
file handling
Sunday Puzzle April 24, 2022
Animal Sound to Color
This week’s challenge comes from listener Jeff Balch, of Evanston, Ill. Name a sound made by a certain animal. Change one letter in it to the next letter of the alphabet, and you’ll get a color associated with that animal. What’s the sound, and what’s the color?
Link to the challenge

Discussion
This was a super easy one. I was able to get a list of color names from Wikipedia and a list of animal sounds from a site called ‘VisualDictionary.org‘. I actually solved it just by glancing at the list of sounds, but elected to write the code for fun.
- File handling
- String manipulation
- Loops
- Indexing strings
Python Methods Used
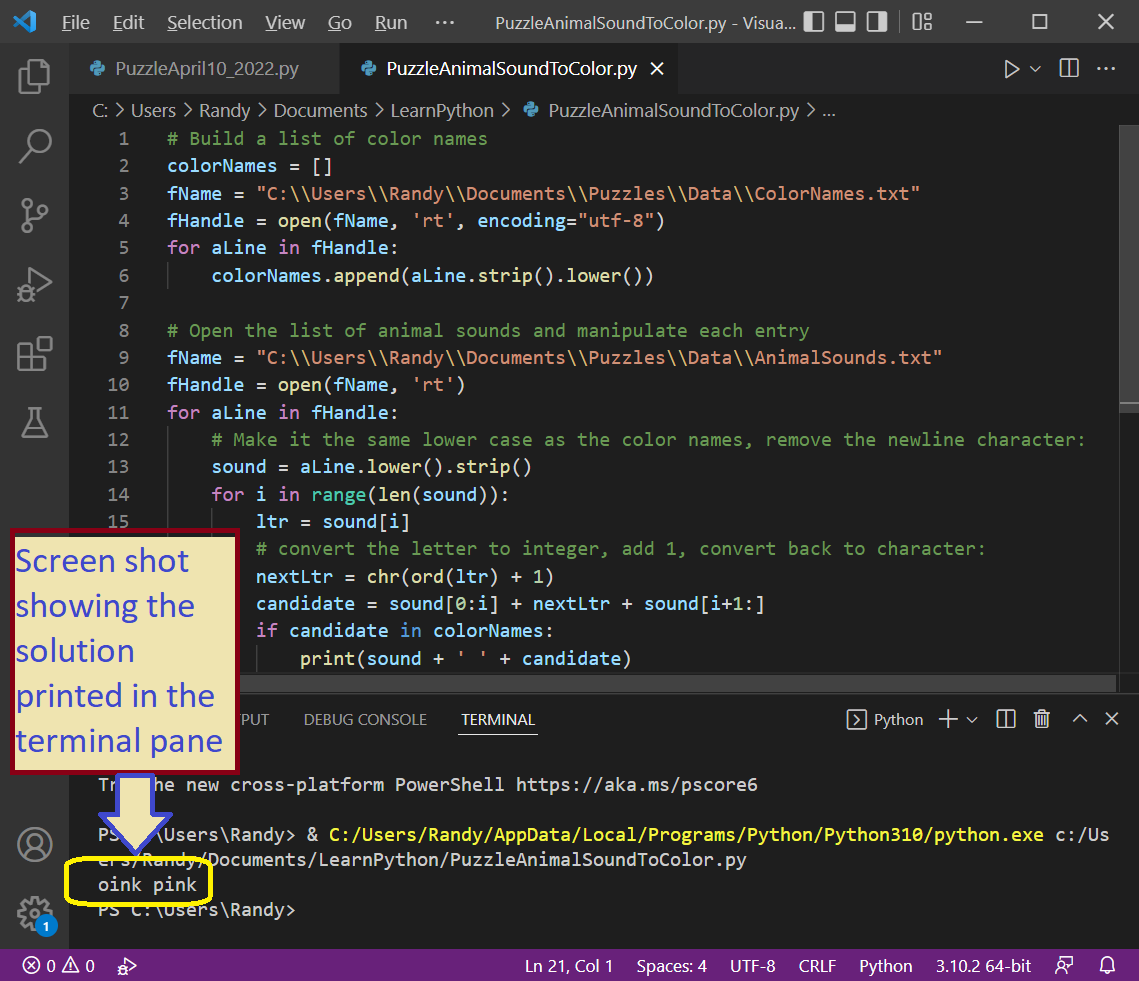
Here’s the Code
# Build a list of color names
colorNames = []
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\ColorNames.txt"
fHandle = open(fName, 'rt', encoding="utf-8")
for aLine in fHandle:
colorNames.append(aLine.strip().lower())
# Open the list of animal sounds and manipulate each entry
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\AnimalSounds.txt"
fHandle = open(fName, 'rt')
for aLine in fHandle:
# Make it the same lower case as the color names, remove the newline character:
sound = aLine.lower().strip()
for i in range(len(sound)):
ltr = sound[i]
# convert the letter to integer, add 1, convert back to character:
nextLtr = chr(ord(ltr) + 1)
candidate = sound[0:i] + nextLtr + sound[i+1:]
if candidate in colorNames:
print(sound + ' ' + candidate)
A Few Comments
The basic algorithm is:
- Load the color names, from file, into a
listcalled ‘colorNames‘ - Open the animal sounds file and process each line: for aLine in fHandle:
- We will build candidate words that might be colors, but in order to check if a candidate matches a color in the list, we need to make sure the candidate is the same case as the list, i.e. lower case. Remember, two strings are different if they use different case, for example, ‘Pink’ ≠ ‘pink’
- Also, when we read a line, the end-of-line marker is embedded in the string, so we use ‘strip’ to clean it out. The following code does both things in one line: sound = aLine.lower().strip()
- Every time we read a line from the animal sounds file, we loop through the letters in that sound
- This code does that:
for i in range(len(sound)): - We use indexing to grab each letter ltr = sound[i]
- The instructions state: “Change one letter in it to the next letter of the alphabet”,
- We do that with nextLtr = chr(ord(ltr) + 1)
- ‘Ord’ converts a character to its numeric representation. For example,
- ord(‘o’) = 111
- ord(‘p’) = 112
- ord(‘i’) = 105
- ‘chr’ converts the number back into a letter. The line of code above does the following conversions:
- ord(‘o’) = 111
- 111 + 1 = 112
- chr(112) = ‘p’
- Now that we have manipulated the letter to get the next letter in the alphabet, we build a candidate color name by concatenating the first part of the animal sound, the manipulated letter, and the last part of the word: candidate = sound[0:i] + nextLtr + sound[i+1:]
- Finally, we check if our candidate is actually a color name by seeing whether it exists in our list: if candidate in colorNames:
Summary
The code works because there is only one sound that maps to a color name, so I don’t need to check whether the color is “associated with that animal”. The basic algorithm is to load the color names into a list, loop through the sounds file, manipulating each sound to make a candidate which we evaluate by checking if it is in our list.
Since the code is so short, I don’t have a download this time. Just copy the code above if you want to play with it.
Sunday Puzzle for March 13, 2022
Manipulate Words from a Common Phrase Containing ‘in the’
This week’s challenge comes from Tyler Hinman, of San Francisco. He’s the reigning champion of the American Crossword Puzzle Tournament, which is coming up again on April 1-3. Think of two four-letter words that complete the phrase “_ in the _.” Move the first letter of the second word to the start of the first word. You’ll get two synonyms. What are they?
Link to the challenge

Discussion
The code to solve the puzzle was easy. Getting the list of phrases was tough! Eventually, I built up a list of over 10,000 common phrases and used it to solve the puzzle. Once again, I elected to use python.
Skills and Techniques to Solve
- File handling
- String manipulation
Again, the code is quite short, just 57 lines, including 16 comment lines

Code Discussion
For simplicity, I will show the key code, saving 3 things for later:
- Building a list of English words called ‘wordLst’
- Defining a method ‘GetPriorWord’
- Defining another method ‘GetNextWord’
Here is the important, key word, skipping the three items above:
fName = 'C:\\Users\\Randy\\Documents\\Puzzles\\Data\\CommonPhrases.txt'
fHandle = open(fName, 'rt', encoding="utf8")
# Read each line in the file (about 10,000) and process lines containing ' in the '
for aLine in fHandle:
p = aLine.find(' in the ')
if p > 0:
#Remove trailing linefeed
fixed = aLine.strip()
previous = GetPriorWord(fixed, p)
if len(previous) == 4:
next = GetNextWord(fixed, p)
if len(next) == 4:
#At this point, we know both words have length 4,
#now manipulate them according to the instructions:
candidate1 = next[0] + previous
candidate2 = next[1:]
#if both candidates are valid words, print the result:
if candidate1 in wordLst and candidate2 in wordLst:
print(fixed, ' → ', candidate1, candidate2)First, we open the file with this code:
fHandle = open(fName, 'rt', encoding="utf8").
- ‘rt’ means ‘read’ ‘text’
- encoding=”utf8″ means expect and handle non-standard letters, like à la carte
Next, we loop through the lines in the file, we look for a line containing ‘in the’
p = aLine.find(' in the ')variable ‘p’ is the position where we find that substring; if not found, p will be -1. Only about 20 phrases qualify. Next, we get the words immediately before and immediately after the position where we found ‘in the’:
previous = GetPriorWord(fixed, p)
if len(previous) == 4:
next = GetNextWord(fixed, p)
if len(next) == 4:As discussed above, I will explain ‘GetPriorWord’ and ‘GetNextWord’ below. For now, the code above creates two variables holding the words we want, named ‘previous’ and ‘next’. If both have length 4, we proceed:
#At this point, we know both words have length 4,
#now manipulate them according to the instructions:
candidate1 = next[0] + previous
candidate2 = next[1:]
#if both candidates are valid words, print the result:
if candidate1 in wordLst and candidate2 in wordLst:
print(fixed, ' → ', candidate1, candidate2)‘candidate1’ is built by concatenating the first letter of next with previous. ‘candidate2’ is every letter following the first. If both are in my list of words ‘wordLst’, then we have a solution. Note that only one phrase matches this, so I didn’t write code to determine whether they are synonyms.
The Three Parts I Skipped Over
Here’s how I built wordLst:
# First load a list of English words
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\2of12inf.txt"
fHandle = open(fName, 'rt')
wordLst = []
for aWord in fHandle:
wordLst.append(aWord.strip())Here are the definitions of my two methods ‘GetPriorWord’ and ‘GetNextWord’:
#When given a position p in a string 'aLine', finds the word preceeding it
def GetPriorWord(aLine, p):
i = p - 1
while i >= 0 and aLine[i] != ' ':
i -= 1
result = ''
if i < p:
result = aLine[i + 1:p - i - 1]
return result
#When given a position p in string 'aLine, finds the word succeeding it
def GetNextWord(aLine, p):
i = p + 8
while i < len(aLine) and aLine[i].isalpha():
i += 1
result = ''
if i > p + 8:
result = aLine[p + 8:i]
return resultDownload My Code
You can download my solution, plus the phrase file, from my Dropbox account. You will need to create a free account with Dropbox to do so.
