
Sunday Puzzle for May 15, 2022
Manipulate an Actor Name to get a French Phrase
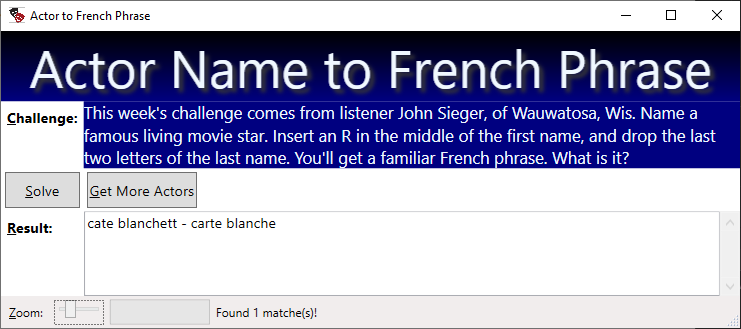
This week’s challenge comes from listener John Sieger, of Wauwatosa, Wis. Name a famous living movie star. Insert an R in the middle of the first name, and drop the last two letters of the last name. You’ll get a familiar French phrase. What is it?
Link to the challenge

Techniques Used
- File handling
- Text processing, including manipulation of Unicode characters
- Screen scraping with HtmlAgilityPack
- XPath
- String manipulation
- Simple async operations
Synopsis
Note: I originally published this a few days ago as a Page; I should have published it as a Post, because, for whatever reason, WordPress makes it really hard to find pages. So I have republished it hear as a page.
This one was a bit harder than normal; after struggling with my original actor list, I had to augment it, and finding lists of French phrases was hard. In interests of full disclosure, I had to try a few things that aren’t shown in my published code to get it to work. Specifically, I had to convert the actor names into French words, then inspect the output and check if any looked like a French phrase, because “carte blanche” wasn’t in any list I found. After I inspected my output, I added carte blanche to my list of phrases.
But the good news is now I get to show off some elementary usage of the outstanding HtmlAgilityPack library, which allows you to process web pages using XPath, making it possible to find text on a page that matches certain HTML markup patterns. In this case, links (a elements) which are children of h3 header elements having a particular class attribute.
For language choice, I once again used .NET/WPF, one reason being I am pretty good at screen scraping in .NET, also because I know how to remove diacritical marks from text using .NET. I had to screen-scrape the IMDB site to get more actors, and the french phrases contain lots of non-ASCII characters (i.e. diacritical marks) that I needed to compare against the manipulated actor names. I’m better at both those tasks in .NET compared to Python.
Here’s the Code!
First, Code That Solves the Puzzle
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
var fName = @"C:\Users\Randy\Documents\Puzzles\Data\Actors\FrenchPhrases.txt";
var phraseLst = new List<string>();
//Open the French Phrases file, read each line,
//remove diacritics, add to list 'phraseList'
using (var sr = new StreamReader(File.OpenRead(fName))) {
while (sr.Peek() != -1) {
var aLine = (sr.ReadLine() ?? "").ToLower();
int p = aLine.IndexOf(":");
var phrase = aLine[..p];
//The method 'RemoveDiacritics' is listed below
phraseLst.Add(RemoveDiacritics(phrase));
}
}
//Now process the actors file; manipulate each name and see if
//the result matches an entry on our list 'phraseList'
var solutionCount = 0;
fName = @"C:\Users\Randy\Documents\Puzzles\Data\Actors\Actors.txt";
using (var sr = new StreamReader(File.OpenRead(fName))) {
while (sr.Peek() != -1) {
var aLine = (sr.ReadLine() ?? "").ToLower(); ;
var tokens = aLine.Split(' ', StringSplitOptions.RemoveEmptyEntries);
if (tokens.Length > 1) {
//Find the middle index of the first name
var p = (int)tokens[0].Length / 2;
//Inject an 'r' at the middle index
var first = tokens[0][..p] + "r" + tokens[0][(p)..];
//Check if the last name has enough letters to trim the last two
if (tokens[^1].Length > 3) {
//Remove the last 2 letters:
var last = tokens[^1][0..^2];
var newName = $"{first} {last}";
//Check if the transformed name is in the list:
var ndx = phraseLst.IndexOf(newName);
//Display the result(s)
if (ndx >= 0) {
txtResults.Text += $"{aLine} - {phraseLst[ndx]}\n";
solutionCount++;
}
}
}
}
}
if (solutionCount > 0)
txtMessage.Text = $"Found {solutionCount} matche(s)!";
Mouse.OverrideCursor = null;
}
Code Highlights
- Using standard file handling techniques, open the file containing the phrases
- Each line in that file looks like the following example:carte blanche: Unrestricted power to act at one’s own discretion
- carte blanche: Unrestricted power to act at one’s own discretion
- The colon character separates the phrase from its translation
- The following code extracts the characters to the left of the colon:
int p = aLine.IndexOf(":");var phrase = aLine[..p];
- First, we find the position
pof the colon - Then we extract the characters starting at the beginning of the line, up to position
p - The result is added to a list
phraseLst, after removing any accents, umlauts, or other glyphs that aren’t present in English spelling - Next, we process the actor file and manipulate each name
- To separate the name into individual words, I use the split method to get the array
tokens - The first entry in
tokensis the first name; find the middle position by dividing length by 2, and insert ‘r’ at that positionvar p = (int)tokens[0].Length / 2;var first = tokens[0][..p] + "r" + tokens[0][(p)..];
- Now build the manipulated last name:
var last = tokens[^1][0..^2];- Note that
tokens[^1]extracts the entry counting backwards from the end, i.e. the last entry - The notation
[0..^2]means to take the letters starting at position 0, up to (exclusive) the 2nd from the end letter
- Finally, we check if the manipulated name is in our list, and if so, display it:
var newName = $"{first} {last}";- var ndx = phraseLst.IndexOf(newName);
Removing Diacritical Marks
static string RemoveDiacritics(string text) {
var normalizedString = text.Normalize(NormalizationForm.FormD);
var stringBuilder = new StringBuilder(capacity: normalizedString.Length);
for (int i = 0; i < normalizedString.Length; i++) {
char c = normalizedString[i];
var unicodeCategory = CharUnicodeInfo.GetUnicodeCategory(c);
if (unicodeCategory != UnicodeCategory.NonSpacingMark) {
stringBuilder.Append(c);
}
}
return stringBuilder
.ToString()
.Normalize(NormalizationForm.FormC);
}
For the sake of strict honesty, I copied this code from a post on Stack Overflow, so I’m not an expert on what it does. Note that the key method invoked is the ‘Normalize‘ method, which converts to a particular form of Unicode.
Note that FormD “Indicates that a Unicode string is normalized using full canonical decomposition, followed by the replacement of sequences with their primary composites, if possible.”
Code to Get More Actor Names
private async void btnGetMoreActors_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
//Load the existing text file containing actors, into a list 'actorList'
var fName = @"C:\Users\Randy\Documents\Puzzles\Data\Actors\Actors.txt";
var actorList = new List<string>();
using (var sr = new StreamReader(File.OpenRead(fName))) {
while (sr.Peek() != -1) {
var aLine = (sr.ReadLine() ?? "");
actorList.Add(aLine);
}
}
var addedCount = 0;
//By running the following code asynchronously, the UI remains responsive
//and we can update the progress bar
await Task.Run(async () => {
//IMDB has 10 pages of 100 actors each page, loop through them
var baseUrl =
@"https://www.imdb.com/list/ls058011111/?sort=list_order,asc&mode=detail&page={0}";
for (var i = 1; i <= 10; i++) {
//The url takes a page number parameter; inject it into the base url:
var url = string.Format(baseUrl, i);
var allText = "";
using (var cl = new HttpClient())
allText = await cl.GetStringAsync(url);
//Make an instance of the main object in the HtmlAgilityPack library
var hDoc = new HtmlDocument();
hDoc.LoadHtml(allText);
//Use XPath to find a list of nodes which are
// 1) children of h3 elements
// 2) if said h3 element has class 'lister-item-header
// 3) and if said child is an 'a' element (anchor, i.e. link)
var actorLinks =
hDoc.DocumentNode.SelectNodes("//h3[@class='lister-item-header']/a");
//There should be 100 matches, we will grab the 'InnerText' of each
foreach (var anchor in actorLinks) {
//Clean-up the actor name and check if it is in the existing list:
var actor = anchor.InnerText.Replace("\\n", "").Trim();
var ndx = actorList.BinarySearch(actor);
//we found a new actor when ndx < 0
if (ndx < 0) {
Console.WriteLine(actor);
//Insert the actor at the correct alphabetical index:
actorList.Insert(~ndx, actor);
Dispatcher.Invoke(() => txtMessage.Text = $"Added {actor}");
addedCount++;
}
}
//Update progress bar
Dispatcher.Invoke(() => prg.Value = 100F * (float)i / 10F);
}
});
txtMessage.Text = $"Added {addedCount} actors; writing file";
if (addedCount > 0) {
//Update the file with new entries
using(StreamWriter sw = new StreamWriter(File.Create(fName))) {
foreach (var actor in actorList)
sw.WriteLine(actor);
}
}
txtMessage.Text = "Done!";
Mouse.OverrideCursor = null;
}
As you might guess, I had to get more actors because my original list was deficient. I got my original list from Wikipedia, which sometimes has some challenges organizing lists. Happily, IMDB has an enhanced list which I added to my file.
Code Highlights
- First, we read the existing file and build a list ‘actorList’, using standard techniques
- Note that IMDB has 10 pages of actor names; each page can be retrieved by setting a URL parameter named ”page”
- For example, the 3rd age can be retrieved with this url:
- So, my code loops from page 1 to page 10, each pass fetching the next page by number
- The following two lines read the page into a string variable, using the URL created above:
using (var cl = new HttpClient())allText = await cl.GetStringAsync(url);
- Next, we load the text into the HtmlAgilityPack main object, the HtmlDocument:
var hDoc = new HtmlDocument();hDoc.LoadHtml(allText);
- Now we can use XPath to find the nodes containing the actor names:
var actorLinks = hDoc.DocumentNode.SelectNodes("//h3[@class='lister-item-header']/a");- The XPath code effectively says to
- Find h3 elements
- Having class ‘
lister-item-header‘ (because this is the name of the CSS class that IMDB created to decorate these elements with; I know this because I inspected the page source) - Having found such an h3 element, selecting the
achild node (‘a‘ stands for ‘anchor’, i.e. a link)
- Next, we iterate each entry in the IEnumerable ‘
actorLinks‘; for each, we extract the InnerText and process it.
Get the Code!
Here’s a link to my code on DropBox; note that you will need a (free) DropBox account to access it.
