
Puzzle Solving!
Sunday Puzzle: Find a Word With a ‘T’ Pronounced as ‘ZH’
A tough one from listener Joe Becker, of Palo Alto, Calif. The “zh” sound can be spelled in many different ways in English — like the “s” in MEASURE; like the “g” in BEIGE; like the “z” in AZURE; like the “j” in MAHARAJAH; and like the “x” in LUXURY as some people pronounce it. The “zh” sound can also be spelled as a “t” in one instance. We know of only one common word this is true of, not counting its derivatives. What word is it?
Link to the challenge
Synopsis
Once again, a sweet easy one 😁. Easy because I happen to have the magic key to solving it: a phoneme dictionary! Carnegie Mellon University has released the CMU Pronunciation Dictionary. Because I have that dictionary, I solved it with just 49 lines of code. And most of those lines were infrastructure.
Definition
phoneme fō′nēm″ noun
- The smallest phonetic unit in a language that is capable of conveying a distinction in meaning, as the m of mat and the b of bat in English.
Their Dictionary is a File that Looks Like This
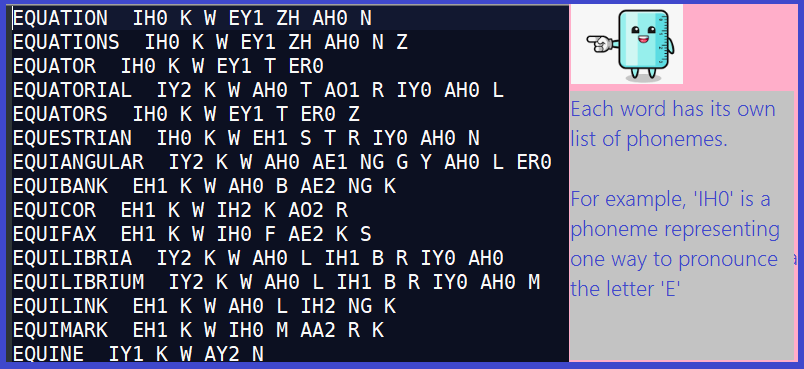
To solve the puzzle, we simply read this file and seek a word having a ‘ZH’ phoneme in the same position as a ‘T’ in the original word. Sounds simple? It basically is.

But there was a tricky part that I could only avoid because I got lucky. I’ll discuss it below!
While examining my code below, see if you can spot the assumption my code makes before I explain it.
I elected to use WPF (Windows Presentation Framework, a type of .NET solution) as the environment to solve the puzzle. Rationale: I need to process a file, so web solutions are out. WPF looks nice and .NET has a powerful set of string manipulation functions that I already know.

Techniques Used
- String manipulation
- File IO
- A tiny bit of Regular Expressions
Video Explaining the Code
Sometimes it’s more fun to watch a video than to read through code, so this time I made a video explaining it, here’s a link! It’s just 13 minutes long, and by watching, you may learn a couple tricks you can use in the debugger.
Here’s the Code!
Since the algorithm is so simple, I will just list my code. Note that numbered comments in the code correspond to explanations listed below.
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
txtResults.Clear();
// 1) Open the file for reading
using (var sr = File.OpenText(DICT_PATH)) {
string aLine = "";
// 2) Skip the top of the file, looking for a line
// which starts with a letter, which represents the file payload
while (sr.Peek() != -1) {
aLine = sr.ReadLine() ?? "";
if (aLine.Length > 0 && char.IsLetter(aLine[0]))
break;
}
while(true) {
// 3) Every word is separated from its phonemes by a double space
var p = aLine.IndexOf(" ");
if (p > 0) {
// 4) Every phoneme is separated by a space, build a list of them
var phonemes = aLine[(p + 2)..].Split(' ').ToList();
// 5) Find the index (if any) of the phoneme represented by 'ZH'
var zhPos = phonemes.IndexOf("ZH");
if (zhPos >= 0) {
// 6) Grab the word and strip off anything that looks lke '(2)'
var aWord = Regex.Replace(aLine[..p], @"\(\d\)", "");
// 7) Check if the index of 'T' is the same as the index of 'ZH'
if (zhPos < aWord.Length && aWord[zhPos] == 'T') {
txtResults.Text += $"Word: {aWord}, Phonemes: {aLine[(p + 2)..]}\n";
}
}
}
if (sr.Peek() == -1)
break;
aLine = sr.ReadLine() ?? "";
}
}
Mouse.OverrideCursor = null;
}
Comments Explained
- Open the file for reading. ‘DICT_PATH’ is a constant, defined above, holding the file path of the dictionary, such as “c:\cmudict.0.7a”. The variable
sris aStreamReaderthat can read a line of text. - Skip the top of the file, looking for a line which starts with a letter, which represents the file payload. Note that the first 121 lines of the file are comments and explanations, not part of the dictionary per se. Those lines start with a space or punctuation mark. Note that
aLine[0]represents the first character of the line (data typechar)- char.IsLetter is a built-in method that returns
truefor letters andfalseotherwise
- Every word is separated from its phonemes by a double space. For example, EQUATION IH0 K W EY1 ZH AH0 N. It might be hard to see, but there are two spaces after ‘EQUATION’. The variable
prepresents the position of the first space. Now we know where to find the end of the word, and the beginning of the phoneme list. - Every phoneme is separated by a space, build a list of them. There is a lot happening in this short line, let’s examine each carefully:
aLine[(p + 2)..]This code grabs a substring out of the original line, effectively the last half of the line, starting at the 2nd letter afterpand running to the end of the line. If the double space starts at position 10, then(p + 2), i.e. 12 is the starting position of everything after the double space.Split(' '). This built-in method builds an array out of the substring I gave it, splitting on the space character. Every time a space is encountered, we start a new entry in the array. If the input to split is “IH0 K W EY1 ZH AH0 N”, then the array will look like [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”]. Meaning that the first entry is “IH0” and the last is “N”.ToList(). This converts the array to a list. Why?ArraysandListsare very similar, but they don’t have the same methods available to them. In particular, I want to use the methodIndexOf, which is not available toarrays.
- Find the index (if any) of the phoneme represented by ‘ZH’. For our example array, [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”], the index will be 4, meaning we can access that entry with the line of code
phonemes[4]. If the list doesn’t have a ZH, then zhPos will be assigned -1. - Grab the word and strip off anything that looks lke ‘(2)’. Once again, there is a lot going on with this line:
aLine[..p]. Remember, p is the position where we found the double space. This code fragment grabs a substring starting at the beginning of the line, up to positionp.Regex.Replace. Regular expressions are a handy, but tricky, way to match patterns in strings. If you download and examine the CMU Phoneme dictionary, you will see some lines that look like the following:- ERNESTS ER1 N AH0 S T S
- ERNESTS(2) ER1 N AH0 S S
- ERNESTS(3) ER1 N AH0 S
- Note the two entries “(2)” and “(3)’. We want to replace these with an empty space, i.e., delete them.
Regex.Replacewill do that if we give it a string to start with, a pattern to match, and a replacement string (in our case, an empty string). @"\(\d\)"This is the pattern we will look for- @” means this string contains \ characters
\(represents an open parenthesis. Because ( is a specal character, we need to preface it with \ so that .NET will look for that character in the string, instead of starting a capture group. Capture groups are an advanced topic which we don’t need to understand today. There are a few special characters which we need to preface with \, so we can avoid confusion; the \ is called an escape character.\dThis is a pattern element signifying “capture any digit“, i.e., the characters 0-9- \) This represents the close parenthesis. As before, the backspace is used as an escape character.
- The upshot is that, if aLine contains “ERNESTS(2) ER1 N AH0 S S”, then
aWordwill be assigned “ERNESTS”, because we replaced (2) with “”
- Check if the index of ‘T’ is the same as the index of ‘ZH’. Note that, within the string ‘EQUATION’, ‘T’ has index 4 (remember, indexes start at 0, not at 1). Similarly, ‘ZH’ also has index 4 within the list [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”]. Since the index is 4 in both, we are pretty confident that T is pronounced ‘ZH’ in the word equation.

The Tricky Part Explained!
You’ve now read my code. Have you managed to guess what I meant when I said I got lucky?
Answer: My code assumes that every letter in the original word is represented by a phoneme. But that isn’t actually true. Sometimes a pair of letters are used to make a sound, like the pair “sh”, “th”, or “ch”. I don’t know how many letter pairs are used that way, but it makes things complicated when you try to determine whether the letter ‘T’ is represented by the phoneme ‘ZH’ by determining that both are at position 4.
Since I found a good solution without taking this issue into account, and since dealing with it makes my blog entry a lot harder to understand, and since the whole thing is just for fun, I elected not to deal with the issue. Once again, I leave it as an exercise to the reader.
Get the Code
You can get a copy of my code from my dropbox account at this link. Note that you will need to create a free DropBox account to do so. Use the link above to get the CMU phoneme dictionary, and remember to revise my code to point to the file path on your machine.
Sunday Puzzle: Nationality, Demonyms and Consonyms!
This week’s challenge is a spinoff of my (e.g. Will’s) on-air puzzle. Name two countries that have consonyms that are nationalities of other countries. In each case, the consonants in the name of the country are the same consonants in the same order as those in the nationality of another country. No extra consonants can appear in either name. The letter Y isn’t used.
Link to the Challenge
Definition Demonym; noun: A name for an inhabitant or native of a specific place that is derived from the name of the place.
Synopsis
Well, that was a nice, easy, fun one! Happily, I already had a list of nations and their demonyms, so it was just a matter of making two lists and matching them against each other. Each of those two lists contains the original word plus its consonym. One list uses the country as the original word, the other uses nationality as the original word. We match the lists using the consonym.
I elected to use WPF once again, mainly because it produces a nice UI and I am pretty fast in it. The choice of UI is fairly unimportant for solving this puzzle, since there is almost no interaction with the user, other than clicking the Solve button.
If you read through to the end, I’ll explain my big learning moment writing this code. Yes, I made a big mistake because I misunderstood something tricky about Linq. Hopefully you can save time by learning from my goof!
In case anyone is following me, I hope I don’t sound too over-confident in my analysis, possibly discouraging you. I always do the write-up as if I knew what I was doing from the very start, as if solving the puzzle is inevitable due to my great skill 😏. But that is not the case at all! I have a lot of struggles and plenty of dead ends. So I hope you don’t feel unworthy if I accidentally make it sound easier than it truly is. Because in reality, it only seems easy after I finally succeed.
Screenshot Showing My Results:
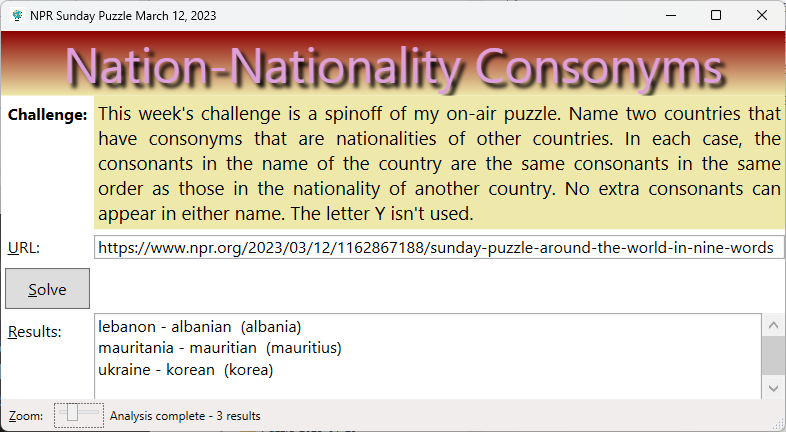
I got 3 results, but from Will’s description, I think he expects two results. I re-read his description a few times and don’t see anything I misinterpreted, so let’s see what he says come Sunday. Maybe there was some confusion over Mauritania and Mauritius, two very similar names.
Techniques Used
Difficulty Level
- Intermediate
- Dogged beginners
Algorithm
We start with a file that looks like the following (you can download your own copy below):
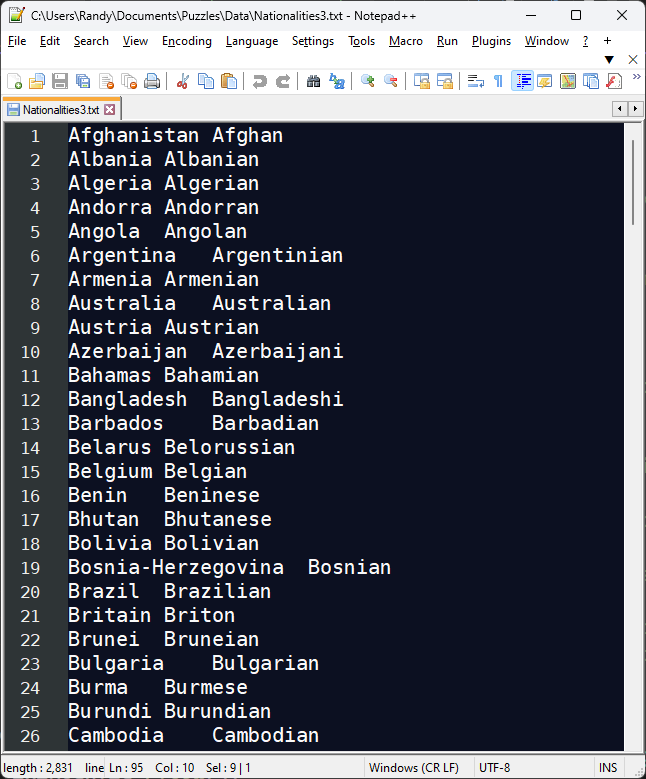
As you can see above, this file has two columns, separated by a tab character. The country comes first, followed by the demonym. Given this file structure, we take the following steps to find a solution:
- Open the file for reading
- Read one line at a time
- Split the line on the tab character, effectively separating the two words
- Build two lists,
- Using the two words from the line we just split
- One list for nationalities
- The other for demonyms
- Each list will contain a data type (a class in this case) which contains the original word and its consonym (refer to the image below)
- After we finish reading the file and building the list,
- Match the two lists using the consonym field
- Note that some countries will match against their own demonym, for example
- Britain → brtn → Briton (consonants “brtn” for both)
- Therefore, when we match the two lists, we need to avoid self-matching by requiring that the matched demonym not come from the original country
Illustration of Matching the Two Lists
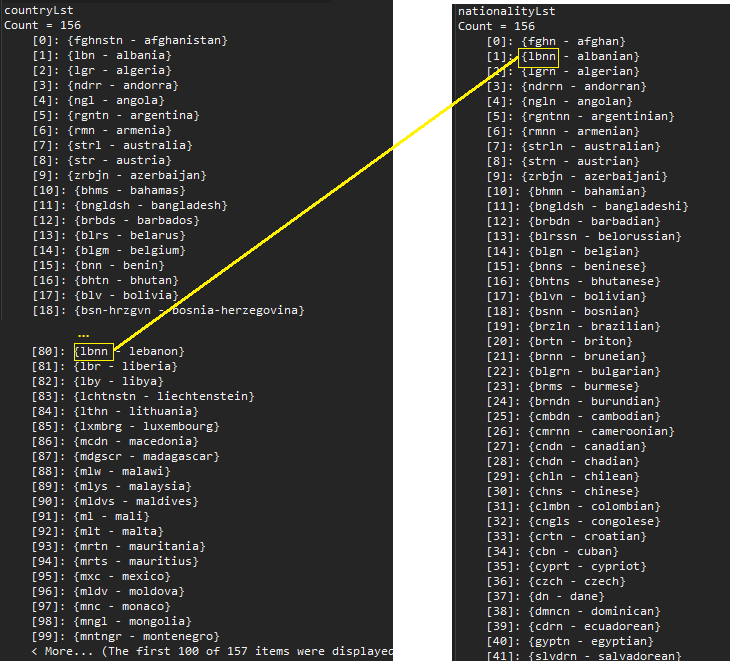
ConsonymWordPair , which consists of the consonants plus the original word. When we match entries on the left against those on the right, we find a match for “lbnn” in both lists. Now we know the two original words share a consonym, one word being a country and the other a nationality. Here’s The Code!
//This is the main method; it runs when user clicks the 'solve' button
private void btnSolve_Click(object sender, RoutedEventArgs e) {
txtResults.Clear();
txtMessage.Text = "";
//1) The subroutine (method) reads my file and builds the two lists:
var (countryLst, nationalityLst) = BuildCountryNationalityLists();
var solutionCount = 0;
//2) Loop through the country list and match against the nationality list
foreach (var c in countryLst) {
//3) Get all the nationalities whose Consonym matches the country's
var matches = nationalityLst.Where(n => n.Consonym == c.Consonym);
foreach (var m in matches) {
//4) 'Mate' is my term for the original country
//I call it 'Mate' to make the class name more generic
//If the country's consonym is the same as its nationalit's, skip it
if (m.Mate != c.Mate) {
//5) Display the results!
txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n";
solutionCount++;
}
}
}
txtMessage.Text = $"Analysis complete - {solutionCount} results";
}
Discussion – Main Method
🙆🏻I really like how short the main method is, it makes me feel good to write concise code that does something useful and, hopefully, something cool!
Numbered notes below correspond to the numbered comments above. If you already understand the code above, skip ahead to the next heading!
- The subroutine reads my file and builds the two lists
var (countryLst, nationalityLst) = BuildCountryNationalityLists();- That subroutine (‘
BuildCountryNationalityLists‘) is listed below - Note that this method returns two variables,
countryLstnationalityLst
- Which is one of my favorite features of .NET!
- Both lists contains
ConsonymWordPairelements (a class defined below)
- Loop through the country list and match against the nationality list
foreach (var c in countryLst) {- The variable ‘
c‘ is an instance of my class ‘ConsonymWordPair‘ - And we will examine all 156 of them, one per loop pass
- Get all the nationalities whose Consonym matches the country’s
- The Linq method
Wheredoes a search on the listnationalityLstvar matches = nationalityLst.Where(n => n.Consonym == c.Consonym);n.Consonymrefers to the nationality consonym- c
.Consonymrefers to the demonym consonym (say that 3 times fast!)
- And returns all the matches.
- Theoretically there could be more than one match, but not with this data
- The Linq method
- ‘Mate’ is my term for the original country
-
if (m.Mate != c.Mate) { - The class is named ‘
ConsonymWordPair‘, but I added an extra field ‘Mate'after naming it - So it isn’t really a pair any more 😑- whoops!
- The if-statement,
if (m.Mate != c.Mate)ensures that I don’t accidentally match, for example, Briton against Britain
-
- Display the results!
txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n";- That code appends a new solution to the textbox called ‘
txtResults‘ - The
+=operator causes the new string to be appended to the existing one - We build a string to append using the
$""nomenclature - This allows us to mix variables with text in a more natural way
- Variables are recognized inside the
{}brackets; everything else is plain text - Note that
\n(look at the end of the line) is how we specify a newline
Method ‘BuildCountryNationalityLists’
private (List<ConsonymWordPair>, List<ConsonymWordPair>) BuildCountryNationalityLists() {
//1) Build the two empty lists which we will populate and return:
var countryLst = new List<ConsonymWordPair>();
var nationalityLst = new List<ConsonymWordPair>();
//2) NATIONALITY_FILE is defined at the class-level; it is the file name
using var sr = File.OpenText(NATIONALITY_FILE);
//3) Read until end-of-file detected
while (sr.Peek() != -1) {
//4 Read the line, convert to lower case, split on tab character
//The split operation means that 'twain' is an array
var twain = sr.ReadLine().ToLower().Split('\t');
if (twain != null && twain.Length == 2) {
//5) twain[0] is the country name; build a pair with the
//word and its consonants
var c1 = RemoveVowels(twain[0]);
var cwp1 = new ConsonymWordPair(twain[0], c1, twain[0]);
countryLst.Add(cwp1);
//6) Now do the same for the nationality, which is in twain[1]:
var c2 = RemoveVowels(twain[1]);
var cwp2 = new ConsonymWordPair(twain[1], c2, twain[0]);
nationalityLst.Add(cwp2);
}
}
return (countryLst, nationalityLst);
}Discussion – BuildCountryNationalityLists
The method reads the file and builds two lists. As above, the list numbers below correspond to numbered comments above. The string operators used are ToLower and Split. The three File IO operators are File.OpenText, StreamReader.Peek and StreamRead.ReadLine. By putting this code in a separate method, the main method is simplified and easier to read.
- Build the two empty lists which we will populate and return
- Each list contains an instance of my class ‘
ConsonymWordPair‘
- Each list contains an instance of my class ‘
- NATIONALITY_FILE is defined at the class-level; it is the file name
- The variable
sris a StreamReader that can read a line at a time - The ‘
using‘ keyword guarantees that the stream will be closed and disposed
- The variable
- Read until end-of-file detected
- The StreamReader has a
Peekmethod that returns -1 whenEOFis detected, that terminates mywhile-loop
- The StreamReader has a
- Read the line, convert to lower case, split on tab character. The split operation means that ‘twain’ is an array
- I’m doing 3 things in this line:
var twain = sr.ReadLine().ToLower().Split('\t');
ReadLineshould be obviousToLowerconverts to lower case, so that I won’t try comparing ‘Lbnn’ against ‘lbnn’, because those two strings are not equal!- Split does what it says → it finds the tab character (\t) and splits the line every time it finds it
- The result is an array with two elements:
- Element 0: the country name (everything to the left of the tab)
- Element 1: And the nationality (everything to the right of the tab
- I’m doing 3 things in this line:
- twain[0] is the country name; build a pair with the word and its consonants
- The code below invokes my method
RemoveVowels, passing twain[i] as the inputvar c1 = RemoveVowels(twain[0]);
- For example, if the line was ‘Albania Albanian’
- Then twain[0] is ‘albania’ (note the lowercase ‘a’)
- The output from invoking
RemoveVowelsis ‘lbn’
- The code below invokes my method
- Now do the same for the nationality, which is in twain[1]:
- Following the example above,
twain[1]will be ‘albanian’ - The output from invoking RemoveVowels is ‘lbnn’
- Following the example above,
RemoveVowels Method
This method is really simple, so I won’t bore you with any unnecessary explanation. Here’s the code!
private string RemoveVowels(string input) {
//StringBuilder is easy to use and a more memory-efficient way to build a string
var result = new StringBuilder();
//Declare and initialize the array of char
var vowels = new[] { 'a', 'e', 'i', 'o', 'u' };
//Examine each char in the input string
foreach (var c in input)
if (!vowels.Contains(c))
result.Append(c);
return result.ToString();
}Class ‘ConsonymWordPair’
internal class ConsonymWordPair {
//1) My three public properties, the most important part of the class
public string Consonym { get; set; }
public string Word { get; set; }
public string Mate { get; set; }
//2) Default constructor
public ConsonymWordPair() {
Consonym = Word = Mate = "";
}
//3) 3-parameter constructor
public ConsonymWordPair(string newWord, string newConsonym, string newMate) : this() {
Word = newWord;
Consonym = newConsonym;
Mate = newMate;
}
public override string ToString() {
var result = $"{Consonym} - {Word}";
return result;
}
}Discussion – ConsonymWordPair
- My three public properties, the most important part of the class
- The remainder of the class is practically fluff
- As mentioned before, “pair” is not quite accurate any more, but “tuple” is harder to understand
- Default constructor
- Ensures that the public properties are initialized
- 3-parameter constructor
- The constructor used by the caller. Note that it actually invokes the default constructor with the code “
: this()“ - A pattern I try to follow which ensures the code in the default constructor is only written once
- The constructor used by the caller. Note that it actually invokes the default constructor with the code “
One other thing, the ToString method is not invoked when I solve the puzzle – so why did I write it? The answer is that Visual Studio uses it to display the list contents during debug sessions. When I hover my mouse over the pertinent variable (a list), it displays the contents using my method. Note that I built the image above (showing how the two lists are matched against each other) using the Immediate Pane in a debug session. Again, Visual Studio utilized my ToString method to display the data in that pane for me. Kind of the opposite of “immediate pain” 😉.
Lessons Learned
🙎🏼I made one big booboo writing this code: I used .NET’s Except method instead of my current method RemoveVowels. It didn’t work and I was surprised 😒! Except doesn’t work the way I thought it does, and I’ve been using it for years. I sure hope I didn’t create any bugs in production because of this.
Here’s some sample bad code that illustrates how I attempted to use Except:
var vowels = new[] { 'a', 'e', 'i', 'o', 'u' };
var twain = new[] {"albania", "albanian"};
var c1 = twain[0].Except(vowels).Aggregate("", (p,c) => p + c);
Console.WriteLine(c1);
var c2 = twain[1].Except(vowels).Aggregate("", (p,c) => p + c);
Console.WriteLine(c2);Can you guess what the output is for c2? I’ll keep you in suspense while I explain my code.
- Note that
twain[0]contains the string “albania” - When I invoke
Excepton it, passingvowelsas the input parameter, I get anIEnumerable<char>as the output (something like a list) that looks like the following:- ‘l’
- ‘b’
- ‘n’
- In other words, I get everything except the vowels. Just what we all expected.
- The code fragment
.Aggregate("", (p,c) => p + c)serves to create a string from the IEnumerable; basically it iterates the char elements and uses the+operator to concatenate them into a string
OK, now that I’ve explained how c1 is created, what do you think the value of c2 is? The code is the same for both, except the input for creating c2 is “albanian”. To my surprise, c1 is “lbn”. I expected “lbnn”, i.e. two n’s. .NET dropped one of my n’s.
What happened? Except works on IEnumerables, and I gave it a string, which .NET treated like a list of char. So far, so good. Reading the documentation, it doesn’t say anything about applying the Distinct operator, so all I can guess is that, under set operations, no one cares about preserving duplicates. Yes, I studied Set Theory in college, and I don’t remember anything like that, but it does seem somewhat consistent with how we did things then. So I don’t really know why it behaves that way, but now you know what to expect!
Efficiency Analysis
OK, my data file is only 156 lines long, and the code runs in just 7 milliseconds (according to .NET when running in debug mode, see below).
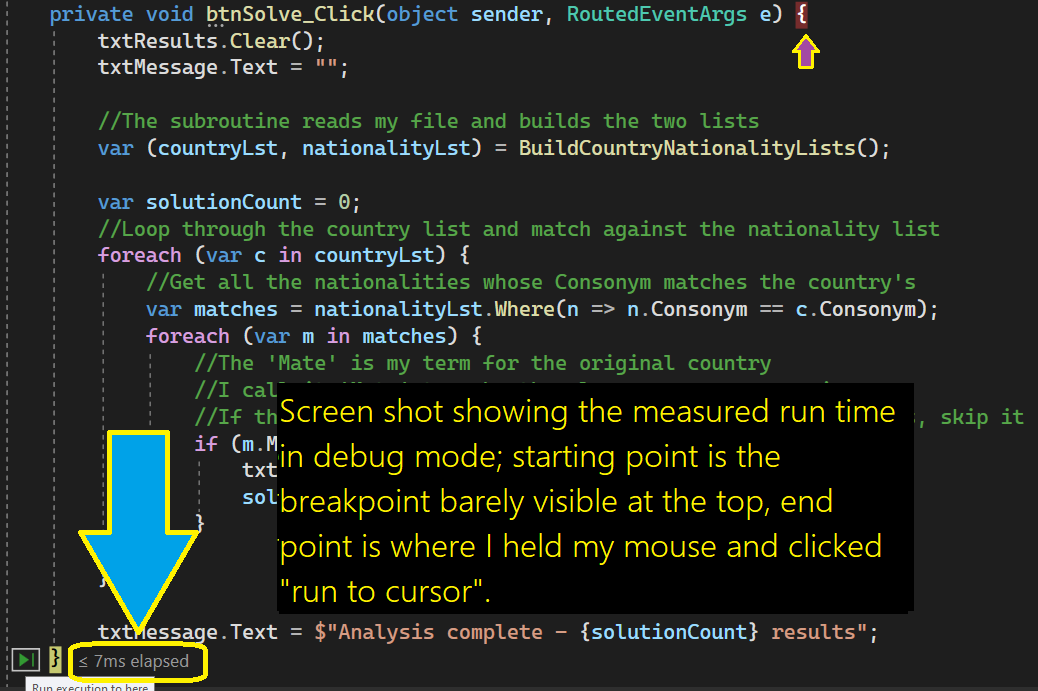
So, I must admit that we don’t care much about whether this code runs in 7 milliseconds, or 500 milliseconds – you’ve already burned thousands of milliseconds reading this😊 But it’s always good to understand the performance of your code, for one reason, it’s interesting!
The algorithm I used runs in O(n2), meaning that it first runs through the main list (the countries) and, for each pass through that list, makes another pass through the other list (nationalities), searching for a match. In this type of analysis, we ignore the fact that the 2nd search/array pass completes in an average of just half the array size; instead we focus on limiting behavior.
For our calculations, each pass in the first list means a pass through the second, so if the first array has length n, then the algorithm runs in n × n passes, or n2.
How to Improve Performance
I could have improved my performance by storing nationalities in a dictionary instead of a list. Note that .NET dictionaries use hashing instead of what I used, namely, a linear search. Hashing is much more efficient because we can determine whether some nationality exists in our dictionary in just O(1) run time, basically one calculation instead of examining the whole list. O(1) is generally the fastest possible run time.
By using a dictionary, my algorithm could have had a run time of O(n). Maybe that would shave a whole millisecond off my run time! I leave it as an exercise for the reader to make those sweet changes. Realistically, the bottleneck for this app is the file I/O, which typically runs 1000 times slower than memory calculations, though that won’t be anywhere near as bad if you have an SSD drive.
Improve Even More?
If we want to get ridiculous and shave off another millisecond, we can parallelize the main loop. That would also require that we use some sort of locking to make sure that different threads don’t update the display simultaneously and interfere with each other; either use of the lock keyword or else Dispatcher.Invoke.
The main loop would look like the following:
Parallel.ForEach(countryLst, (c) => {
var matches = nationalityLst.Where(n => n.Consonym == c.Consonym);
foreach (var m in matches) {
if (m.Mate != c.Mate) {
Dispatcher.Invoke(() => txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n");
solutionCount++;
}
}
});Since my PC has 20 cores, the code above would potentially run 20 times faster than my current main loop. Who knows what amazing things I could do with the time I saved using that technique! Seriously though, parallelization is a powerful tool for tackling certain difficult problems.
Download the Code
Here’s a copy of my code. If you choose to download it, remember to modify the file path (at the top of the code) to reference a location on your computer, not on mine. Here’s a copy of my nationalities file. You will need a free Dropbox account to download.
NPR Sunday Puzzle: January 29, 2023
This week’s challenge comes from listener Samuel Mace, of Smyrna, Del. Name a fruit in one word. Drop the last two letters. The remaining letters can be rearranged to name two other fruits. What are they?
Synopsis
This puzzle was a bit of a challenge, but I’ll bet it’s even harder if you can’t write code! Finding dual anagrams after removing letters, in your head, strikes me as very tough. But I must admit anagrams are very hard for me.
Even using code, I still chose the wrong approach a couple times. First I naively tried splitting the original fruit after dropping the last two letters. Oops! Didn’t work – try again! Then I wrote some buggy code that tried to subtract the first “sub-fruit” from the main fruit – probably buggy because I tried to make it too efficient. After fighting that for a while, I used an easier, but somewhat less efficient method that involved converting a string to a list, and chopping letters out of it.
As usual, every time I made a mistake, it felt like I couldn’t solve it, or maybe I didn’t have the right fruit list. But for each problem, I analyzed my code, identified my mistake, and eventually I solved it.
Techniques Used
General Approach
I elected to use C#/ WPF (Windows Presentation Foundation) for this because 1) you can’t load files using web solutions, 2) WPF looks great and runs fast, 3) there is no need to run this code on a mobile device, 4) Python is cool but I haven’t figured out how to make a nice UI with it. WPF is greatly underappreciated but works great! For all you .NET haters, my algorithm works in any language, and the code runs with any .NET framework, such as Xamarin or ASP.
Basic Algorithm
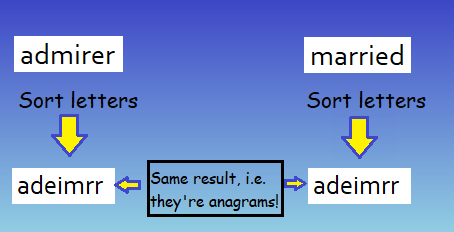
- Take advantage of this cool trick that tells you if two words are anagrams. Namely, if you take two words, sort their letters, and then observe that the result is the same string, then the two words are anagrams.
- Below is an example using the words ‘admirer’ and ‘married’, which we want to test for being anagrams of each other:
- With this trick in mind, load our fruit file into a dictionary
- Remember, each dictionary entry has a key and a value
- Our key will be the sorted letters
- and our value will be the original fruit name
- As illustrated in the example below, captured from a debug session in Visual Studio
- Remember, each dictionary entry has a key and a value
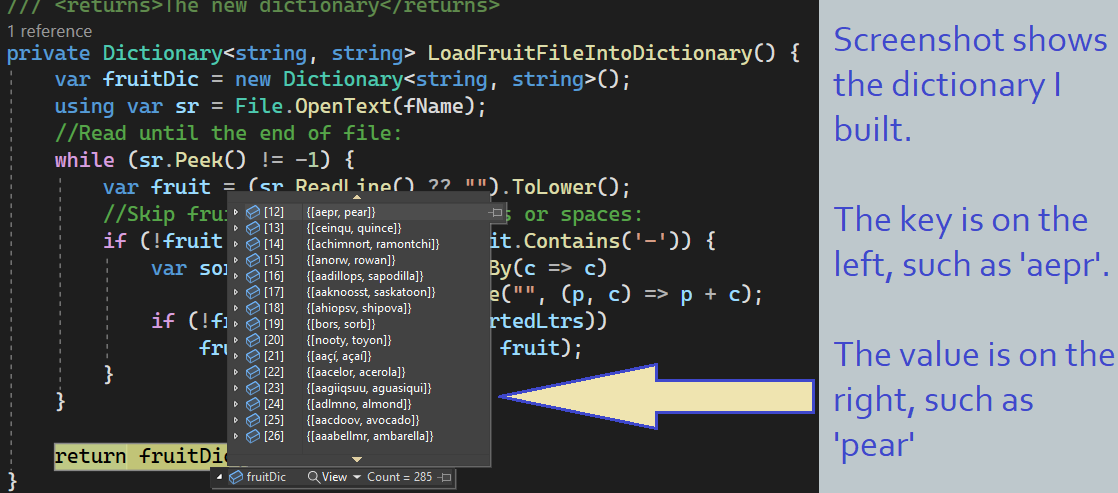
- Using the dictionary, I can test if an arbitrary string is the anagram of a fruit by checking whether the dictionary has such a key
- One way to do so is to use the
TryGetValuemethod that dictionaries support, such as the following:if (fruitDic.TryGetValue(sortedRemainder, out var match)) {- The code above asks my dictionary, named ‘
fruitDic‘, whether it has the key specified by variable ‘sortedRemainder‘ , and if so, placed the value into variablematch
- The code above asks my dictionary, named ‘
- Once I have built the dictionary, I can solve the puzzle by iterating it and manipulate each value
- By removing the last two letters from the value
- Then subtracting other fruit letters from said value
- Sorting the remaining letters
- And checking whether they are keys in the dictionary
- If so, we have a winner!
- As illustrated below:
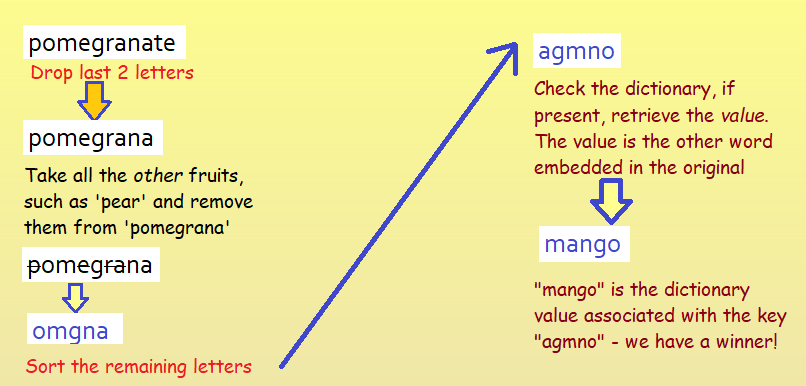
Here’s the Code!
private async void btnSolve_Click(object sender, RoutedEventArgs e) {
txtResults.Clear();
await Task.Run(() => {
//1) Read the fruit file and build the dictionary from it.
//The Dictionary contains key/value pairs: the value is the fruit name;
//the key is the sorted letters of that name
//For example: fruitDic["aepr"] = "pear",
//i.e. the key is "aepr" and the value is "pear",
//because the sorted letters of pear are "aepr"
var fruitDic = LoadFruitFileIntoDictionary();
//The code can find the same answer twice, the first time it finds pear/pomegranate -> mango
//and the second time it finds mango/pomegranate -> pear
//So use this list to avoid displaying duplicates:
var prevSolutions = new List<string>();
var keyList = fruitDic.Keys.ToList();
//Now that we've built the dictionary, iterate its keys to solve the puzzle
//Each pass tests a different fruit
for (var i = 0; i < keyList.Count; i++) {
//This loop examines the remainder of dictionary, seeking a mate for
//the fruit retrieved with index 'i'
for (var j = i + 1; j < keyList.Count; j++) {
var key1 = keyList[i];
var key2 = keyList[j];
if (key1.Length < key2.Length) {
//2) Trim the last two letters off the second fruit:
var longer = fruitDic[key2][..^2];
//3) This method removes one each of the letters from longer that also exist in shorter:
var (remainder, allMmatched) = RemoveShorterStringFromLonger(key1, longer);
if (allMmatched) {
//4)Sort the letters that remain in 'longer' to see if they anagram to a fruit:
var sortedRemainder = remainder.OrderBy(c => c).Aggregate("", (p, c) => p + c);
//5)If the sorted letters match an existing key, we found a solution:
if (fruitDic.TryGetValue(sortedRemainder, out var match)) {
if (!prevSolutions.Contains(fruitDic[key2])) {
var msg = $"{fruitDic[key1]}, {match}, {fruitDic[key2]}\n";
Dispatcher.Invoke(() => txtResults.Text += msg);
prevSolutions.Add(fruitDic[key2]);
}
}
}
}
}
}
});
}
Notes Corresponding to Numbered Comments Above
//1) Read the fruit file and build the dictionary from it.
var fruitDic = LoadFruitFileIntoDictionary();
I built the dictionary in a dedicated method named 'LoadFruitFileIntoDictionary', discussed below.
//2) Trim the last two letters off the original fruit:
var longer = fruitDic[key2][..^2];
Suppose that key2 = “aaeegmnoprt”
Then the code snippet fruitDic[key2] fetches the value “pomegranate”,
We strip the last two letters off that value using the notation [..^2]
Which means “take all the letters, starting from beginning, ending two from the end”
//3) This method removes one each of the letters from longer that also exist in shorter:
var (remainder, allMmatched) = RemoveShorterStringFromLonger(key1, longer);
This executes a method ‘RemoveShorterStringFromLonger’, discussed below.
It returns two values:
- remainder
- allMatched
‘remainder‘ represents the letters left over after removing the first string
‘allMatched‘ is a boolean, set to true if every word in the first string is also found in the second string.
We only care if the first string is a proper subset of the second string
For example, if key1=”aepr” and longer = “pomegrana”, then the method
will return remainder = “omgna”
and allMatched = true
because those are the letters left over after subtracting ‘pear’, and every letter in ‘pear’ matched a letter in ‘pomegrana’.
//4) Sort the letters that remain in ‘longer’ to see if they anagram to a fruit:
var sortedRemainder = remainder.OrderBy(c => c).Aggregate(“”, (p, c) => p + c);
Here I use Linq to sort the letters and build another string.
The following snippet from above builds a sorted IEnumerable (basically a list of letters):
remainder.OrderBy(c => c)
Now, I convert that “listy thing” back to a string using the Aggregate method:
.Aggregate("", (p, c) => p + c)
“” is the seed, i.e. what we append to, in this case an empty string. We could use a hypothetical seed like “blah”, in which case the result would be “blahomgna”. But that is just a silly example to show you what the seed does.
(p,c) => p + c
This snippet, from above, is an anonymous function that operates on every char in the list and provides two input parameters:
p – the Previous value, i.e. what we have built to-date
c – the Current letter (char)
In other words, take every letter in the sorted IEnumerable; for each letter we add the current to the the string we have accumulated from processing previous letters
//5) If the sorted letters match an existing key, we found a solution:if (fruitDic.TryGetValue(sortedRemainder, out var match)) {
Suppose my variable ‘sortedRemainder’ contains “omgna”, and the dictionary ‘fruitDic’ has such a key (it does!). Then TryGetValue returns true and assigns “mango” to the variable match. Since it returned true, the lines of code below are executed. It is true because “mango” is the value associated with key “agmno”.
Method ‘LoadFruitFileIntoDictionary’
OK, above I promised to discuss this method, so here is the code. It is very short (my explanation is longer than the code!):
private Dictionary<string, string> LoadFruitFileIntoDictionary() {
var fruitDic = new Dictionary<string, string>();
using var sr = File.OpenText(fName);
//Read until the end of file:
while (sr.Peek() != -1) {
var fruit = (sr.ReadLine() ?? "").ToLower();
//Skip fruits that contain hyphens or spaces:
if (!fruit.Contains(' ') && !fruit.Contains('-')) {
var sortedLtrs = fruit.OrderBy(c => c)
.Aggregate("", (p, c) => p + c);
if (!fruitDic.ContainsKey(sortedLtrs))
fruitDic.Add(sortedLtrs, fruit);
}
}
return fruitDic;
}
Notes for Method ‘LoadFruitFileIntoDictionary’
using var sr = File.OpenText(fName);
- ‘sr’ is a StreamReader that allows me to read lines from the file using its
ReadLinemethod fNameis a class-level variable containing the path/file name of my fruit file- Because I utilized the syntax “
using“, my file stream is closed automatically when sr goes out of scope
while (sr.Peek() != -1) {
- When the
Peekmethod returns -1, it means we have hit the end of the file
var sortedLtrs = fruit.OrderBy(c => c).Aggregate("", (p, c) => p + c);
- As before, sort the letters in the fruit using the
OrderBymethod - The result is something like a list of letters (
char), actually anIEnumerable<char> - We use the
Aggregatemethod to convert that “listy thing” into a string - The
Aggregatemethod has two parameters:- The seed string
- The anonymous method that is executed on every entry in the ‘list’ provided as input
- Namely,
(p, c) => p + c) - p is the value we have accumulated after processing previous entries
- c is the current value
- + means add the current to the previous to build the value we accumulate
- Namely,
if (!fruitDic.ContainsKey(sortedLtrs)) fruitDic.Add(sortedLtrs, fruit);
If the dictionary doesn’t already contain an entry with key sortedLtrs,
- Then add a new entry
- Using
sortedLtrsfor the key - and
fruitfor the value
- Using
Method RemoveShorterStringFromLonger
private (string, bool) RemoveShorterStringFromLonger(string shorter, string longer) {
var longerLst = longer.ToList();
var matchCount = 0;
foreach(var c in shorter) {
var ndx = longerLst.IndexOf(c);
if (ndx >= 0) {
longerLst.RemoveAt(ndx);
matchCount++;
} else
break;
}
//The result has two parts:
//1) the remainder after removing shorter from longer,
//2) a boolean reflecting whether every char in shorter also belonged to longer:
return (longerLst.Aggregate("", (p, c) => p + c),
matchCount == shorter.Length);
}
Explanation:
var longerLst = longer.ToList();
- Convert the string
longerto a list, because it is slightly more efficient and easier to work with - I could revise it to use string manipulation, but it works as-is and I don’t feel like it – I fought enough bugs already!
var ndx = longerLst.IndexOf(c);
if (ndx >= 0) {
longerLst.RemoveAt(ndx);
- Search for the current character
c - If found,
ndxwill be 0 or higher - Remove the letter
cfrom the list using the index where we found it
For example, suppose this method is invoked using the parameters
shorter = “pear”
longer = “pomegrana”
Then the method would return two parameters, the first being a string with value “omgna”, and the second being a boolean with value = true.
The first return parameter is constructed with this code snippet: longerLst.Aggregate("", (p, c) => p + c)
The second return parameter is constructed with this code snippet: matchCount == shorter.Length
The second return parameter might be a bit confusing to some; what it does is apply the == operator to the two parameters. If they are the same length, then it evaluates as true, otherwise it evaluates as false.
OK, How’d You Get the Fruit File?
I ‘screen-scraped’ the list of fruits from a Wikipedia page, List of culinary fruits. For the sake of brevity, I won’t discuss that here, but if you download my code, you can see how I did it. When using HtmlAgilityPack, it is very easy, assuming you understand XPath. Download link below.
Note: if you download, build and run my code, you will need to modify the file name, because my code has a hard-coded path to a location on my PC.
Hey, You Said You Used HashSets, But I didn’t See Any!
I didn’t discuss it above, but my code uses a HashSet to avoid creating duplicates to my fruit file. You will see it if you download the code and examine the code that runs when you click the button ‘Get More Fruits’. Download link below. HashSets are a highly-efficient and convenient way to keep track of things, and to speedily check whether some value already exists in the HashSet.
Summary
- Approximately 2 hours to code the fruit file download from Wikipedia (first download runs in 4,159 milliseconds, the second requires 488 ms)
- Resulting in 906 fruit names
- Approximately 3 hours to write the code that solves the puzzle using that file
- 260 lines of code, of which about half is comments
- The UI is specified using 73 lines of XAML, edited both “visually” and “by code”
- Approximately 38 milliseconds to run the code (note that my PC is pretty fast)
- Approximately 5 hours to write this up
Get the Code!
You can download my code from this link. Note: you will need to get a DropBox account (free) to do so.
NPR Puzzle for November 20, 2022
Science Branch with Two Embedded Anagrams
Last week’s challenge came from Henri Picciotto, of Berkeley, Calif. He coedits the weekly “Out of Left Field” cryptic crossword. Name a branch of scientific study. Drop the last letter. Then rearrange the remaining letters to name two subjects of that study. What branch of science is it?
Link to the challenge
General Approach
I elected to use WPF for this one, for one reason, I was in a bit of a hurry, and I’m faster in WPF. Also, WPF is well suited for file handling, unlike web-based solutions, and the code needs to load a file containing English words, as well as a file containing fields of science. Finally, the code is a bit CPU intensive; Python would run slower, and building a nice UI in Python is harder, at least for me!
Here’s how my UI looks after clicking the ‘Solve’ button:
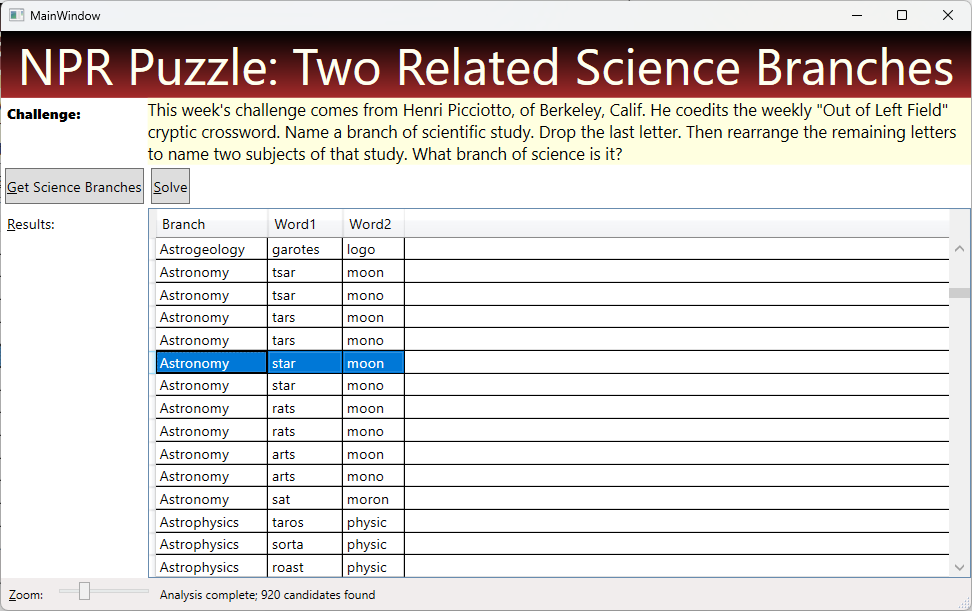
Techniques Used

Synopsis
We can get a list of 716 branches of study from Wikipedia. Using HtmlAgilityPack, we can extract the names from the raw HTML on that page. That is the list we will attempt to manipulate, so we need a list of English words, many of which are available on the web (including this one).
Using those two sources, proceed by first splitting each branch into two parts (after stripping the last letter). Note that each branch can be split at several points, so we use a loop to try every valid split point.
Having split the original, we anagram the two sub-words. To do so, we take advantage of a simple fact relating to anagrams:
Two words are anagrams if their sorted letters are the same

To capitalize on this principle, we build a dictionary, using every word in English, whose keys are the sorted letters, having an associated value composed of the list of words that share those sorted letters. That way, we can easily and efficiently find the anagrams of any word. Here’s what a sample dictionary entry looks like:
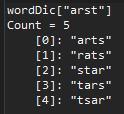
Interpretation: the image above is a screen shot from Visual Studio’s Immediate Pane. It shows the value associated with one particular dictionary key, “arst”, which is a list of 5 words, all of which are anagrams of each other. Just to make it ultra clear, here is the dictionary entry for “mnoo”:
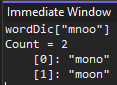
The dictionary will contain 75,818 such entries.
Using the dictionary, we can tell if a candidate has any anagrams by checking if its sorted letters exist in the key. If the key exists, we can get all the anagrams for the candidate by examining the value associated with that key. Remember, each entry in a dictionary is a key/value pair.
So, to recapitulate, we will build a dictionary from all English words, each entry has the sorted letters as the key, and the list of anagrams as the value. We loop through the science branches, splitting each into two candidates. If both candidates are in the dictionary (after sorting their letters), then we have a candidate solution.
Here’s the Code!
To save space, I will omit the part of my code which downloads the list of science branches. But have no fear, you can download all my code and examine it to satisfy your curiosity, using the link at the bottom.
Note that the code below is just an excerpt, representing the most important code. At the point where the excerpt begins, we already have the following variables:
branchList– a list of all 716 branches of science, a simple list of type stringwordDic– a dictionary constructed as described above, using sorted letters as the key to each entry
Obviously, if you want to see the code I haven’t discussed below, you can just download my entire project (link below); I believe the embedded comments in that code should satisfy your curiosity.
Note that each numbered comment in the listing below has a corresponding explanation after the code listing.
//Every candidate solution will go into this collection, which is bound to the display:
var answers = new ObservableCollection<Answer>();
grdResults.ItemsSource = answers;
//The syntax below allows the screen to remain responsive while the algorithm runs
await Task.Run(() => {
int count = 0;
foreach (var candidate in branchList) {
//1) remove the last letter
var trimmed = candidate.ToLower()[..^1];
//2) This inner loop tries splits the science branch at all possible points
//forming two parts, br1 and br2:
for (var i = 1; i < trimmed.Length - 1; i++) {
//3) Take the first part of the candidate and sort its letters
var br1 = trimmed[..i].OrderBy(c => c).Aggregate("", (p, c) => p + c);
//4) If the sorted letters are in the dictionary, work with
//the 2nd part of the branch:
if (wordDic.ContainsKey(br1)) {
//5) Grab the 2nd part of the branch and sort its letters
var br2 = trimmed[(i)..].OrderBy(c => c).Aggregate("", (p, c) => p + c);
//6) If br2 is in the dictionary, we have a potential solution:
if (wordDic.ContainsKey(br2)) {
//7) Each entry (the science branch name part) has a list associated with it
//(the entry's value); display all combinations from those 2 lists
foreach (var word1 in wordDic[br1]) {
foreach (var word2 in wordDic[br2]) {
var addmMe = new Answer { Branch = candidate, Word1 = word1, Word2 = word2 };
answers.Add(addmMe);
}
}
}
}
}
//Update the progress bar
var pct = (int)(100 * count++ / (float)branchList.Count);
Dispatcher.Invoke(() => prg.Value = pct);
}
});
Numbered Comment Explanation
var trimmed = candidate.ToLower()[..^1];- Each branch of science in the list is mixed case, so use “
ToLower” to match our dictionary - [..^1] means take a substring starting at the beginning, all the way to 1 before the end
- Each branch of science in the list is mixed case, so use “
for (var i = 1; i < trimmed.Length - 1; i++) {- The variable
icontrols the split point in the candidate; the first eligible position is 1, because we don’t want any zero-length strings. Similarly, the last split point is 1 before the end - For example, the word “astronomy” would be split as 7 different times, once for each pass through the loop, with the split points shown below, as well as the pertinent variables:
- i = 1, a – stronom, br1 = a, br2 = oomnrst
- i = 2, as – tronom, br1 = as, br2 = oomnrt
- i = 3, ast – ronom, br1 = ast, br2 = oomnr
- i = 4, astr – onom, br1 = arst, br2 = oomn
- i = 5, astro – nom, br1 = aorst, br2 = omn
- i = 6, astron – om, br1 = anorst, br2 = mo
- i = 7, astrono – m, br1 = anoorst, br2 = m
- The variable
var br1 = trimmed[..i].OrderBy(c => c).Aggregate("", (p, c) => p + c);- Take the substring ending at position i. Then sort the letters (“
OrderBy“). Note that the result isIEnumerable<char>– basically a list of characters. Now take the result of that operation andAggregateit so we get a string instead of a list of char. - Interpret the aggregation as follows:
- “” (Empty quotes) This is the seed, we start with an empty string and append everything to it
(p,c) =>this introduces the two parameters used in the operation, they represent the previous (p) value and the current valuec. Previous means the string we have built so farp + cWe simply append the current character to the previous value
- The upshot is this code converts a list of char into a string
- Take the substring ending at position i. Then sort the letters (“
if (wordDic.ContainsKey(br1)) {- Test if the sorted letters (
br1) have an anagram by asking the dictionary if it has a corresponding key. This is like asking the dictionary if ‘arst’ has an entry in the key. Remember, ‘arst’ is an anagram of ‘star’.
- Test if the sorted letters (
var br2 = trimmed[(i)..].OrderBy(c => c).Aggregate("", (p, c) => p + c);- Now take the second part of the science branch and do the same thing
- The only thing that is different is how we take the last part of the original, namely,
trimmed[(i)..]
- This means “take a substring starting at position i, up to the very end
if (wordDic.ContainsKey(br2))- Like before, check if the sorted letters “br2” have any anagrams,
- If so, we have a potential solution!
Remember, the list answers is bound to the display grid, so merely adding it causes it to be displayed. It is then up a human to decide whether the displayed anagrams are actually studied as part of the science branch.
Get the Code to Solve the Puzzle
You can download my complete code, including my list of 716 branches of science, here. Note that you will need a DropBox account to use that link, but that is free. Also, you will need a list of English words; you can get one here. You will need to modify your version of the code to reflect the path where you save this file.
NPR Puzzle for June 12, 2022
Famous American’s last name manipulated to become a European capital.
This week’s challenge comes from listener Theodore Regan, of Scituate, Mass. Take the last name of a famous 20th-century American. The 5th, 6th, 7th, and 1st, 2nd, and 3rd letters, in that order, name a European capital. Who is the person, and what capital is it?
Link to the challenge

Techniques Used
- String Manipulation
- Simple File IO
- Screen Scraping (to get the famous Americans lists)
- XPath (Only discussed in my comments in the download)
- HtmlAgilityPack (also only in the download)
Synopsis
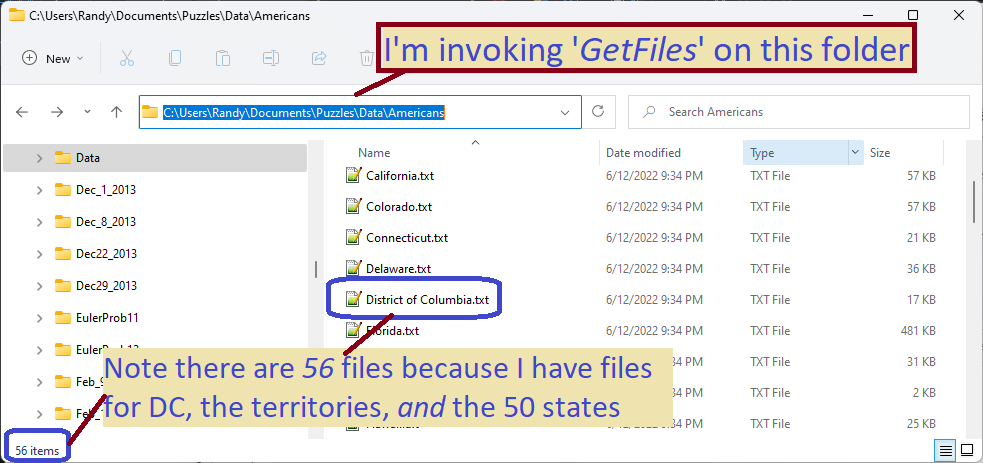
 This one should have been easy, but I struggled some. First, I had to get a good enough list of famous Americans. That was tricky because my list source was 56 separate pages on Wikipedia (one page per state or territory). The large number of pages was not a problem as much as the differing formats on each page. Then I accidentally assumed the person’s name should be six letters long, resulting in no output until I realized my mistake.
This one should have been easy, but I struggled some. First, I had to get a good enough list of famous Americans. That was tricky because my list source was 56 separate pages on Wikipedia (one page per state or territory). The large number of pages was not a problem as much as the differing formats on each page. Then I accidentally assumed the person’s name should be six letters long, resulting in no output until I realized my mistake.
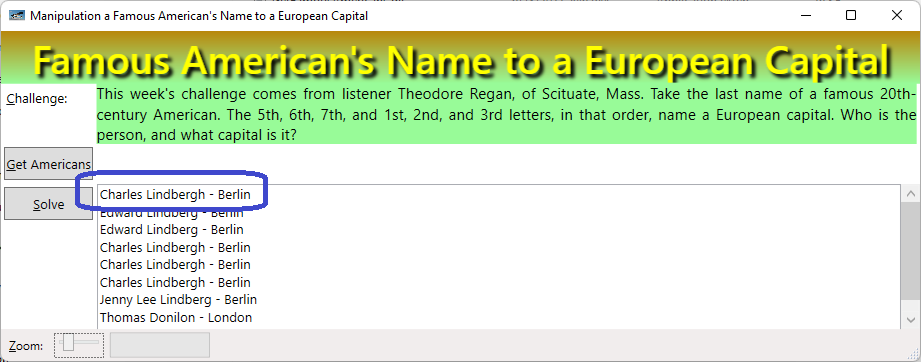
Even though I struggled a bit, I’m pretty sure that this puzzle is still easier to solve by coding than by traditional methods. Yea, team coders!
However, having struggled to build the famous Americans files (also the European capitals), the algorithm is straightforward: 1) read the capitals into a list, 2) read each person from the 56 files, 3) parse each input line to extract the last name, 4) manipulate the last name per Will’s instructions, and 5) search the capitals list to see if the manipulated name matches any capital.
The heart of the algorithm is encapsulated in the following four lines of code:
var candidate = lastName[4..7] + lastName[..3];
var ndx = capitalList.BinarySearch(candidate, StringComparer.OrdinalIgnoreCase);
if (ndx >= 0)
txtResults.Text += $"{fullName} - {capitalList[ndx]}\n";
Don’t worry if it doesn’t make sense yet, I’ll explain it below. 😊
Here’s the Code!
Comments below with a number correspond to a numbered bullet point in the explanation deeper down:
private void btnSolve_Click(object sender, RoutedEventArgs e) {
//Load the capitals into a list via a method defined below:
var capitalList = LoadCapitalList();
var folderName = @"C:\Users\Randy\Documents\Puzzles\Data\Americans";
//1) The folder holds 56 files, one for each state or territory
var fList = Directory.GetFiles(folderName);
//Loop through all 56 files and read each line:
foreach(var fileName in fList) {
using(var sr = File.OpenText(fileName)) {
//2) Peek tells us when we hit the end of the file
while(sr.Peek() != -1) {
var aLine = sr.ReadLine() ?? "";
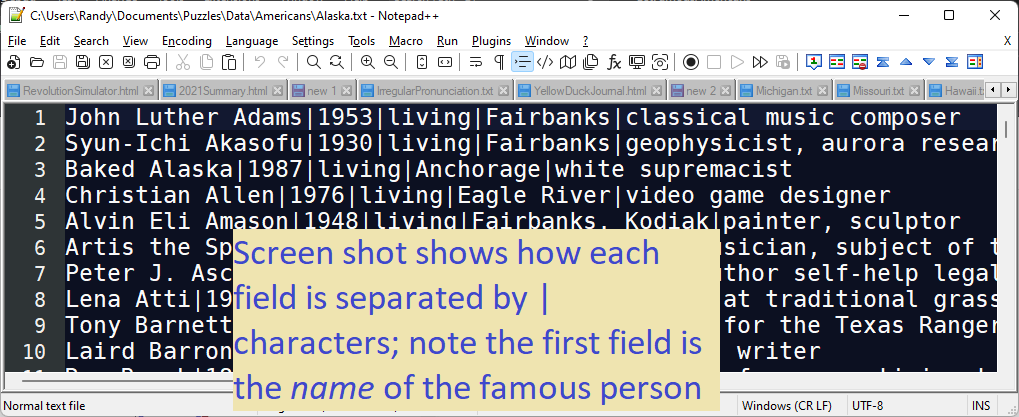
//3) Each line holds multiple fields separated by | characters
//The first field is the person's name, so find the 1st |
var p = aLine.IndexOf('|');
var fullName = "";
if (p >= 0)
//4) Extract everything before the |, using range operators:
fullName = aLine[..p];
else
fullName = aLine;
//Now that we have the full name, extract the last name
var lastName = "";
//Look for the last space, the last name starts after it:
p = fullName.LastIndexOf(' ');
if (p >= 0)
//5)
lastName = fullName[(p + 1)..];
else
//Some people only have one name, so there is no space
lastName = fullName;
if (lastName.Length >= 7) {
//5) Swap the letters per Will's instructions:
var candidate = lastName[4..7] + lastName[..3];
//6) Binary search is fast and allows mixed-case matches:
var ndx = capitalList.BinarySearch(candidate,
StringComparer.OrdinalIgnoreCase);
//If ndx is non-negative, that means we have a solution!
if (ndx >= 0)
txtResults.Text += $"{fullName} - {capitalList[ndx]}\n";
}
}
}
}
}
Discussion
var fList = Directory.GetFiles(folderName);- The method
GetFilesreturns an array of file names which we can loop through 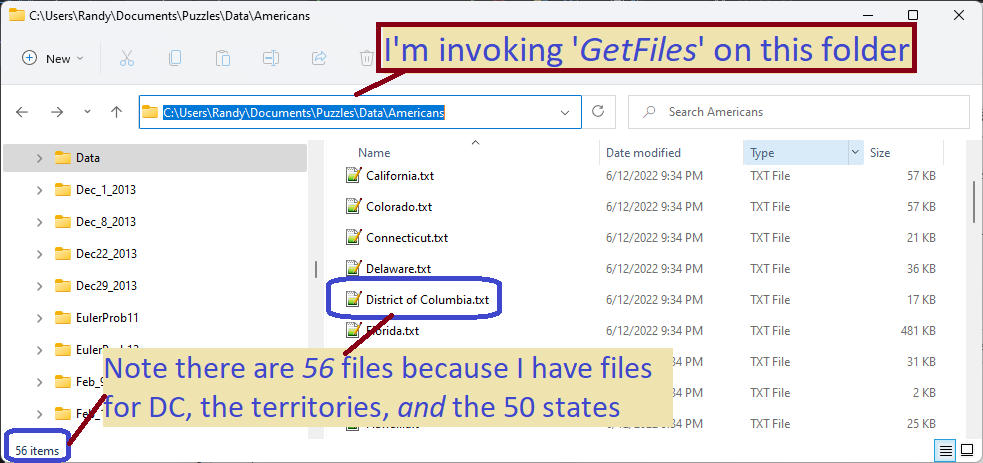
- The
GetFilesmethod returns an array, which I iterate, so as to process every file in the folder
- The method
while(sr.Peek() != -1) {- ‘sr’ is a
StreamReader; thePeekmethod tells us when we reach the end of the file by returning -1
- ‘sr’ is a
var p = aLine.IndexOf('|');- My files containing famous people uses the pipe (‘|’) character to separate fields
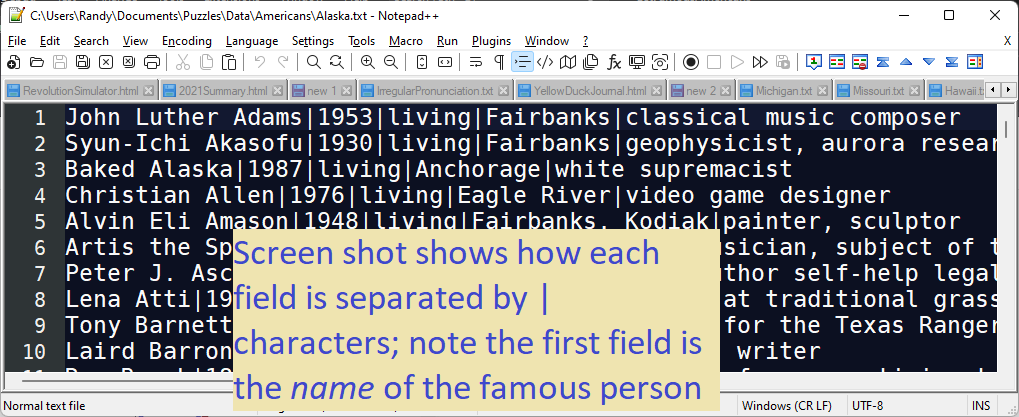
- So that is why I search for a ‘|’, because the name ends where the ‘|’ starts.
fullName = aLine[..p];- Here I am using the
rangeoperator to extract a sub-string from the variableaLine. - The syntax above is equivalent to
aLine[0..p], meaning “start at position 0 and finish prior to p“. - However, we can omit the 0 because it is implied when omitted
- Here I am using the
var candidate = lastName[4..7] + lastName[..3];- The
candidatemight be a European capital; per Will’s instructions, we put letters 4-7 at the start, concatenate letters 1-3 at the end. Again, I am using range operators
- The
var ndx = capitalList.BinarySearch(candidate, StringComparer.OrdinalIgnoreCase);- The binary search method is a super fast way to search a list, also convenient
- Note that the candidate I just built looks like this: “berLin“. Note that ‘b’ is lower case and ‘L’ is upper case, because that’s how they appeared in the source, ‘Lindebergh‘.
- Also note that the entry in
capitalListhas different capitalization, ‘Berlin‘, and under normal string comparison, these two strings are not equal! - I handle this by specifying ‘
StringComparer.OrdinalIgnoreCase‘ as a parameter to the search. This means the strings will be compared ignoring case. - Note that the result returned by the
BinarySearchmethod is a negative number if nothing is found, otherwise it is the index of the item searched for. In my list of 65 capitals, Berlin is at index 7. Note that C# uses zero-based indexing, meaning that the first entry has index 0, which is confusing to many, including me 😒
Method ‘LoadCapitalList‘ Loads the Capitals File into a List
The method shown below was invoked in the code listing above:
private List<string> LoadCapitalList() {
var fName = @"C:\Users\Randy\source\repos\GetFamousAmericans\GetFamousAmericans\EuropeanCapitals.txt";
var capitalList = new List<string>();
using (var sr = new StreamReader(File.OpenRead(fName)))
while (sr.Peek() != -1) {
//'Readline' returns null or a string, the null coalesce
//operator ?? says 'convert any null to an empty string'
var aLine = sr.ReadLine() ?? "";
//The file has two fields separated by '~'; the 1st field is the capital
var p = aLine.IndexOf("~");
var capital = aLine[..p];
capitalList.Add(capital);
}
//Binary search only works on sorted lists, so sort it!
capitalList.Sort();
return capitalList;
}
Remarks – Loading the File
The code is pretty straightforward, using the same techniques as shown above to open the file and loop through it. Note that this file is different because its delimiter is a tilde, not a pipe.
Code to Get Famous Americans
In order to keep this post short and sweet, I omitted explaining how I did that. However, you can download my code and examine the comments in the file to learn more. Note that the code to get the famous Americans is considerably more complex than the code to solve the puzzle. To download the HTML pages and parse them, I used HtmlAgilityPack, which in turn relies on XPath. That allowed me to extract the parts of the page I wanted, ignoring all the text and formatting.
Get the Code!
Click here to download my code; note that to do so, you will need a free DropBox account. You will need to revise any variables containing file paths to match the path on your PC. Unless you have folders name ‘Randy’!
Puzzle June 5, 2022
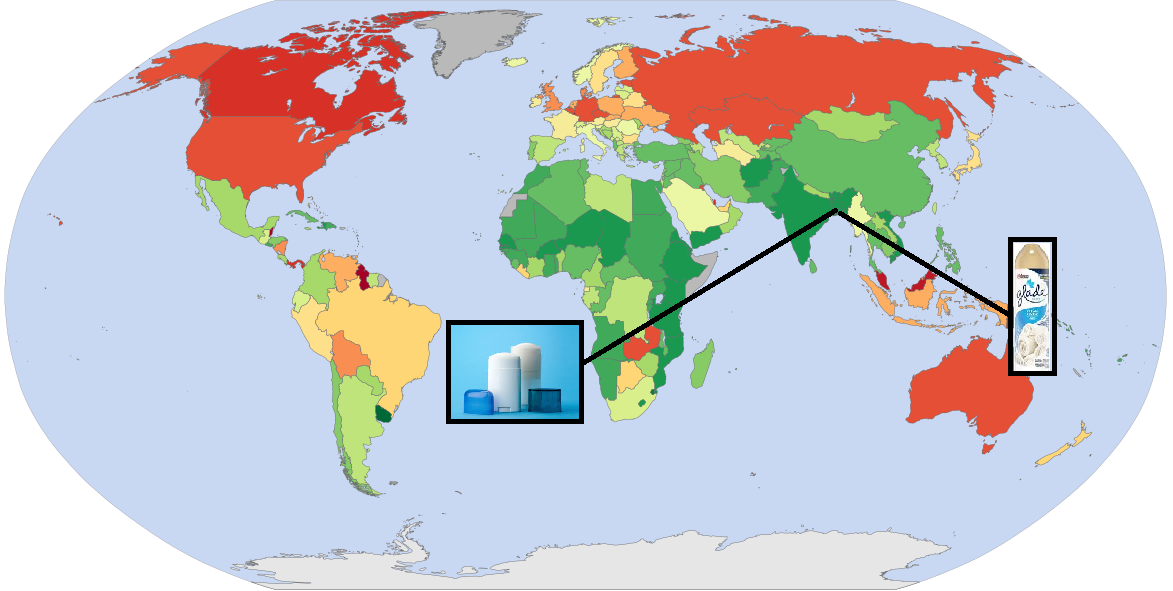
Country Name Containing a Deodorant and an Air Freshener
This week’s challenge comes from listener Ben Bass of Chicago. The name of what country contains a deodorant and an air freshener in consecutive letters?
Link to the challenge
Techniques Used
- String manipulation
- Simple file handling

Synopsis
Another super easy one! There aren’t that many consumer products to search for, and for some reason, people have made web pages for those products. So I was able to copy the product names manually off those web pages and save as a pair of files I used to solve the puzzle. Happily, I already had a list of country names, so no work was required for that.
After making my files, the process involved 1) reading the country, deodorant and freshener names into three lists, 2) iterating the country list, 3) for each country, searching the name for a deodorant, 4) if a hit resulted, searching again for a freshener.
Since Will didn’t say whether the deodorant was first, I actually needed two search sections, one that searches for deodorant being first in the country, the other for the freshener being first.
The similarities in loading the three lists resulted in consolidating my code to a method to do the work. Similarly, I wrote a single method to search a country name for the contents of two anonymous lists, thereby allowing me to invoke the same code twice but with the lists in different order. The result was another consolidation of code, again making the resulting program shorter and easier to understand.
Here’s the Code!
First, the Main Method, Which Makes use of My Two Methods
private void btnSolve_Click(object sender, RoutedEventArgs e) {
//1) Make a list of country names:
var fName = @"C:\Users\Randy\Documents\Puzzles\Data\Countries.txt";
var countryList = ReadFileIntoList(fName);
//2) Make another list of deodorant names:
fName = @"C:\Users\Randy\Documents\Puzzles\Data\Deodorants.txt";
var deodorantList = ReadFileIntoList(fName);
//3) And now another list of air fresheners:
fName = @"C:\Users\Randy\Documents\Puzzles\Data\AirFresheners.txt";
var freshenerList = ReadFileIntoList(fName);
//4) Loop through the countries and check each to see if it matches:
foreach (var country in countryList) {
//This block of code checks for deodorant first, followed by air freshener
var solution = FindListEntriesInCountryName(country, deodorantList, freshenerList);
if (!string.IsNullOrWhiteSpace(solution))
txtResult.Text += solution;
//5) This block of code swaps the list order to check for
//air freshener first, followed by deodorant:
solution = FindListEntriesInCountryName(country, freshenerList, deodorantList);
if (!string.IsNullOrWhiteSpace(solution))
txtResult.Text += solution;
}
}
Remarks
The code above is pretty straightforward. Code blocks marked above as items 1, 2, 3 serve to load the three files into three lists. Each returned list contains string entries
The code blocks marked as items 4 and 5 above serve to search the country name for deodorant name and air freshener. The parameter order is swapped when I invoke ‘FindListEntriesInCountryName‘, meaning that block 4 searches for deodorant followed by an entry in the freshener list, and block 5 does vice versa.
My Two Methods
/// Open a file, read each line and add it to a list private List ReadFileIntoList(string fName) { var result = new List<string>(); using (var sr = File.OpenText(fName)) while (sr.Peek() != -1) { var addMe = sr.ReadLine() ?? ""; result.Add(addMe); } return result; }/// Searches a country name using entries from two lists private string FindListEntriesInCountryName(string country, List<string> list1, List<string> list2) { var result = ""; foreach (var deodorant in list1) { var p1 = country.IndexOf(deodorant, StringComparison.CurrentCultureIgnoreCase); if (p1 >= 0) { var startPos = p1 + deodorant.Length; if (startPos < country.Length) foreach (var freshener in list2) { var p2 = country.IndexOf(freshener, startPos, StringComparison.CurrentCultureIgnoreCase); if (p2 >= 0) { result = $"{country} - {deodorant} - {freshener}\n"; break; } } } } return result; }
Remarks on the Two Methods
ReadFileIntoList
The first method opens the file whose name was provided as a parameter, ‘fName‘. File.OpenText gives us a StreamReader which has two methods we use: Peek and ReadLine.
var addMe = sr.ReadLine() ?? "";
What’s that weird looking code above? Note that ReadLine might theoretically return null; I deal with that issue by using the ?? operator (the null coalescing operator). The string I supply after the ?? operator (an empty string) is substituted whenever a null is returned. I could have substituted “WTF” instead of an empty string, but that would have been silly 😆.
FindListEntriesInCountryName
The second method takes a country name as input, plus two lists named ‘List1’ and ‘List2’. First we iterate list 1, using the IndexOf method to check if a list entry is present in the list. IndexOf will return a negative number if it fails, so when we find a number 0 or higher, we know we have a hit.
In that case, we check if the second list might contain another match. It must start after the first hit, so I use a variable ‘startPos‘ to indicate where we should look inside the country name. For example, if I found deodorant ‘DogBreath’ at position 2 in the country name, then startPos would be 11, because the length of the deodorant is 9 and 9 + 2 = 11.
In actuality, ‘Ban’ is at position 0, so I look for entries in the freshener list starting at position 3. Remember that string indices start at position 0, not position 1.
Can you Spot my Cheat?
If you’re paying close attention, you might realize that Will says the 2nd entry should start immediately after the first. But my code allows intervening letters. I left this in place for simplicity and because I found a single solution. But theoretically, my code could have found ‘BanBlahBlahBlahGladeSh as an answer!
Download my Code
Click here to download my code; note that you will need a (free) DropBox account to do so.
Sunday Puzzle May 22, 2022
Manipulate an Island Name to get Another Island
It’s an easyish one and comes from Blaine Deal, who conducts a weekly blog about Will’s NPR puzzles. Take the name of an island. Move its first letter two spaces later in the alphabet (so A would become C, B would become D, etc.). Reverse the result and you’ll have the name of another island. What islands are these?
Link to the challenge

Techniques Used
- String manipulation
- Simple file handling
- Linq methods ‘Aggregate’ and ‘Reverse’

Synopsis
Will was right, that was a pretty easy puzzle 😊. The hardest part about this one was building my island list. Eventually, I was able to use the list on Britannica.com, after manually editing their text for about half an hour.
After saving the result as a file, it was a simple matter of 1) reading that file into a list, 2) manipulating each list entry, and 3) checking whether the result was also an entry in that list.
Here’s the Code!
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
var islandLst = new List<string>();
//Read the file and put each line into the list declared above:
var fName = @"C:\Users\Randy\Documents\Puzzles\Data\Islands.txt";
using (var sr = File.OpenText(fName))
while (sr.Peek() != -1)
islandLst.Add(sr.ReadLine() ?? "");
foreach(var island in islandLst) {
//Manipulate the first letter and store the result in variable 'switched'
var switched = (char)(char.ToLower(island[0]) + 2) + island[1..];
//Reverse the letters and convert to a string:
var reversed = switched.Reverse().Aggregate("", (p,c) => p + c);
//Convert the first letter to upper case
var candidate = char.ToUpper(reversed[0]) + reversed[1..];
//Search the list for the result:
var ndx = islandLst.BinarySearch(candidate);
if (ndx >= 0)
//Display the results:
txtResult.Text += $"{island} - {islandLst[ndx]}\n";
}
Mouse.OverrideCursor = null;
}
Discussion
Here’s how I manipulate each entry in the islandLst to form a candidate to check. The lines highlighted above are discussed below:
var switched = (char)(char.ToLower(island[0]) + 2) + island[1..];
- Note that .NET allows you to treat a string variable as an
arrayofchar, so you can use indexing on that array. To wit,island[0]retrieves the first character from that array, at index 0
- .NET also allows you to perform arithmetic on
charvariables, so, ifcis a char variable, thenc + 2is a character moved up in the alphabet by two. So'g' + 2 = 'i', because i is two higher than g. However, the result is not achar, so I need to cast it back tocharbefore concatenating it with the remainder of the string. Casting is accomplished with the syntax(char), used as a prefix above.
- Note that .NET allows you to treat a string variable as an
var reversed = switched.Reverse().Aggregate("", (p,c) => p + c);
- ‘
Reverse()’ is aLinqmethod that builds anIEnumerable‘list’ of char in the reverse order of the original. I can use it on a string because, as mentioned above, astringis an array ofchar, andLinqcan operate on an array (because an array is an IEnumerable) - ‘
Aggregate‘ is anotherLinqmethod that has two parameters:- The initial/seed value to aggregate with, namely, an empty string “”
- A Lambda expression
(p,c) => p + cthat tells .NET how to perform the aggregation. My variable ‘p‘ represents the previous value (the results so far), and my variable ‘c‘ represents the current list entry being processed. Effectively, my code says “for each list entry, add it to the running output”
- Why use
Aggregate? Because, as mentioned above,Reversegives me a list (technically anIEnumerable), and I need to convert it to a string.
- ‘
var candidate = char.ToUpper(reversed[0]) + reversed[1..];
- Take the first char (reversed[0]) and convert it to upper case (
char.ToUpper) - Concatenate that with the remainder of the string (
reversed[1..]). Note that the plus sign + serves as a concatenation operator, and .NET allows you to concatenate acharto astring.
- Take the first char (reversed[0]) and convert it to upper case (
Finally, having built a candidate, I search the list again to see if that list actually contains the candidate.
var ndx = islandLst.BinarySearch(candidate);
If the binary search operation returns a non-negative number, it means we have a solution!
Get the Code
Here’s the link to get my code. Note that you will need a (free) DropBox account to access that link. The compressed file contains my island list, which you can use to solve the puzzle yourself.
Sunday Puzzle for May 15, 2022
Manipulate an Actor Name to get a French Phrase
This week’s challenge comes from listener John Sieger, of Wauwatosa, Wis. Name a famous living movie star. Insert an R in the middle of the first name, and drop the last two letters of the last name. You’ll get a familiar French phrase. What is it?
Link to the challenge

Techniques Used
- File handling
- Text processing, including manipulation of Unicode characters
- Screen scraping with HtmlAgilityPack
- XPath
- String manipulation
- Simple async operations
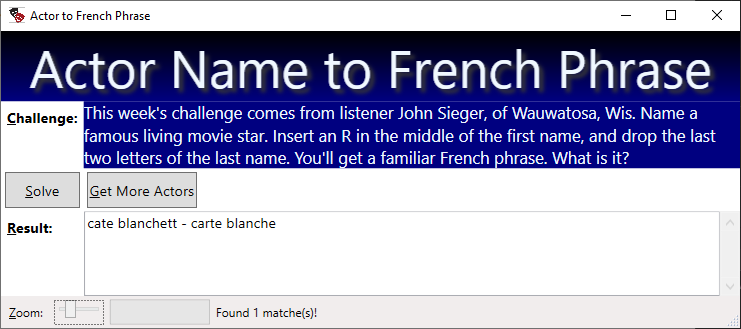
Synopsis
Note: I originally published this a few days ago as a Page; I should have published it as a Post, because, for whatever reason, WordPress makes it really hard to find pages. So I have republished it hear as a page.
This one was a bit harder than normal; after struggling with my original actor list, I had to augment it, and finding lists of French phrases was hard. In interests of full disclosure, I had to try a few things that aren’t shown in my published code to get it to work. Specifically, I had to convert the actor names into French words, then inspect the output and check if any looked like a French phrase, because “carte blanche” wasn’t in any list I found. After I inspected my output, I added carte blanche to my list of phrases.
But the good news is now I get to show off some elementary usage of the outstanding HtmlAgilityPack library, which allows you to process web pages using XPath, making it possible to find text on a page that matches certain HTML markup patterns. In this case, links (a elements) which are children of h3 header elements having a particular class attribute.
For language choice, I once again used .NET/WPF, one reason being I am pretty good at screen scraping in .NET, also because I know how to remove diacritical marks from text using .NET. I had to screen-scrape the IMDB site to get more actors, and the french phrases contain lots of non-ASCII characters (i.e. diacritical marks) that I needed to compare against the manipulated actor names. I’m better at both those tasks in .NET compared to Python.
Here’s the Code!
First, Code That Solves the Puzzle
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
var fName = @"C:\Users\Randy\Documents\Puzzles\Data\Actors\FrenchPhrases.txt";
var phraseLst = new List<string>();
//Open the French Phrases file, read each line,
//remove diacritics, add to list 'phraseList'
using (var sr = new StreamReader(File.OpenRead(fName))) {
while (sr.Peek() != -1) {
var aLine = (sr.ReadLine() ?? "").ToLower();
int p = aLine.IndexOf(":");
var phrase = aLine[..p];
//The method 'RemoveDiacritics' is listed below
phraseLst.Add(RemoveDiacritics(phrase));
}
}
//Now process the actors file; manipulate each name and see if
//the result matches an entry on our list 'phraseList'
var solutionCount = 0;
fName = @"C:\Users\Randy\Documents\Puzzles\Data\Actors\Actors.txt";
using (var sr = new StreamReader(File.OpenRead(fName))) {
while (sr.Peek() != -1) {
var aLine = (sr.ReadLine() ?? "").ToLower(); ;
var tokens = aLine.Split(' ', StringSplitOptions.RemoveEmptyEntries);
if (tokens.Length > 1) {
//Find the middle index of the first name
var p = (int)tokens[0].Length / 2;
//Inject an 'r' at the middle index
var first = tokens[0][..p] + "r" + tokens[0][(p)..];
//Check if the last name has enough letters to trim the last two
if (tokens[^1].Length > 3) {
//Remove the last 2 letters:
var last = tokens[^1][0..^2];
var newName = $"{first} {last}";
//Check if the transformed name is in the list:
var ndx = phraseLst.IndexOf(newName);
//Display the result(s)
if (ndx >= 0) {
txtResults.Text += $"{aLine} - {phraseLst[ndx]}\n";
solutionCount++;
}
}
}
}
}
if (solutionCount > 0)
txtMessage.Text = $"Found {solutionCount} matche(s)!";
Mouse.OverrideCursor = null;
}
Code Highlights
- Using standard file handling techniques, open the file containing the phrases
- Each line in that file looks like the following example:carte blanche: Unrestricted power to act at one’s own discretion
- carte blanche: Unrestricted power to act at one’s own discretion
- The colon character separates the phrase from its translation
- The following code extracts the characters to the left of the colon:
int p = aLine.IndexOf(":");var phrase = aLine[..p];
- First, we find the position
pof the colon - Then we extract the characters starting at the beginning of the line, up to position
p - The result is added to a list
phraseLst, after removing any accents, umlauts, or other glyphs that aren’t present in English spelling - Next, we process the actor file and manipulate each name
- To separate the name into individual words, I use the split method to get the array
tokens - The first entry in
tokensis the first name; find the middle position by dividing length by 2, and insert ‘r’ at that positionvar p = (int)tokens[0].Length / 2;var first = tokens[0][..p] + "r" + tokens[0][(p)..];
- Now build the manipulated last name:
var last = tokens[^1][0..^2];- Note that
tokens[^1]extracts the entry counting backwards from the end, i.e. the last entry - The notation
[0..^2]means to take the letters starting at position 0, up to (exclusive) the 2nd from the end letter
- Finally, we check if the manipulated name is in our list, and if so, display it:
var newName = $"{first} {last}";- var ndx = phraseLst.IndexOf(newName);
Removing Diacritical Marks
static string RemoveDiacritics(string text) {
var normalizedString = text.Normalize(NormalizationForm.FormD);
var stringBuilder = new StringBuilder(capacity: normalizedString.Length);
for (int i = 0; i < normalizedString.Length; i++) {
char c = normalizedString[i];
var unicodeCategory = CharUnicodeInfo.GetUnicodeCategory(c);
if (unicodeCategory != UnicodeCategory.NonSpacingMark) {
stringBuilder.Append(c);
}
}
return stringBuilder
.ToString()
.Normalize(NormalizationForm.FormC);
}
For the sake of strict honesty, I copied this code from a post on Stack Overflow, so I’m not an expert on what it does. Note that the key method invoked is the ‘Normalize‘ method, which converts to a particular form of Unicode.
Note that FormD “Indicates that a Unicode string is normalized using full canonical decomposition, followed by the replacement of sequences with their primary composites, if possible.”
Code to Get More Actor Names
private async void btnGetMoreActors_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
//Load the existing text file containing actors, into a list 'actorList'
var fName = @"C:\Users\Randy\Documents\Puzzles\Data\Actors\Actors.txt";
var actorList = new List<string>();
using (var sr = new StreamReader(File.OpenRead(fName))) {
while (sr.Peek() != -1) {
var aLine = (sr.ReadLine() ?? "");
actorList.Add(aLine);
}
}
var addedCount = 0;
//By running the following code asynchronously, the UI remains responsive
//and we can update the progress bar
await Task.Run(async () => {
//IMDB has 10 pages of 100 actors each page, loop through them
var baseUrl =
@"https://www.imdb.com/list/ls058011111/?sort=list_order,asc&mode=detail&page={0}";
for (var i = 1; i <= 10; i++) {
//The url takes a page number parameter; inject it into the base url:
var url = string.Format(baseUrl, i);
var allText = "";
using (var cl = new HttpClient())
allText = await cl.GetStringAsync(url);
//Make an instance of the main object in the HtmlAgilityPack library
var hDoc = new HtmlDocument();
hDoc.LoadHtml(allText);
//Use XPath to find a list of nodes which are
// 1) children of h3 elements
// 2) if said h3 element has class 'lister-item-header
// 3) and if said child is an 'a' element (anchor, i.e. link)
var actorLinks =
hDoc.DocumentNode.SelectNodes("//h3[@class='lister-item-header']/a");
//There should be 100 matches, we will grab the 'InnerText' of each
foreach (var anchor in actorLinks) {
//Clean-up the actor name and check if it is in the existing list:
var actor = anchor.InnerText.Replace("\\n", "").Trim();
var ndx = actorList.BinarySearch(actor);
//we found a new actor when ndx < 0
if (ndx < 0) {
Console.WriteLine(actor);
//Insert the actor at the correct alphabetical index:
actorList.Insert(~ndx, actor);
Dispatcher.Invoke(() => txtMessage.Text = $"Added {actor}");
addedCount++;
}
}
//Update progress bar
Dispatcher.Invoke(() => prg.Value = 100F * (float)i / 10F);
}
});
txtMessage.Text = $"Added {addedCount} actors; writing file";
if (addedCount > 0) {
//Update the file with new entries
using(StreamWriter sw = new StreamWriter(File.Create(fName))) {
foreach (var actor in actorList)
sw.WriteLine(actor);
}
}
txtMessage.Text = "Done!";
Mouse.OverrideCursor = null;
}
As you might guess, I had to get more actors because my original list was deficient. I got my original list from Wikipedia, which sometimes has some challenges organizing lists. Happily, IMDB has an enhanced list which I added to my file.
Code Highlights
- First, we read the existing file and build a list ‘actorList’, using standard techniques
- Note that IMDB has 10 pages of actor names; each page can be retrieved by setting a URL parameter named ”page”
- For example, the 3rd age can be retrieved with this url:
- So, my code loops from page 1 to page 10, each pass fetching the next page by number
- The following two lines read the page into a string variable, using the URL created above:
using (var cl = new HttpClient())allText = await cl.GetStringAsync(url);
- Next, we load the text into the HtmlAgilityPack main object, the HtmlDocument:
var hDoc = new HtmlDocument();hDoc.LoadHtml(allText);
- Now we can use XPath to find the nodes containing the actor names:
var actorLinks = hDoc.DocumentNode.SelectNodes("//h3[@class='lister-item-header']/a");- The XPath code effectively says to
- Find h3 elements
- Having class ‘
lister-item-header‘ (because this is the name of the CSS class that IMDB created to decorate these elements with; I know this because I inspected the page source) - Having found such an h3 element, selecting the
achild node (‘a‘ stands for ‘anchor’, i.e. a link)
- Next, we iterate each entry in the IEnumerable ‘
actorLinks‘; for each, we extract the InnerText and process it.
Get the Code!
Here’s a link to my code on DropBox; note that you will need a (free) DropBox account to access it.
Sunday Puzzle, May 1, 2022
Manipulate a Number Name to get Another number
This week’s challenge is more challenging than last week’s. Write down the name of a number. Move each letter four spots later in the alphabet — so A would become E, B would become F, etc. The result will be a number that’s 44 more than your first one. What numbers are these?
Link to the challenge
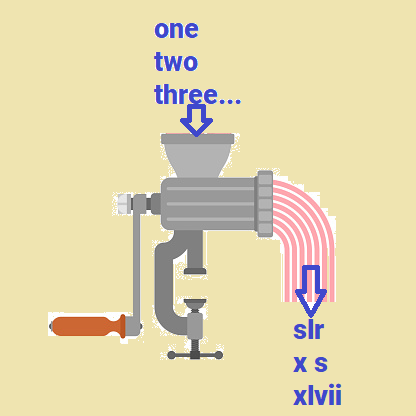
Discussion
This time I decided to create a WPF solution using Visual Studio. Manipulating the number names was pretty easy, but finding the correct inputs was a lot harder. I had to think of quite a few different ways of representing number names, including Spanish, German, leet and Roman Numerals. Thankfully, I found the solution before I had to resort to Pig-Latin!
This time, instead of explaining the code in text, I made a short movie of the code in action, in a debug session. The reason being that the movie should be easier to understand, in part because I can show the values of variables and demonstrate little blocks of code in the Immediate Pane.
Techniques Used
- File Handling
- String manipulation
- Binary Search
- Sorting lists in .NET
- Simple classes
- StringBuilder
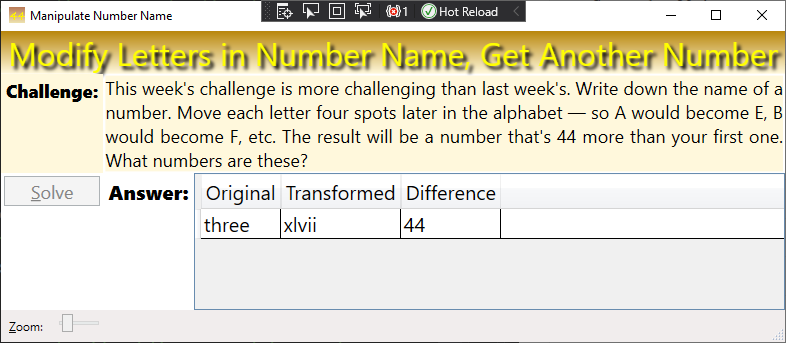
Link to the Video Clip
Hmm, it seems I have to post a link here (instead of directly embedding my video) because I don’t have a Pro account. Here’s my little video! Note that you’ll need a free DropBox account to download it. I hope you learn a couple tricks about using the Visual Studio debugger from watching my video.
Download my Code
Here’s a link to my code. Again, you’ll need a free DropBox account to retrieve that link. My data file of number-names is included in that zip file; the file name is “NumberNames.txt”.
Additional Comments
- Writing the code to solve the puzzle was pretty easy. The hard part was figuring out all the different ways to represent number names. I’ll step out on a limb and predict that very few people will send a solution to Will this week.
- One thing I didn’t address in my video is why I bothered to use a Binary search to solve the puzzle, after all, the list of number-names is so short that the speed increase is almost undetectable. In case you wondered why, the answer is:
- I’m familiar enough with this technique that it only took me a minute to set up the
IComparerclass. Compared to Python, binary searches are easy in .NET! - My default is to write code to be efficient, unless doing so makes it hard to read, and Binary Search is quite efficient
- I thought someone might be interested to learn how to do this in .NET
- I’m familiar enough with this technique that it only took me a minute to set up the
Here’s My Code
Since I can’t embed my video directly, here’s the code. First is the “code-behind” for the main from. Below that, I will list my little class to hold instances of NumberNames.
usingSystem.Collections.Generic; using System.IO; using System.Text; using System.Windows; using System.Windows.Input; namespace Puzzle2022_05_01 { public partial class MainWindow : Window { public MainWindow() { InitializeComponent(); }/// This method fires when user clicks the 'Solve' button. /// 1) Loads a file of number names, /// 2) Manipulates each name according to the puzzle instructions. /// 3) If the manipulation results in a /// match against another number name, then compute the difference in /// the numbers to see if it meets the requirements. private void btnSolve_Click(object sender, RoutedEventArgs e) { Mouse.OverrideCursor = Cursors.Wait; btnSolve.IsEnabled = false; var fName = @"C:\Users\User\Documents\Puzzles\NumberNames.txt"; //1) Build a list 'numberLst' from the number names file: var numberLst = LoadNumberNamesFromFile(fName); //This object controls which property (field) is used to perform //the comparison, namely, the 'Name' property var comp = new NumberNameComp(); //Sorting is necessary to enable the binary search below: numberLst.Sort(comp); //This list will be bound to the the datagrid which users views var displayLst = new List(); //Now iterate the list, manipulate each name, and //search the list for the manipulation result foreach(var aNumber in numberLst) { //2) Manipulate the original number name: var manipulatedName = ManipulateName(aNumber.Name); //3) Search the list for an entry matching manipulated name whose // difference is 44: if (MeetsCriteria(manipulatedName, aNumber.Number, numberLst)) { //Build something to display in the grid: var display = new NumberName { Name = manipulatedName, Orig = aNumber.Name, Difference = 44 }; displayLst.Add(display); } } lblAnswer.Visibility = Visibility.Visible; grdResults.ItemsSource = displayLst; grdResults.Visibility = Visibility.Visible; Mouse.OverrideCursor = null; }/// This method opens the file, reads each line, converts the /// contents into a NumberName object, and inserts it /// into a list to return private List LoadNumberNamesFromFile(string fName) { var result = new List(); using (var sr = new StreamReader(File.OpenRead(fName))) { while (sr.Peek() != -1) { var aLine = sr.ReadLine(); var p = aLine.IndexOf("="); var addMe = new NumberName { Number = long.Parse(aLine.Substring(0, p - 1)), Name = aLine.Substring(p + 2).ToLower() }; result.Add(addMe); } } return result; }/// This method manipulates the name by adding 4 to each letter, /// except for hyphens and spaces /// For example, 'three' or 'thirteen' /// The manipulated name, such as 'xlvii' private string ManipulateName(string theName) { var result = new StringBuilder(); foreach (var ltr in theName) { //Add 4 unless the character is hyphen or space char nextLtr = (ltr == '-' || ltr == ' ') ? ltr : (char)(ltr + 4); result.Append(nextLtr); } return result.ToString(); }/// This method returns true if the manipulated name matches an entry the list, /// and if the difference is 44 private bool MeetsCriteria(string manipulatedName, long origNumber, List numberLst) { bool result = false; var comp = new NumberNameComp(); var findMe = new NumberName { Name = manipulatedName }; //3) Searche the var ndx = numberLst.BinarySearch(findMe, comp); if (ndx >= 0) { //If binarysearch succeded, ndx will be non-negative, //so compute the difference var diff = numberLst[ndx].Number - origNumber; //The puzzle criteria demands a difference of 44, this entry //is the solution if (diff == 44) result = true; } return result; } } }
public class NumberName {
/// <summary>The numeric value of the number, used to compute difference</summary>
public long Number { get; set; }
/// <summary>The transformed name of the number, such as xvlii</summary>
public string Name { get; set; }
/// <summary>The original number name, such sa 'three'</summary>
public string Orig { get; set; }
/// <summary>Holds the difference between the original number and the transformed number</summary>
public long Difference { get; set; }
/// <summary>
/// Displays the number, particularly when using the debugger
/// </summary>
/// <returns></returns>
public override string ToString() {
return $"{Number}, {Name}";
}
}
/// <summary>
/// A class dedicated to comparing two instances of the NumberName class
/// by their name
/// </summary>
/// <remarks>
/// An instance of this class is used for sorting the a list of NumberName
/// instances, and for performing BinarySearch on such a list
/// </remarks>
public class NumberNameComp : IComparer<NumberName> {
public int Compare(NumberName x, NumberName y) {
return string.Compare(x.Name, y.Name);
}
}
Sunday Puzzle April 24, 2022
Animal Sound to Color
This week’s challenge comes from listener Jeff Balch, of Evanston, Ill. Name a sound made by a certain animal. Change one letter in it to the next letter of the alphabet, and you’ll get a color associated with that animal. What’s the sound, and what’s the color?
Link to the challenge

Discussion
This was a super easy one. I was able to get a list of color names from Wikipedia and a list of animal sounds from a site called ‘VisualDictionary.org‘. I actually solved it just by glancing at the list of sounds, but elected to write the code for fun.
- File handling
- String manipulation
- Loops
- Indexing strings
Python Methods Used
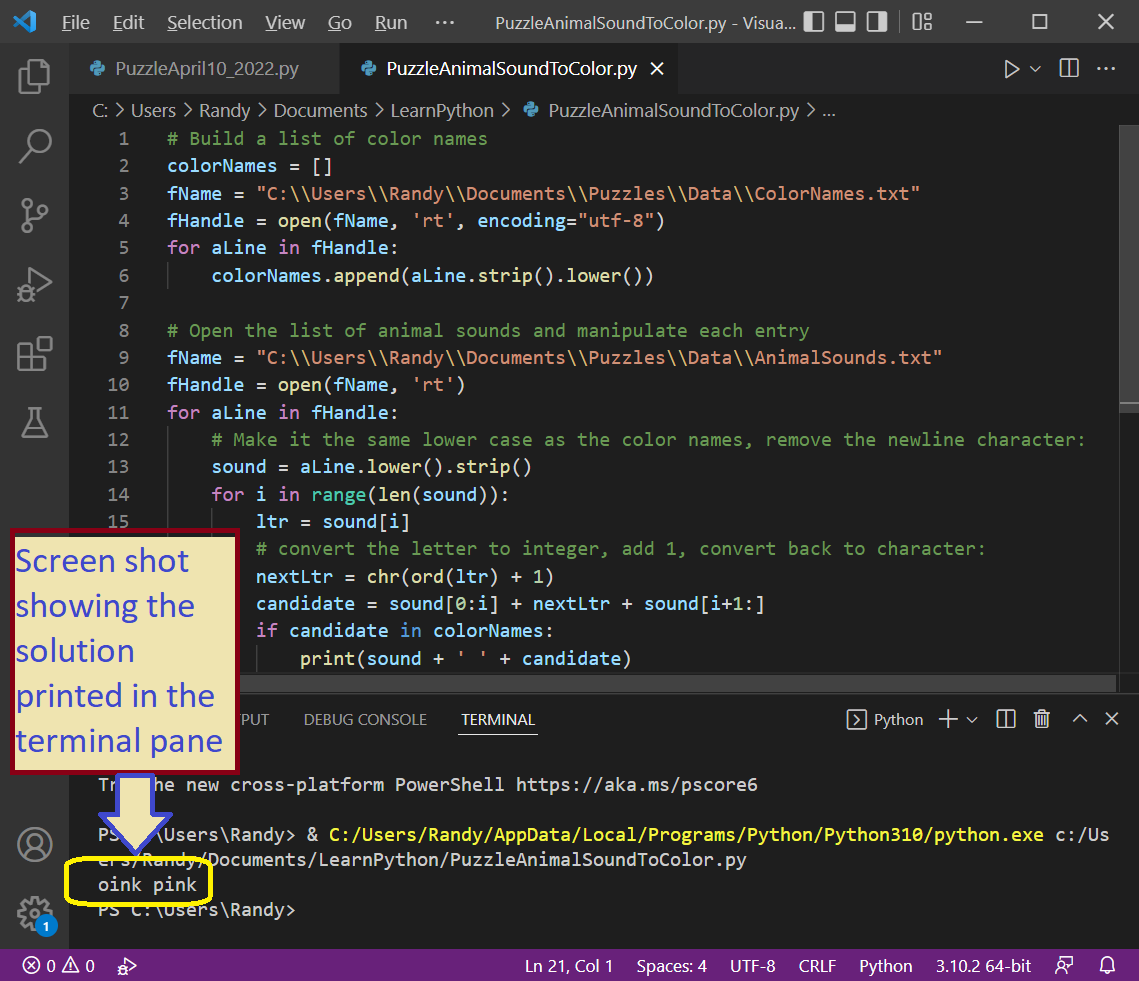
Here’s the Code
# Build a list of color names
colorNames = []
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\ColorNames.txt"
fHandle = open(fName, 'rt', encoding="utf-8")
for aLine in fHandle:
colorNames.append(aLine.strip().lower())
# Open the list of animal sounds and manipulate each entry
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\AnimalSounds.txt"
fHandle = open(fName, 'rt')
for aLine in fHandle:
# Make it the same lower case as the color names, remove the newline character:
sound = aLine.lower().strip()
for i in range(len(sound)):
ltr = sound[i]
# convert the letter to integer, add 1, convert back to character:
nextLtr = chr(ord(ltr) + 1)
candidate = sound[0:i] + nextLtr + sound[i+1:]
if candidate in colorNames:
print(sound + ' ' + candidate)
A Few Comments
The basic algorithm is:
- Load the color names, from file, into a
listcalled ‘colorNames‘ - Open the animal sounds file and process each line: for aLine in fHandle:
- We will build candidate words that might be colors, but in order to check if a candidate matches a color in the list, we need to make sure the candidate is the same case as the list, i.e. lower case. Remember, two strings are different if they use different case, for example, ‘Pink’ ≠ ‘pink’
- Also, when we read a line, the end-of-line marker is embedded in the string, so we use ‘strip’ to clean it out. The following code does both things in one line: sound = aLine.lower().strip()
- Every time we read a line from the animal sounds file, we loop through the letters in that sound
- This code does that:
for i in range(len(sound)): - We use indexing to grab each letter ltr = sound[i]
- The instructions state: “Change one letter in it to the next letter of the alphabet”,
- We do that with nextLtr = chr(ord(ltr) + 1)
- ‘Ord’ converts a character to its numeric representation. For example,
- ord(‘o’) = 111
- ord(‘p’) = 112
- ord(‘i’) = 105
- ‘chr’ converts the number back into a letter. The line of code above does the following conversions:
- ord(‘o’) = 111
- 111 + 1 = 112
- chr(112) = ‘p’
- Now that we have manipulated the letter to get the next letter in the alphabet, we build a candidate color name by concatenating the first part of the animal sound, the manipulated letter, and the last part of the word: candidate = sound[0:i] + nextLtr + sound[i+1:]
- Finally, we check if our candidate is actually a color name by seeing whether it exists in our list: if candidate in colorNames:
Summary
The code works because there is only one sound that maps to a color name, so I don’t need to check whether the color is “associated with that animal”. The basic algorithm is to load the color names into a list, loop through the sounds file, manipulating each sound to make a candidate which we evaluate by checking if it is in our list.
Since the code is so short, I don’t have a download this time. Just copy the code above if you want to play with it.
