aLine, finds the word succeeding it
def GetNextWord(aLine, p):
i = p + 8
while i < len(aLine) and aLine[i].isalpha():
i += 1
result = ''
if i > p + 8:
result = aLine[p + 8:i]
return resultDownload My Code
You can download my solution, plus the phrase file, from my Dropbox account. You will need to create a free account with Dropbox to do so.
Sunday Puzzle March 6, 2022
Find a Word That Ought to Start with a ‘Q’
This week’s challenge comes from listener Ward Hartenstein, of Rochester, N.Y. Words starting with a “kw-” sound usually start with the letters QU-, as in question, or “KW-,” as in Kwanzaa. What common, uncapitalized English word starting with a “kw-” sound contains none of the letters Q, U, K, or W?
Link to the challenge

Discussion
This is a simple puzzle if you have a list of words and their associated phonemes! You can download one here, though I have to admit I downloaded mine a very long time ago. Phonemes are a “unit of sound”, i.e. a standardized way of representing the sounds that make up a word.
The entries in the word/phoneme list look like these three samples:
- KWANZA K W AA1 N Z AH0
- QUICK K W IH1 K
- CHOIR K W AY1 ER0
Note that each word is followed by two spaces and then the phonemes that represent how that word is pronounced in North America. The main thing we care about is whether the word is followed by a K, and a W.
Skills and Techniques to Solve
Again, I elected to solve with Python, and the specific programming skills include:
- String processing
- File handling
The program is extremely short.
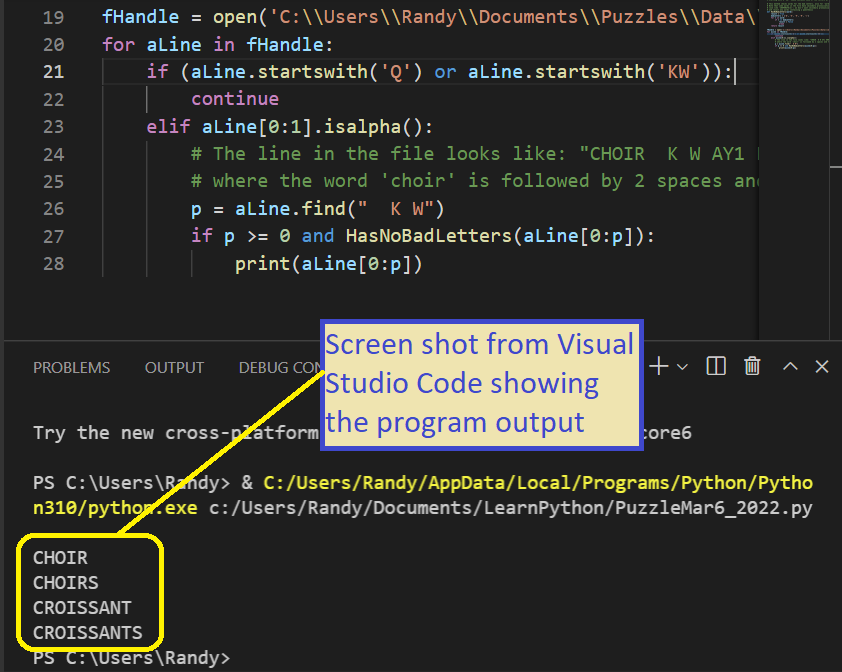
Here’s the Code
Since the program is so short, I’ll paste the whole 18 lines here:
def HasNoBadLetters(word):
result = True
badLetters = ['Q', 'U', 'K', 'W', '(']
for l in word:
if l in badLetters:
result = False
break
return result
fHandle = open('C:\\Users\\Randy\\Documents\\Puzzles\\Data\\cmudict.0.7a', 'rt')
for aLine in fHandle:
if (aLine.startswith('Q') or aLine.startswith('KW')):
continue
elif aLine[0:1].isalpha():
# The line in the file looks like: "CHOIR K W AY1 ER0"
# where the word 'choir' is followed by 2 spaces and then the phoneme list
p = aLine.find(" K W")
if p >= 0 and HasNoBadLetters(aLine[0:p]):
print(aLine[0:p])Code Discussion
My code listing starts by defining a short method called ‘HasNoBadLetters‘. As per the instructions, I use this method to exclude any word that has bad letters in it, namely, ‘Q’, ‘U‘, ‘K‘, ‘W’ and ‘(‘. If the input parameter, named ‘word‘, has none of these letters, we return True for our result. Otherwise, we return False. Note that I invoke this method in the second-to-last line above.
Note: Puzzle Master Will said to exclude 4 specific letters, but I exclude one more: the parenthesis. The reason for this is that some words in the file have secondary pronunciations, like the following:
- COOPERATE(2) K W AA1 P ER0 EY2 T
Apparently some weirdos pronounce it like ‘quooperate’!
Next, we open the file for reading as text (passing parameter ‘rt‘ to the open method). We loop through the lines in the file, reading each line into variable ‘aLine‘.
Next, we skip any words that start with Q or K, and also require that the first letter be alphabetic.
if (aLine.startswith('Q') or aLine.startswith('KW')):
continueThe ‘continue‘ keyword effectively means “go to the next line in our loop”.
The following line of code makes sure the first letter is not punctuation, numeric, spaces, or anything else:
elif aLine[0:1].isalpha():
Why check this? The reason for this is that the top of the phoneme file has a bunch of notes and explanation, while the remainder of the file is the word listing. All the notes/explanation lines start with a semicolon, parenthesis, or other punctuation.

Finally, having determined that the line we read from the file is a word followed by its phonemes, we test to see if it is pronounced like a word starting with “QU”, which means we look for 2 spaces followed by K W. The following three lines of code does that:
p = aLine.find(" K W")
if p >= 0 and HasNoBadLetters(aLine[0:p]):
print(aLine[0:p])The ‘find‘ method searches for a sub-string inside another string and returns the position where it was found; if not found, it returns -1.
Since the the word itself ends where “ K W” begins, we can extract it by using the notation aLine[0:p]; in other words, grab the text starting at position 0 and ending before position p.
As a side note, I didn’t realize “croissant” was pronounced with a KW sound, maybe I’m just a philistine?
No Download this Time – Too Short
If you want my code, just cut-and-paste it from the 18-line listing above. And run it yourself with the phoneme file which you can download from my link above.
NR Puzzle Feb 25, 2022
This week’s challenge comes from listener Alan Hochbaum, of Duluth, Ga. Name a famous actor — first and last names. Remove the last letter of each name. You’ll be left with an animal and an adjective that describes that animal, respectively. Who is the actor?
Link to Puzzle at NPR

Another easy puzzle, and again I elected to solve it using Python. Skills and techniques include:
- File processing
- String manipulation
- Simple Regular Expressions
- Binary search
- Loops and basic logic

Comments
I’m pretty confident in my code, and I have a lists of 16,000 actors, 5,000 adjectives, and 2,000 animals. But, I don’t have all the actors, animals and adjectives! So there could be other solutions that I missed, even though my code works satisfactorily. “Redd Foxx” is not a well known actor these days. Sorry if either is your favorite actor, but I’ve never heard of my other two actors, Cody Longo and Sean Whalen. So, come Sunday, I would not be surprised if Will says some other actor is the solution. But, as you can see, given my data, these three are legitimate solutions.

Strategy
- Load the animal file into a list. Note my file is alphabetically sorted
- Load the adjective file into another list
- Open the actor file and process each entry
- Split the name into separate words
- Using a regular expression expressing to control the separator character
- Split the name into separate words
- Take the first word – call it the first name,
- Take the last word – call it the actor’s last name
- Avoid any suffix, such as ‘Jr.’, ‘Sr.’, etc.
- Use a binary search to quickly search the animal and adjective lists
- If we get a hit for first and last names, print a candidate solution
- Take the last word – call it the actor’s last name
Here’s The Code
Step 1: Load the two Files
import re
# Open and load the animals file; note it is presorted
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\CommonAnimals.txt"
animals = []
# Note: file is already sorted
fHandle = open(fName, 'rt')
for aLine in fHandle:
animals.append(aLine.strip())
# Open and load the adjectives file, also presorted
adjectives = []
# This file is sorted too
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\Adjectives.txt"
fHandle = open(fName, 'rt')
for aLine in fHandle:
adjectives.append(aLine.strip())A couple notes:
- I use a double backslash \\ in the file path because a single backslash is used to designate special characters
- I invoke the ‘strip’ method primarily to remove the linefeed
Step 2: Define the Binary Search Method
def binary_search(list1, n):
low = 0
high = len(list1) - 1
mid = 0
while low <= high:
# Compute index for our next guess, the middle of high and low
mid = (high + low) >> 1
# Check if n is present at mid
if list1[mid] < n:
low = mid + 1
# If n is greater, compare to the right of mid
elif list1[mid] > n:
high = mid - 1
# If n is smaller, compared to the left of mid
else:
return mid
# element not found, return -1
return -1Notes
- Binary search is extremely fast (it runs in
O (log(n))time). Meaning that the search time is proportionate to the log of the list size. For example, if the list has a million entries, binary search would find an entry in an average 6 operations (because Log(1000000) = 6). Note that it works if the list is sorted. low, mid and highare indexes to the list. ‘mid‘ is the middle of the current search subsection.- We examine the element at position
mid- If it matches our target ‘n’, we found it
- But if it is smaller, recompute high (which then causes mid to be recomputed)
- Alternatively, if it is higher, recompute low (which also causes mid to be recomputed next guess)
- Bit-shift for even more speed: the following is the faster version of division by 2:
mid = (high + low) >> 1
- It does this by shifting the bits to the right one position. I do this for a minor increase in speed; note that division is by far the slowest arithmetic operator
Step 3: Process the Actor File
# Use this list to make sure we get the correct surname
suffixes = ['Jr', 'Sr', 'II', 'III']
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\Actors\\Actors.txt"
# The file has some non-standard letters, so open with utf-8
fHandle = open(fName, 'rt', encoding="utf8")
for aLine in fHandle:
# By splitting the name, we can get each name part as
# a separate entry in the list 'tokens':
tokens = re.split(r'[ ,.]', aLine.strip())
first = tokens[0][:-1]
last = ''
lastIndex = len(tokens) - 1
if tokens[lastIndex] in suffixes and lastIndex >= 2:
last = tokens[lastIndex -1][:-1]
elif lastIndex >= 1:
last = tokens[lastIndex][:-1]
# At this point, the first and last names have been stripped of
# their last characters. Some names might not work
# because they have length 1,
# such as the actor 'X Brands' or 'A.J. Trauth',
# so skip over empty first/last names
if last != '' and first != '':
# see if first name starts corresponds to an animal
aniIndex = binary_search(animals, first)
# -1 means no match; so now let's see
# if first name works with adjectives:
if aniIndex == -1:
adjIndex = binary_search(adjectives, first.lower())
if adjIndex != -1:
aniIndex = binary_search(animals, last)
if aniIndex != -1:
print(aLine.strip(), '-->', adjectives[adjIndex], animals[aniIndex].lower())
else:
# First name is an animal; try last name for adjectives
adjIndex = binary_search(adjectives, last.lower())
if adjIndex >= 0:
print(aLine.strip(), '-->', adjectives[adjIndex], animals[aniIndex].lower())
Comments
- I use a regular expression to split the actor name into a list of separate strings
tokens = re.split(r'[ ,.]', aLine.strip())
- For example, “William Collier, Jr.”
- Becomes [“William”, “Collier”, “Jr”], i.e. a list of 3 strings
- The separator characters (delimiters) are space, comma and period, specified here:
r'[ ,.]'
- The first name is at position 0 of the list, the first element
- The following line of code creates a variable ‘first’ by removing the last character from the first element:
first = tokens[0][:-1]- Using string slicing
- Usually, the last string in my list is the actor’s surname, but sometimes they have a suffix like “Sr.”
- The following code tests if the last string is such a suffix:
if tokens[lastIndex] in suffixes and lastIndex >= 2:
- After assigning the first and last name, we use those variables to perform a binary search
- If
firstis an adjective and last is ananimal, print a solution - Or, if
lastis an adjective andfirstis an animal, print
Download the Code
You can download my code and data files here. Note that you will be required to create a free DropBox account to do so.
