
Month: April 2022
Sunday Puzzle April 24, 2022
Animal Sound to Color
This week’s challenge comes from listener Jeff Balch, of Evanston, Ill. Name a sound made by a certain animal. Change one letter in it to the next letter of the alphabet, and you’ll get a color associated with that animal. What’s the sound, and what’s the color?
Link to the challenge

Discussion
This was a super easy one. I was able to get a list of color names from Wikipedia and a list of animal sounds from a site called ‘VisualDictionary.org‘. I actually solved it just by glancing at the list of sounds, but elected to write the code for fun.
- File handling
- String manipulation
- Loops
- Indexing strings
Python Methods Used
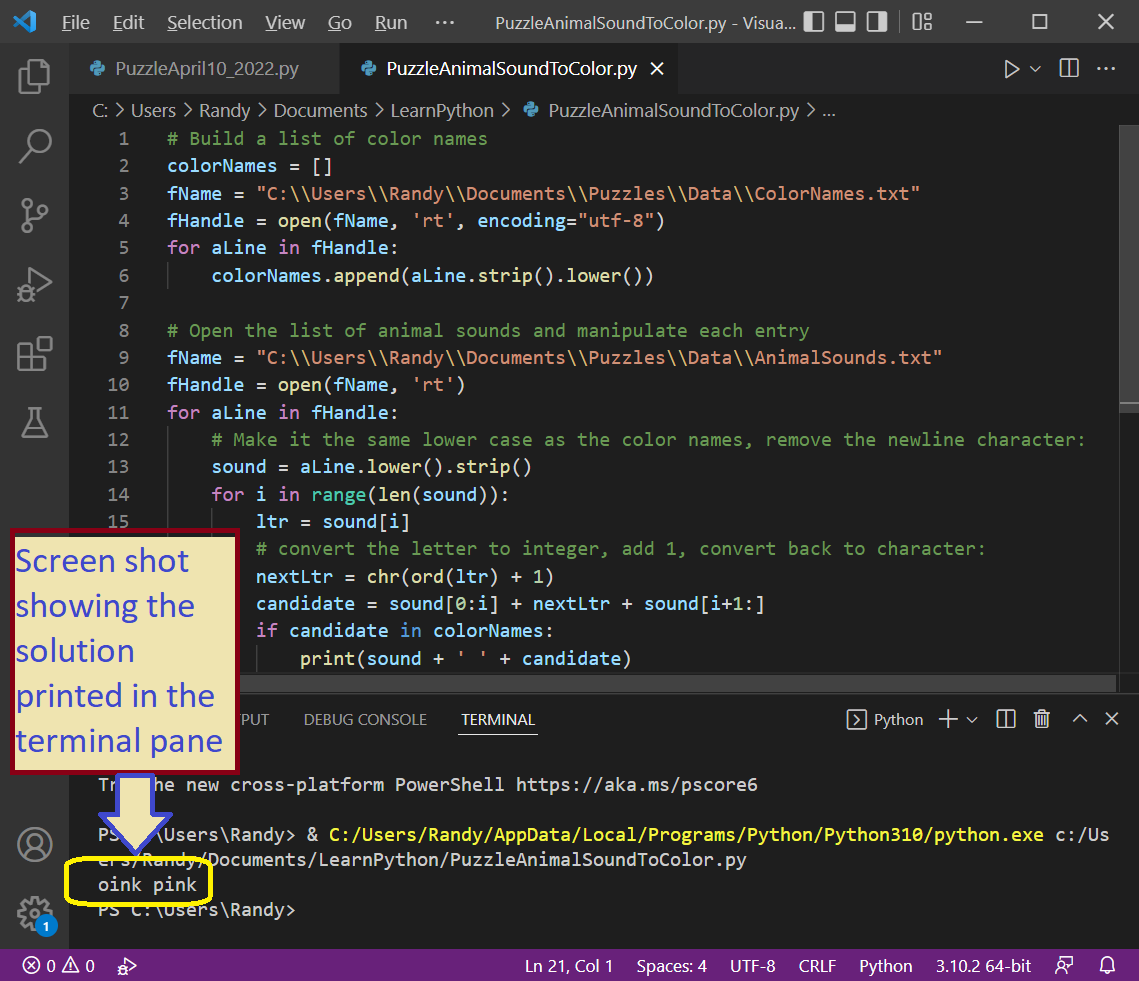
Here’s the Code
# Build a list of color names
colorNames = []
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\ColorNames.txt"
fHandle = open(fName, 'rt', encoding="utf-8")
for aLine in fHandle:
colorNames.append(aLine.strip().lower())
# Open the list of animal sounds and manipulate each entry
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\AnimalSounds.txt"
fHandle = open(fName, 'rt')
for aLine in fHandle:
# Make it the same lower case as the color names, remove the newline character:
sound = aLine.lower().strip()
for i in range(len(sound)):
ltr = sound[i]
# convert the letter to integer, add 1, convert back to character:
nextLtr = chr(ord(ltr) + 1)
candidate = sound[0:i] + nextLtr + sound[i+1:]
if candidate in colorNames:
print(sound + ' ' + candidate)
A Few Comments
The basic algorithm is:
- Load the color names, from file, into a
listcalled ‘colorNames‘ - Open the animal sounds file and process each line: for aLine in fHandle:
- We will build candidate words that might be colors, but in order to check if a candidate matches a color in the list, we need to make sure the candidate is the same case as the list, i.e. lower case. Remember, two strings are different if they use different case, for example, ‘Pink’ ≠ ‘pink’
- Also, when we read a line, the end-of-line marker is embedded in the string, so we use ‘strip’ to clean it out. The following code does both things in one line: sound = aLine.lower().strip()
- Every time we read a line from the animal sounds file, we loop through the letters in that sound
- This code does that:
for i in range(len(sound)): - We use indexing to grab each letter ltr = sound[i]
- The instructions state: “Change one letter in it to the next letter of the alphabet”,
- We do that with nextLtr = chr(ord(ltr) + 1)
- ‘Ord’ converts a character to its numeric representation. For example,
- ord(‘o’) = 111
- ord(‘p’) = 112
- ord(‘i’) = 105
- ‘chr’ converts the number back into a letter. The line of code above does the following conversions:
- ord(‘o’) = 111
- 111 + 1 = 112
- chr(112) = ‘p’
- Now that we have manipulated the letter to get the next letter in the alphabet, we build a candidate color name by concatenating the first part of the animal sound, the manipulated letter, and the last part of the word: candidate = sound[0:i] + nextLtr + sound[i+1:]
- Finally, we check if our candidate is actually a color name by seeing whether it exists in our list: if candidate in colorNames:
Summary
The code works because there is only one sound that maps to a color name, so I don’t need to check whether the color is “associated with that animal”. The basic algorithm is to load the color names into a list, loop through the sounds file, manipulating each sound to make a candidate which we evaluate by checking if it is in our list.
Since the code is so short, I don’t have a download this time. Just copy the code above if you want to play with it.
Sunday Puzzle for April 10, 2022
Add Letters to a Word Twice to Get New Words with/without Silent ‘L’
This week’s challenge comes from listener Ari Ofsevit, of Boston. Think of a 5-letter word with an “L” that is pronounced. Add a letter at the start to get a 6-letter word in which the “L” is silent. Then add a new letter in the fifth position to get a 7-letter word in which the “L” is pronounced again. What words are these?
Link to the challenge on the NPR website

Discussion
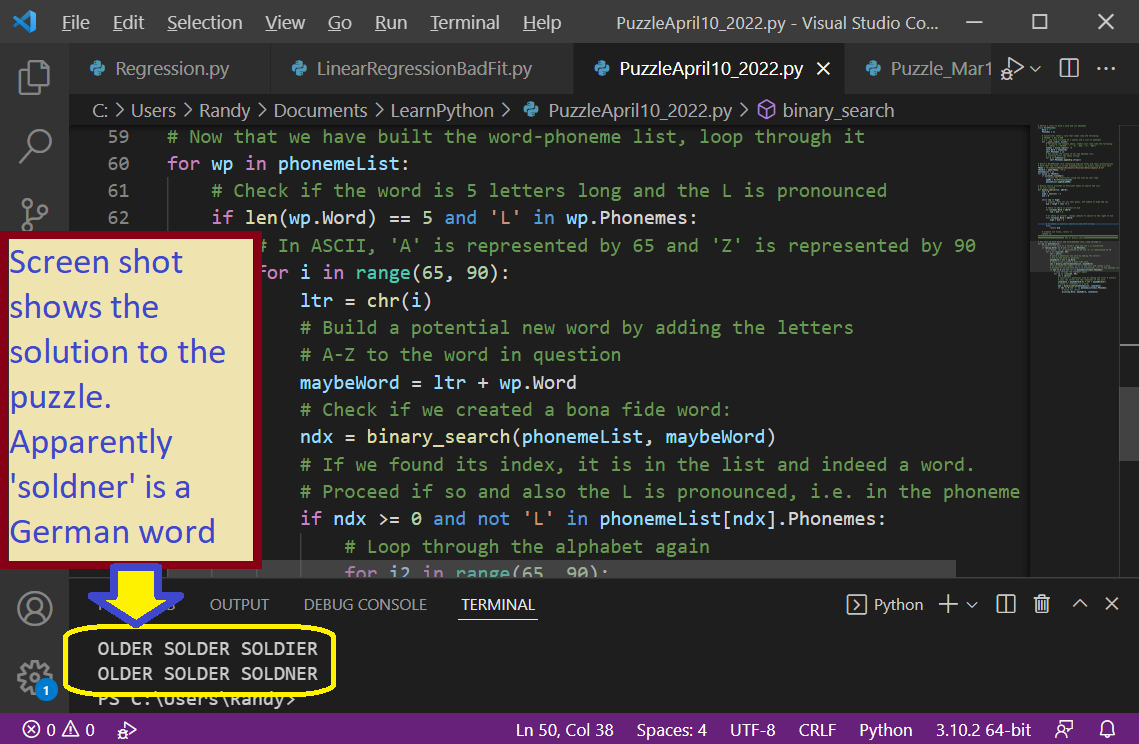
That’s a fun little puzzle, and one I suspect is a lot easier if you can write code. I love saying “Older Solder Soldier“! The puzzle can be solved if you have a list of English words and their phonemes. A phoneme is the smallest phonetic unit in a language that is capable of conveying a distinction in meaning, as the m of mat and the b of bat in English.
I use the phoneme list to determine if the ‘L’ is silent. For example, consider the following 3 words and their phonemes:
- OLDER OW1 L D ER0
- SOLDER S AA1 D ER0
- SOLDIER S OW1 L JH ER0
Note that the phoneme list for ‘older‘ contains an ‘L’, so it is pronounced. But the phoneme list for ‘solder‘ does not contain an ‘L’, so it is silent. Again, ‘soldier‘ contains an ‘L’, so it is pronounced.
Programming Techniques to Solve
- File handling
- String manipulation
- Binary search
- Classes
- Simple ranges
- General logic and looping
Code Synopsis
- Build a list of words and their associated phonemes
- Iterate the list, seeking 5-letter words containing an L
- For each such list entry, add a letter at the beginning of the word, for example:
- ‘s’ + older → solder
- If the result is a bona fide word with a silent ‘L’,
- Then add another letter at position 5, for example:
- ‘sold’ + i + ‘er’ → soldier
- If the result is a bona fide word word a pronounced ‘L’, print the result
- Then add another letter at position 5, for example:
- For each such list entry, add a letter at the beginning of the word, for example:

You can download a list of phonemes from Github
Code: A Class to Hold a Word/Phoneme Pair
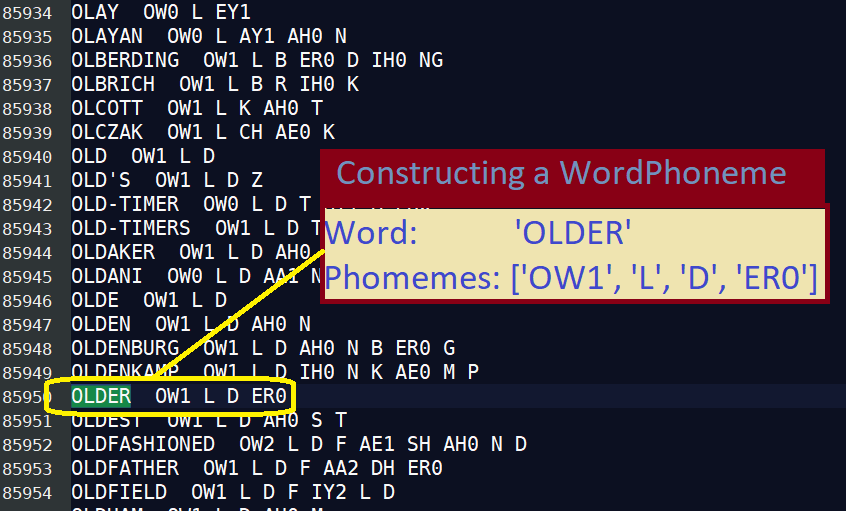
I want a list of words and their associated phonemes. My list will hold members of a class I call ‘WordPhoneme‘, defined below:
class WordPhoneme:
Word = ""
Phonemes = []
# Constructor takes a line that looks like the following:
# SOLDER S AA1 D ER0
# I.e. the word followed by 2 spaces, then a list of phonemes
def __init__(self, aLine):
# Following the example above, tokens will look like the following:
# tokens = ['SOLDER', '', 'S', 'AA1', 'D', 'ER0']
tokens = aLine.rsplit(" ")
self.Word = tokens[0]
self.Phonemes = []
# Now assign the values to our new phoneme list,
# starting after the empty string:
for p in tokens[2:]:
self.Phonemes.append(p.strip())
The class above has two properties: Word and Phonemes, i.e. a string and a list. The first two lines above define those two properties. The next lines define the constructor, which is responsible for initializing the class.
The constructor takes a parameter ‘aLine‘ which represents a line of code from the file. All we have to do is split that line using a built-in function called ‘rsplit‘ that gives us a list with one entry for each distinct string of characters in the line.
rsplitneeds a delimiter, such as a space, comma, slash, etc. I specify a space because that is what separates the tokens in the file- The result is a list, as noted in my code comment above
- We grab the first entry (
tokens[0]) and shove it into ourWordproperty - And then grab the remainder of the tokens for our
Phonemeslist- Examine the following line of code:
for p in tokens[2:]:
- Remember that the first entry in token list has index 0, so we can reference it with
tokens[0] - But we already grabbed the first token (the word), and the next token is a space, so we want to skip it too
- That tells us we need to we start at index 2 and take the remainder of the tokens. Using range indexing, we could have (for example) specified [2:3] to get the tokens at index 2 and 3, but my code doesn’t specify the end index, we instead get the remainder of the line using “
[2:]” for the index. - Refer to this article explaining range indexing in python
- Examine the following line of code:

Now, let’s open the file of phonemes and make a list of WordPhoneme pairs.
Code: Build the List of WordPhoneme Pairs by Reading the File
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\cmudict.0.7a"
fHandle = open(fName, 'rt')
phonemeList = []
for aLine in fHandle:
if aLine[0].isalpha():
# Invoke the constructor using the line we just read
addMe = WordPhoneme(aLine)
phonemeList.append(addMe)
Observe the file name in variable ‘fName‘; I use double slashes ‘\\’ instead of slashes. This is necessary because a single slash is a special character that normally modifies the following character, but a double slash is interpreted as just a slash. A single slash starts an escape character sequence. Note that my file is text, but for some reason doesn’t have a file extension “.txt”.
- The
openstatement takes a string parameter ‘rt’, meaning open it for Read, Text. - The following line checks if the line we read starts with a letter:
if aLine[0].isalpha():
- I need to do this because the top of the file contains documentation and those lines start with something other than a letter, typically a semicolon
- The following line invokes the class constructor, discussed above:
- addMe = WordPhoneme(aLine)
Great news! After executing this code, we now have a list of WordPhoneme pairs. Next, we define a binary search method.
Binary Search
Binary search is an extremely efficient way to search a list. That is important when searching a big list. Since I discussed this code before (NPR Puzzle February 5, 2022), I will only list the code and not discuss the algorithm.

def binary_search(lst, aWord):
low = 0
high = len(lst) - 1
mid = 0
while low <= high:
# Compute index 'mid' for our next guess, the middle of high and low
mid = (high + low) >> 1
# Check if aWord is present at mid
if lst[mid].Word < aWord:
low = mid + 1
# If aWord is greater, so search to the right of mid
elif lst[mid].Word > aWord:
high = mid - 1
# aWord is smaller, so search to the left of mid
else:
return mid
# element not found, return -1
return -1
Now that we have a method to perform a binary search, we will use it to search our list of WordPhoneme pairs. We need to search because we are creating strings that might or might not be legitimate words; if the search comes up dry, then we know the string is not a word.
Code to Solve!
So far, we have built a list of WordPhonemes and defined a Binary Search method. Now we use them to solve.
# Now that we have built the word-phoneme list, loop through it for wp in phonemeList: # Check if the word is 5 letters long and the L is pronounced if len(wp.Word) == 5 and 'L' in wp.Phonemes: # In ASCII, 'A' is represented by 65 and 'Z' is represented by 90 for i in range(65, 90): ltr = chr(i) # Build a potential new word by adding the letters # A-Z to the word in question. Each loop pass adds a successive letter maybeWord = ltr + wp.Word # Check if we created a bona fide word: ndx = binary_search(phonemeList, maybeWord) # If we found its index, it is in the list and indeed a word. # Proceed if so and also the L is pronounced, i.e. in the phoneme list if ndx >= 0 and not 'L' in phonemeList[ndx].Phonemes: # Loop through the alphabet again for i2 in range(65, 90): ltr = chr(i2) # Construct a potential word by taking the first 4 letters # plus the letter and the remainder of the word candidate = maybeWord[0:4] + ltr + maybeWord[4:] # Check if candidate is a word: ndx = binary_search(phonemeList, candidate) if ndx >= 0 and 'L' in phonemeList[ndx].Phonemes: # Print our result print(wp.Word, maybeWord, candidate)
Analysis
Below I list some interesting lines of code from above and discuss what they do.
if len(wp.Word) == 5 and 'L' in wp.Phonemes:- The puzzle says we start with a 5-letter word, so first we check the length of the
Wordproperty of theWordPhoneme - If the letter ‘L’ is present in the phoneme list for the
WordPhoneme, that means the L is not silent
- The puzzle says we start with a 5-letter word, so first we check the length of the
for i in range(65, 90):- This code says start a loop where variable i holds values starting at 65 and goes up to 90
- This is because the ASCII code represents letters as numbers ‘behind the scenes’, so we can easily convert the number to a character. Here’s some examples of the ASCII representation of letters:
- ‘A’ = 65
- ‘B’ = 66
- ‘C’ = 67
- …
- ‘Z’ = 90
ltr = chr(i)- This line of code makes a character from a number. For example, it converts 65 to ‘A’.
maybeWord = ltr + wp.Word- Here I construct a string by prepending a letter to the
Wordin theWordPhoneme, for example:- ‘A’ + ‘OLDER’ = ‘AOLDER’
- ‘B’ + ‘OLDER’ = ‘BOLDER’
- …
- ‘S’ + ‘OLDER’ = ‘SOLDER’
- Here I construct a string by prepending a letter to the
ndx = binary_search(phonemeList, maybeWord)- Search the list for
maybeWord
- Search the list for
if ndx >= 0 and not 'L' in phonemeList[ndx].Phonemes:ndxis the index, in our list, where we found the word we searched for- If the word is not in our list, ndx has value -1
- For example, ‘OLDER’ is located at index 85,826, because there are 85,825 entries before it
- Note the 2nd part if the if statement:
and not 'L' in phonemeList[ndx].Phonemes:
- In other words, the ‘L’ is silent, because it is not present in the phoneme list
candidate = maybeWord[0:4] + ltr + maybeWord[4:]- Just to review, at this point in code, we have started with a 5-letter word with a pronounced ‘L’, added a letter to the start of the word, tested the result to see if it is a word and also a word with a silent ‘L’. Now we construct a 3rd string
- My 3rd string (
candidate) takes the first 4 letters ofmaybeWord, adds the loop variable ltr, then finally adds the remainder ofmaybeWord
ndx = binary_search(phonemeList, candidate)- Check if
candidateis a bona fide word by searching our list
- Check if
if ndx >= 0 and 'L' in phonemeList[ndx].Phonemes:- This code checks that the
candidateis present in the list and has a pronounced ‘L’. Ifcandidatepasses that test, we have a winner! Ding! Ding! Ding!
- This code checks that the
Code Summary
My program is 42 lines of code and 42 lines of comments or blank lines. That’s pretty short! Of course, you need a special file of phonemes to solve it, so thank you to the folks at Carnegie Mellon University who created and released this file.
The code works because we can create strings that might be words and search our list to see if they are found in that list, and also because we can determine if the ‘L’ is silent by whether an ‘L’ is present in the phoneme list for the word we are working with.
Get the Code
You can download the code here, from my Dropbox account. Note that you will need to create a free account to do so.
