
Puzzle Solving
Sunday Puzzle: Find a Word With a ‘T’ Pronounced as ‘ZH’
A tough one from listener Joe Becker, of Palo Alto, Calif. The “zh” sound can be spelled in many different ways in English — like the “s” in MEASURE; like the “g” in BEIGE; like the “z” in AZURE; like the “j” in MAHARAJAH; and like the “x” in LUXURY as some people pronounce it. The “zh” sound can also be spelled as a “t” in one instance. We know of only one common word this is true of, not counting its derivatives. What word is it?
Link to the challenge
Synopsis
Once again, a sweet easy one 😁. Easy because I happen to have the magic key to solving it: a phoneme dictionary! Carnegie Mellon University has released the CMU Pronunciation Dictionary. Because I have that dictionary, I solved it with just 49 lines of code. And most of those lines were infrastructure.
Definition
phoneme fō′nēm″ noun
- The smallest phonetic unit in a language that is capable of conveying a distinction in meaning, as the m of mat and the b of bat in English.
Their Dictionary is a File that Looks Like This
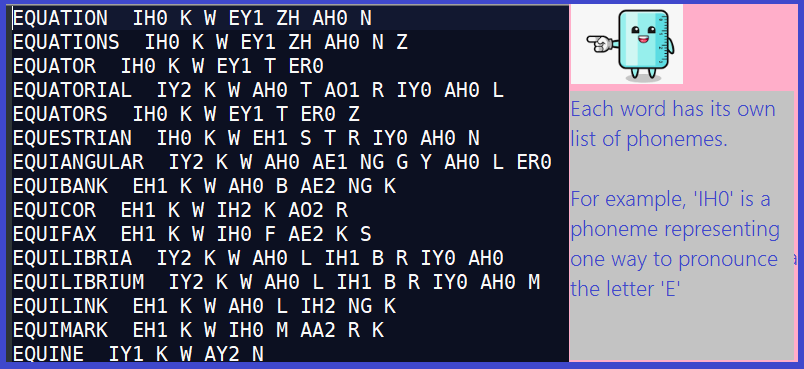
To solve the puzzle, we simply read this file and seek a word having a ‘ZH’ phoneme in the same position as a ‘T’ in the original word. Sounds simple? It basically is.

But there was a tricky part that I could only avoid because I got lucky. I’ll discuss it below!
While examining my code below, see if you can spot the assumption my code makes before I explain it.
I elected to use WPF (Windows Presentation Framework, a type of .NET solution) as the environment to solve the puzzle. Rationale: I need to process a file, so web solutions are out. WPF looks nice and .NET has a powerful set of string manipulation functions that I already know.

Techniques Used
- String manipulation
- File IO
- A tiny bit of Regular Expressions
Video Explaining the Code
Sometimes it’s more fun to watch a video than to read through code, so this time I made a video explaining it, here’s a link! It’s just 13 minutes long, and by watching, you may learn a couple tricks you can use in the debugger.
Here’s the Code!
Since the algorithm is so simple, I will just list my code. Note that numbered comments in the code correspond to explanations listed below.
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
txtResults.Clear();
// 1) Open the file for reading
using (var sr = File.OpenText(DICT_PATH)) {
string aLine = "";
// 2) Skip the top of the file, looking for a line
// which starts with a letter, which represents the file payload
while (sr.Peek() != -1) {
aLine = sr.ReadLine() ?? "";
if (aLine.Length > 0 && char.IsLetter(aLine[0]))
break;
}
while(true) {
// 3) Every word is separated from its phonemes by a double space
var p = aLine.IndexOf(" ");
if (p > 0) {
// 4) Every phoneme is separated by a space, build a list of them
var phonemes = aLine[(p + 2)..].Split(' ').ToList();
// 5) Find the index (if any) of the phoneme represented by 'ZH'
var zhPos = phonemes.IndexOf("ZH");
if (zhPos >= 0) {
// 6) Grab the word and strip off anything that looks lke '(2)'
var aWord = Regex.Replace(aLine[..p], @"\(\d\)", "");
// 7) Check if the index of 'T' is the same as the index of 'ZH'
if (zhPos < aWord.Length && aWord[zhPos] == 'T') {
txtResults.Text += $"Word: {aWord}, Phonemes: {aLine[(p + 2)..]}\n";
}
}
}
if (sr.Peek() == -1)
break;
aLine = sr.ReadLine() ?? "";
}
}
Mouse.OverrideCursor = null;
}
Comments Explained
- Open the file for reading. ‘DICT_PATH’ is a constant, defined above, holding the file path of the dictionary, such as “c:\cmudict.0.7a”. The variable
sris aStreamReaderthat can read a line of text. - Skip the top of the file, looking for a line which starts with a letter, which represents the file payload. Note that the first 121 lines of the file are comments and explanations, not part of the dictionary per se. Those lines start with a space or punctuation mark. Note that
aLine[0]represents the first character of the line (data typechar)- char.IsLetter is a built-in method that returns
truefor letters andfalseotherwise
- Every word is separated from its phonemes by a double space. For example, EQUATION IH0 K W EY1 ZH AH0 N. It might be hard to see, but there are two spaces after ‘EQUATION’. The variable
prepresents the position of the first space. Now we know where to find the end of the word, and the beginning of the phoneme list. - Every phoneme is separated by a space, build a list of them. There is a lot happening in this short line, let’s examine each carefully:
aLine[(p + 2)..]This code grabs a substring out of the original line, effectively the last half of the line, starting at the 2nd letter afterpand running to the end of the line. If the double space starts at position 10, then(p + 2), i.e. 12 is the starting position of everything after the double space.Split(' '). This built-in method builds an array out of the substring I gave it, splitting on the space character. Every time a space is encountered, we start a new entry in the array. If the input to split is “IH0 K W EY1 ZH AH0 N”, then the array will look like [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”]. Meaning that the first entry is “IH0” and the last is “N”.ToList(). This converts the array to a list. Why?ArraysandListsare very similar, but they don’t have the same methods available to them. In particular, I want to use the methodIndexOf, which is not available toarrays.
- Find the index (if any) of the phoneme represented by ‘ZH’. For our example array, [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”], the index will be 4, meaning we can access that entry with the line of code
phonemes[4]. If the list doesn’t have a ZH, then zhPos will be assigned -1. - Grab the word and strip off anything that looks lke ‘(2)’. Once again, there is a lot going on with this line:
aLine[..p]. Remember, p is the position where we found the double space. This code fragment grabs a substring starting at the beginning of the line, up to positionp.Regex.Replace. Regular expressions are a handy, but tricky, way to match patterns in strings. If you download and examine the CMU Phoneme dictionary, you will see some lines that look like the following:- ERNESTS ER1 N AH0 S T S
- ERNESTS(2) ER1 N AH0 S S
- ERNESTS(3) ER1 N AH0 S
- Note the two entries “(2)” and “(3)’. We want to replace these with an empty space, i.e., delete them.
Regex.Replacewill do that if we give it a string to start with, a pattern to match, and a replacement string (in our case, an empty string). @"\(\d\)"This is the pattern we will look for- @” means this string contains \ characters
\(represents an open parenthesis. Because ( is a specal character, we need to preface it with \ so that .NET will look for that character in the string, instead of starting a capture group. Capture groups are an advanced topic which we don’t need to understand today. There are a few special characters which we need to preface with \, so we can avoid confusion; the \ is called an escape character.\dThis is a pattern element signifying “capture any digit“, i.e., the characters 0-9- \) This represents the close parenthesis. As before, the backspace is used as an escape character.
- The upshot is that, if aLine contains “ERNESTS(2) ER1 N AH0 S S”, then
aWordwill be assigned “ERNESTS”, because we replaced (2) with “”
- Check if the index of ‘T’ is the same as the index of ‘ZH’. Note that, within the string ‘EQUATION’, ‘T’ has index 4 (remember, indexes start at 0, not at 1). Similarly, ‘ZH’ also has index 4 within the list [“IH0”, “K”, “W”, “EY1”, “ZH”, “AH0”, “N”]. Since the index is 4 in both, we are pretty confident that T is pronounced ‘ZH’ in the word equation.

The Tricky Part Explained!
You’ve now read my code. Have you managed to guess what I meant when I said I got lucky?
Answer: My code assumes that every letter in the original word is represented by a phoneme. But that isn’t actually true. Sometimes a pair of letters are used to make a sound, like the pair “sh”, “th”, or “ch”. I don’t know how many letter pairs are used that way, but it makes things complicated when you try to determine whether the letter ‘T’ is represented by the phoneme ‘ZH’ by determining that both are at position 4.
Since I found a good solution without taking this issue into account, and since dealing with it makes my blog entry a lot harder to understand, and since the whole thing is just for fun, I elected not to deal with the issue. Once again, I leave it as an exercise to the reader.
Get the Code
You can get a copy of my code from my dropbox account at this link. Note that you will need to create a free DropBox account to do so. Use the link above to get the CMU phoneme dictionary, and remember to revise my code to point to the file path on your machine.
Sunday Puzzle: Nationality, Demonyms and Consonyms!
This week’s challenge is a spinoff of my (e.g. Will’s) on-air puzzle. Name two countries that have consonyms that are nationalities of other countries. In each case, the consonants in the name of the country are the same consonants in the same order as those in the nationality of another country. No extra consonants can appear in either name. The letter Y isn’t used.
Link to the Challenge
Definition Demonym; noun: A name for an inhabitant or native of a specific place that is derived from the name of the place.
Synopsis
Well, that was a nice, easy, fun one! Happily, I already had a list of nations and their demonyms, so it was just a matter of making two lists and matching them against each other. Each of those two lists contains the original word plus its consonym. One list uses the country as the original word, the other uses nationality as the original word. We match the lists using the consonym.
I elected to use WPF once again, mainly because it produces a nice UI and I am pretty fast in it. The choice of UI is fairly unimportant for solving this puzzle, since there is almost no interaction with the user, other than clicking the Solve button.
If you read through to the end, I’ll explain my big learning moment writing this code. Yes, I made a big mistake because I misunderstood something tricky about Linq. Hopefully you can save time by learning from my goof!
In case anyone is following me, I hope I don’t sound too over-confident in my analysis, possibly discouraging you. I always do the write-up as if I knew what I was doing from the very start, as if solving the puzzle is inevitable due to my great skill 😏. But that is not the case at all! I have a lot of struggles and plenty of dead ends. So I hope you don’t feel unworthy if I accidentally make it sound easier than it truly is. Because in reality, it only seems easy after I finally succeed.
Screenshot Showing My Results:
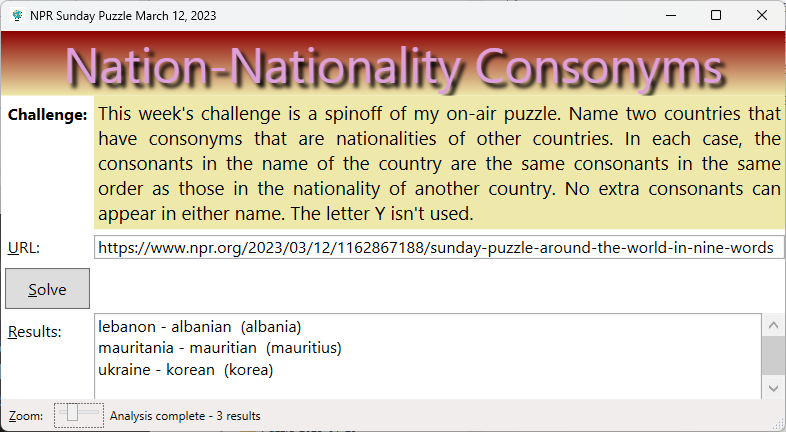
I got 3 results, but from Will’s description, I think he expects two results. I re-read his description a few times and don’t see anything I misinterpreted, so let’s see what he says come Sunday. Maybe there was some confusion over Mauritania and Mauritius, two very similar names.
Techniques Used
Difficulty Level
- Intermediate
- Dogged beginners
Algorithm
We start with a file that looks like the following (you can download your own copy below):
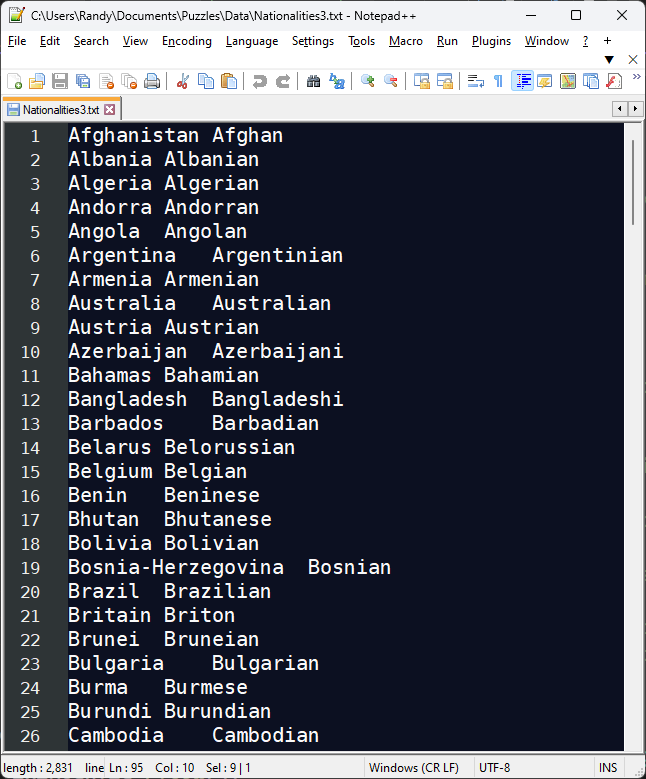
As you can see above, this file has two columns, separated by a tab character. The country comes first, followed by the demonym. Given this file structure, we take the following steps to find a solution:
- Open the file for reading
- Read one line at a time
- Split the line on the tab character, effectively separating the two words
- Build two lists,
- Using the two words from the line we just split
- One list for nationalities
- The other for demonyms
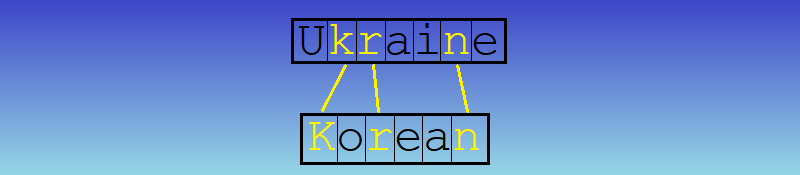
- Each list will contain a data type (a class in this case) which contains the original word and its consonym (refer to the image below)
- After we finish reading the file and building the list,
- Match the two lists using the consonym field
- Note that some countries will match against their own demonym, for example
- Britain → brtn → Briton (consonants “brtn” for both)
- Therefore, when we match the two lists, we need to avoid self-matching by requiring that the matched demonym not come from the original country
Illustration of Matching the Two Lists
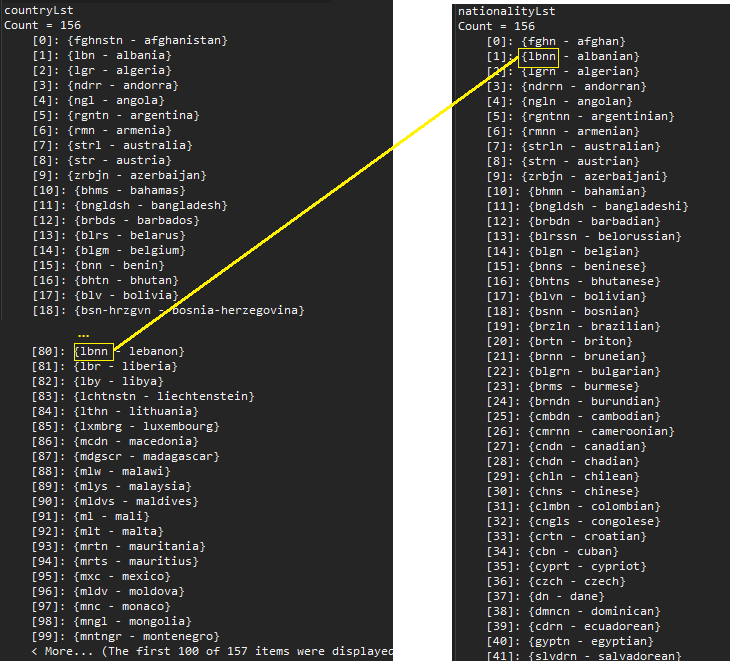
ConsonymWordPair , which consists of the consonants plus the original word. When we match entries on the left against those on the right, we find a match for “lbnn” in both lists. Now we know the two original words share a consonym, one word being a country and the other a nationality. Here’s The Code!
//This is the main method; it runs when user clicks the 'solve' button
private void btnSolve_Click(object sender, RoutedEventArgs e) {
txtResults.Clear();
txtMessage.Text = "";
//1) The subroutine (method) reads my file and builds the two lists:
var (countryLst, nationalityLst) = BuildCountryNationalityLists();
var solutionCount = 0;
//2) Loop through the country list and match against the nationality list
foreach (var c in countryLst) {
//3) Get all the nationalities whose Consonym matches the country's
var matches = nationalityLst.Where(n => n.Consonym == c.Consonym);
foreach (var m in matches) {
//4) 'Mate' is my term for the original country
//I call it 'Mate' to make the class name more generic
//If the country's consonym is the same as its nationalit's, skip it
if (m.Mate != c.Mate) {
//5) Display the results!
txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n";
solutionCount++;
}
}
}
txtMessage.Text = $"Analysis complete - {solutionCount} results";
}
Discussion – Main Method
🙆🏻I really like how short the main method is, it makes me feel good to write concise code that does something useful and, hopefully, something cool!
Numbered notes below correspond to the numbered comments above. If you already understand the code above, skip ahead to the next heading!
- The subroutine reads my file and builds the two lists
var (countryLst, nationalityLst) = BuildCountryNationalityLists();- That subroutine (‘
BuildCountryNationalityLists‘) is listed below - Note that this method returns two variables,
countryLstnationalityLst
- Which is one of my favorite features of .NET!
- Both lists contains
ConsonymWordPairelements (a class defined below)
- Loop through the country list and match against the nationality list
foreach (var c in countryLst) {- The variable ‘
c‘ is an instance of my class ‘ConsonymWordPair‘ - And we will examine all 156 of them, one per loop pass
- Get all the nationalities whose Consonym matches the country’s
- The Linq method
Wheredoes a search on the listnationalityLstvar matches = nationalityLst.Where(n => n.Consonym == c.Consonym);n.Consonymrefers to the nationality consonym- c
.Consonymrefers to the demonym consonym (say that 3 times fast!)
- And returns all the matches.
- Theoretically there could be more than one match, but not with this data
- The Linq method
- ‘Mate’ is my term for the original country
-
if (m.Mate != c.Mate) { - The class is named ‘
ConsonymWordPair‘, but I added an extra field ‘Mate'after naming it - So it isn’t really a pair any more 😑- whoops!
- The if-statement,
if (m.Mate != c.Mate)ensures that I don’t accidentally match, for example, Briton against Britain
-
- Display the results!
txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n";- That code appends a new solution to the textbox called ‘
txtResults‘ - The
+=operator causes the new string to be appended to the existing one - We build a string to append using the
$""nomenclature - This allows us to mix variables with text in a more natural way
- Variables are recognized inside the
{}brackets; everything else is plain text - Note that
\n(look at the end of the line) is how we specify a newline
Method ‘BuildCountryNationalityLists’
private (List<ConsonymWordPair>, List<ConsonymWordPair>) BuildCountryNationalityLists() {
//1) Build the two empty lists which we will populate and return:
var countryLst = new List<ConsonymWordPair>();
var nationalityLst = new List<ConsonymWordPair>();
//2) NATIONALITY_FILE is defined at the class-level; it is the file name
using var sr = File.OpenText(NATIONALITY_FILE);
//3) Read until end-of-file detected
while (sr.Peek() != -1) {
//4 Read the line, convert to lower case, split on tab character
//The split operation means that 'twain' is an array
var twain = sr.ReadLine().ToLower().Split('\t');
if (twain != null && twain.Length == 2) {
//5) twain[0] is the country name; build a pair with the
//word and its consonants
var c1 = RemoveVowels(twain[0]);
var cwp1 = new ConsonymWordPair(twain[0], c1, twain[0]);
countryLst.Add(cwp1);
//6) Now do the same for the nationality, which is in twain[1]:
var c2 = RemoveVowels(twain[1]);
var cwp2 = new ConsonymWordPair(twain[1], c2, twain[0]);
nationalityLst.Add(cwp2);
}
}
return (countryLst, nationalityLst);
}Discussion – BuildCountryNationalityLists
The method reads the file and builds two lists. As above, the list numbers below correspond to numbered comments above. The string operators used are ToLower and Split. The three File IO operators are File.OpenText, StreamReader.Peek and StreamRead.ReadLine. By putting this code in a separate method, the main method is simplified and easier to read.
- Build the two empty lists which we will populate and return
- Each list contains an instance of my class ‘
ConsonymWordPair‘
- Each list contains an instance of my class ‘
- NATIONALITY_FILE is defined at the class-level; it is the file name
- The variable
sris a StreamReader that can read a line at a time - The ‘
using‘ keyword guarantees that the stream will be closed and disposed
- The variable
- Read until end-of-file detected
- The StreamReader has a
Peekmethod that returns -1 whenEOFis detected, that terminates mywhile-loop
- The StreamReader has a
- Read the line, convert to lower case, split on tab character. The split operation means that ‘twain’ is an array
- I’m doing 3 things in this line:
var twain = sr.ReadLine().ToLower().Split('\t');
ReadLineshould be obviousToLowerconverts to lower case, so that I won’t try comparing ‘Lbnn’ against ‘lbnn’, because those two strings are not equal!- Split does what it says → it finds the tab character (\t) and splits the line every time it finds it
- The result is an array with two elements:
- Element 0: the country name (everything to the left of the tab)
- Element 1: And the nationality (everything to the right of the tab
- I’m doing 3 things in this line:
- twain[0] is the country name; build a pair with the word and its consonants
- The code below invokes my method
RemoveVowels, passing twain[i] as the inputvar c1 = RemoveVowels(twain[0]);
- For example, if the line was ‘Albania Albanian’
- Then twain[0] is ‘albania’ (note the lowercase ‘a’)
- The output from invoking
RemoveVowelsis ‘lbn’
- The code below invokes my method
- Now do the same for the nationality, which is in twain[1]:
- Following the example above,
twain[1]will be ‘albanian’ - The output from invoking RemoveVowels is ‘lbnn’
- Following the example above,
RemoveVowels Method
This method is really simple, so I won’t bore you with any unnecessary explanation. Here’s the code!
private string RemoveVowels(string input) {
//StringBuilder is easy to use and a more memory-efficient way to build a string
var result = new StringBuilder();
//Declare and initialize the array of char
var vowels = new[] { 'a', 'e', 'i', 'o', 'u' };
//Examine each char in the input string
foreach (var c in input)
if (!vowels.Contains(c))
result.Append(c);
return result.ToString();
}Class ‘ConsonymWordPair’
internal class ConsonymWordPair {
//1) My three public properties, the most important part of the class
public string Consonym { get; set; }
public string Word { get; set; }
public string Mate { get; set; }
//2) Default constructor
public ConsonymWordPair() {
Consonym = Word = Mate = "";
}
//3) 3-parameter constructor
public ConsonymWordPair(string newWord, string newConsonym, string newMate) : this() {
Word = newWord;
Consonym = newConsonym;
Mate = newMate;
}
public override string ToString() {
var result = $"{Consonym} - {Word}";
return result;
}
}Discussion – ConsonymWordPair
- My three public properties, the most important part of the class
- The remainder of the class is practically fluff
- As mentioned before, “pair” is not quite accurate any more, but “tuple” is harder to understand
- Default constructor
- Ensures that the public properties are initialized
- 3-parameter constructor
- The constructor used by the caller. Note that it actually invokes the default constructor with the code “
: this()“ - A pattern I try to follow which ensures the code in the default constructor is only written once
- The constructor used by the caller. Note that it actually invokes the default constructor with the code “
One other thing, the ToString method is not invoked when I solve the puzzle – so why did I write it? The answer is that Visual Studio uses it to display the list contents during debug sessions. When I hover my mouse over the pertinent variable (a list), it displays the contents using my method. Note that I built the image above (showing how the two lists are matched against each other) using the Immediate Pane in a debug session. Again, Visual Studio utilized my ToString method to display the data in that pane for me. Kind of the opposite of “immediate pain” 😉.
Lessons Learned
🙎🏼I made one big booboo writing this code: I used .NET’s Except method instead of my current method RemoveVowels. It didn’t work and I was surprised 😒! Except doesn’t work the way I thought it does, and I’ve been using it for years. I sure hope I didn’t create any bugs in production because of this.
Here’s some sample bad code that illustrates how I attempted to use Except:
var vowels = new[] { 'a', 'e', 'i', 'o', 'u' };
var twain = new[] {"albania", "albanian"};
var c1 = twain[0].Except(vowels).Aggregate("", (p,c) => p + c);
Console.WriteLine(c1);
var c2 = twain[1].Except(vowels).Aggregate("", (p,c) => p + c);
Console.WriteLine(c2);Can you guess what the output is for c2? I’ll keep you in suspense while I explain my code.
- Note that
twain[0]contains the string “albania” - When I invoke
Excepton it, passingvowelsas the input parameter, I get anIEnumerable<char>as the output (something like a list) that looks like the following:- ‘l’
- ‘b’
- ‘n’
- In other words, I get everything except the vowels. Just what we all expected.
- The code fragment
.Aggregate("", (p,c) => p + c)serves to create a string from the IEnumerable; basically it iterates the char elements and uses the+operator to concatenate them into a string
OK, now that I’ve explained how c1 is created, what do you think the value of c2 is? The code is the same for both, except the input for creating c2 is “albanian”. To my surprise, c1 is “lbn”. I expected “lbnn”, i.e. two n’s. .NET dropped one of my n’s.
What happened? Except works on IEnumerables, and I gave it a string, which .NET treated like a list of char. So far, so good. Reading the documentation, it doesn’t say anything about applying the Distinct operator, so all I can guess is that, under set operations, no one cares about preserving duplicates. Yes, I studied Set Theory in college, and I don’t remember anything like that, but it does seem somewhat consistent with how we did things then. So I don’t really know why it behaves that way, but now you know what to expect!
Efficiency Analysis
OK, my data file is only 156 lines long, and the code runs in just 7 milliseconds (according to .NET when running in debug mode, see below).
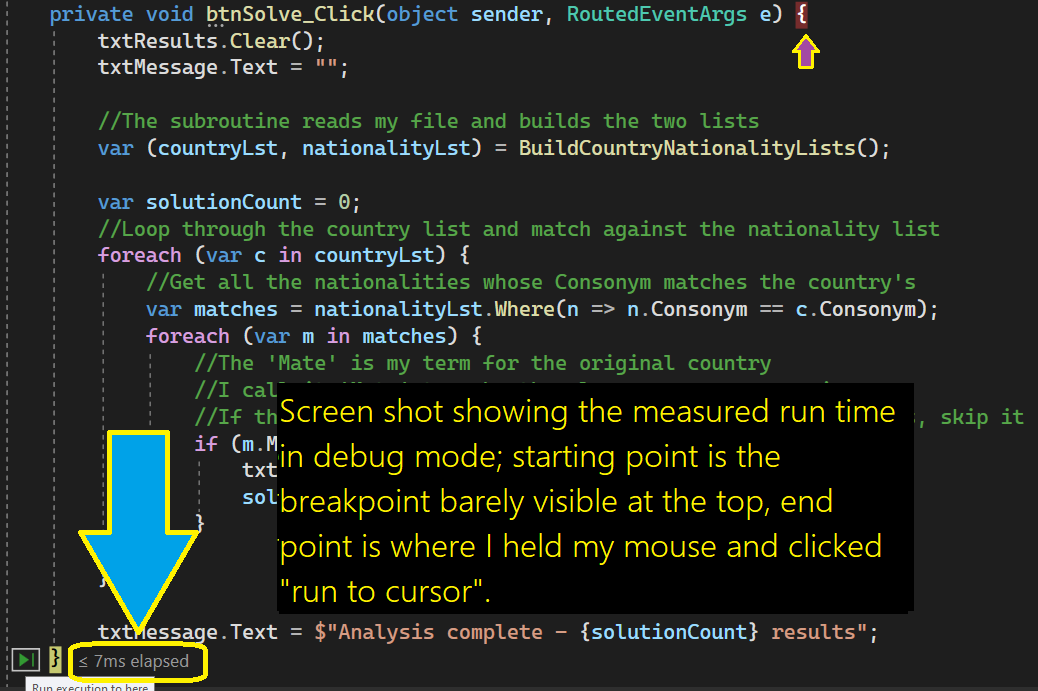
So, I must admit that we don’t care much about whether this code runs in 7 milliseconds, or 500 milliseconds – you’ve already burned thousands of milliseconds reading this😊 But it’s always good to understand the performance of your code, for one reason, it’s interesting!
The algorithm I used runs in O(n2), meaning that it first runs through the main list (the countries) and, for each pass through that list, makes another pass through the other list (nationalities), searching for a match. In this type of analysis, we ignore the fact that the 2nd search/array pass completes in an average of just half the array size; instead we focus on limiting behavior.
For our calculations, each pass in the first list means a pass through the second, so if the first array has length n, then the algorithm runs in n × n passes, or n2.
How to Improve Performance
I could have improved my performance by storing nationalities in a dictionary instead of a list. Note that .NET dictionaries use hashing instead of what I used, namely, a linear search. Hashing is much more efficient because we can determine whether some nationality exists in our dictionary in just O(1) run time, basically one calculation instead of examining the whole list. O(1) is generally the fastest possible run time.
By using a dictionary, my algorithm could have had a run time of O(n). Maybe that would shave a whole millisecond off my run time! I leave it as an exercise for the reader to make those sweet changes. Realistically, the bottleneck for this app is the file I/O, which typically runs 1000 times slower than memory calculations, though that won’t be anywhere near as bad if you have an SSD drive.
Improve Even More?
If we want to get ridiculous and shave off another millisecond, we can parallelize the main loop. That would also require that we use some sort of locking to make sure that different threads don’t update the display simultaneously and interfere with each other; either use of the lock keyword or else Dispatcher.Invoke.
The main loop would look like the following:
Parallel.ForEach(countryLst, (c) => {
var matches = nationalityLst.Where(n => n.Consonym == c.Consonym);
foreach (var m in matches) {
if (m.Mate != c.Mate) {
Dispatcher.Invoke(() => txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n");
solutionCount++;
}
}
});Since my PC has 20 cores, the code above would potentially run 20 times faster than my current main loop. Who knows what amazing things I could do with the time I saved using that technique! Seriously though, parallelization is a powerful tool for tackling certain difficult problems.
Download the Code
Here’s a copy of my code. If you choose to download it, remember to modify the file path (at the top of the code) to reference a location on your computer, not on mine. Here’s a copy of my nationalities file. You will need a free Dropbox account to download.
Sunday Puzzle May 22, 2022
Manipulate an Island Name to get Another Island
It’s an easyish one and comes from Blaine Deal, who conducts a weekly blog about Will’s NPR puzzles. Take the name of an island. Move its first letter two spaces later in the alphabet (so A would become C, B would become D, etc.). Reverse the result and you’ll have the name of another island. What islands are these?
Link to the challenge

Techniques Used
- String manipulation
- Simple file handling
- Linq methods ‘Aggregate’ and ‘Reverse’

Synopsis
Will was right, that was a pretty easy puzzle 😊. The hardest part about this one was building my island list. Eventually, I was able to use the list on Britannica.com, after manually editing their text for about half an hour.
After saving the result as a file, it was a simple matter of 1) reading that file into a list, 2) manipulating each list entry, and 3) checking whether the result was also an entry in that list.
Here’s the Code!
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
var islandLst = new List<string>();
//Read the file and put each line into the list declared above:
var fName = @"C:\Users\Randy\Documents\Puzzles\Data\Islands.txt";
using (var sr = File.OpenText(fName))
while (sr.Peek() != -1)
islandLst.Add(sr.ReadLine() ?? "");
foreach(var island in islandLst) {
//Manipulate the first letter and store the result in variable 'switched'
var switched = (char)(char.ToLower(island[0]) + 2) + island[1..];
//Reverse the letters and convert to a string:
var reversed = switched.Reverse().Aggregate("", (p,c) => p + c);
//Convert the first letter to upper case
var candidate = char.ToUpper(reversed[0]) + reversed[1..];
//Search the list for the result:
var ndx = islandLst.BinarySearch(candidate);
if (ndx >= 0)
//Display the results:
txtResult.Text += $"{island} - {islandLst[ndx]}\n";
}
Mouse.OverrideCursor = null;
}
Discussion
Here’s how I manipulate each entry in the islandLst to form a candidate to check. The lines highlighted above are discussed below:
var switched = (char)(char.ToLower(island[0]) + 2) + island[1..];
- Note that .NET allows you to treat a string variable as an
arrayofchar, so you can use indexing on that array. To wit,island[0]retrieves the first character from that array, at index 0
- .NET also allows you to perform arithmetic on
charvariables, so, ifcis a char variable, thenc + 2is a character moved up in the alphabet by two. So'g' + 2 = 'i', because i is two higher than g. However, the result is not achar, so I need to cast it back tocharbefore concatenating it with the remainder of the string. Casting is accomplished with the syntax(char), used as a prefix above.
- Note that .NET allows you to treat a string variable as an
var reversed = switched.Reverse().Aggregate("", (p,c) => p + c);
- ‘
Reverse()’ is aLinqmethod that builds anIEnumerable‘list’ of char in the reverse order of the original. I can use it on a string because, as mentioned above, astringis an array ofchar, andLinqcan operate on an array (because an array is an IEnumerable) - ‘
Aggregate‘ is anotherLinqmethod that has two parameters:- The initial/seed value to aggregate with, namely, an empty string “”
- A Lambda expression
(p,c) => p + cthat tells .NET how to perform the aggregation. My variable ‘p‘ represents the previous value (the results so far), and my variable ‘c‘ represents the current list entry being processed. Effectively, my code says “for each list entry, add it to the running output”
- Why use
Aggregate? Because, as mentioned above,Reversegives me a list (technically anIEnumerable), and I need to convert it to a string.
- ‘
var candidate = char.ToUpper(reversed[0]) + reversed[1..];
- Take the first char (reversed[0]) and convert it to upper case (
char.ToUpper) - Concatenate that with the remainder of the string (
reversed[1..]). Note that the plus sign + serves as a concatenation operator, and .NET allows you to concatenate acharto astring.
- Take the first char (reversed[0]) and convert it to upper case (
Finally, having built a candidate, I search the list again to see if that list actually contains the candidate.
var ndx = islandLst.BinarySearch(candidate);
If the binary search operation returns a non-negative number, it means we have a solution!
Get the Code
Here’s the link to get my code. Note that you will need a (free) DropBox account to access that link. The compressed file contains my island list, which you can use to solve the puzzle yourself.
Sunday Puzzle for April 10, 2022
Add Letters to a Word Twice to Get New Words with/without Silent ‘L’
This week’s challenge comes from listener Ari Ofsevit, of Boston. Think of a 5-letter word with an “L” that is pronounced. Add a letter at the start to get a 6-letter word in which the “L” is silent. Then add a new letter in the fifth position to get a 7-letter word in which the “L” is pronounced again. What words are these?
Link to the challenge on the NPR website

Discussion
That’s a fun little puzzle, and one I suspect is a lot easier if you can write code. I love saying “Older Solder Soldier“! The puzzle can be solved if you have a list of English words and their phonemes. A phoneme is the smallest phonetic unit in a language that is capable of conveying a distinction in meaning, as the m of mat and the b of bat in English.
I use the phoneme list to determine if the ‘L’ is silent. For example, consider the following 3 words and their phonemes:
- OLDER OW1 L D ER0
- SOLDER S AA1 D ER0
- SOLDIER S OW1 L JH ER0
Note that the phoneme list for ‘older‘ contains an ‘L’, so it is pronounced. But the phoneme list for ‘solder‘ does not contain an ‘L’, so it is silent. Again, ‘soldier‘ contains an ‘L’, so it is pronounced.
Programming Techniques to Solve
- File handling
- String manipulation
- Binary search
- Classes
- Simple ranges
- General logic and looping
Code Synopsis
- Build a list of words and their associated phonemes
- Iterate the list, seeking 5-letter words containing an L
- For each such list entry, add a letter at the beginning of the word, for example:
- ‘s’ + older → solder
- If the result is a bona fide word with a silent ‘L’,
- Then add another letter at position 5, for example:
- ‘sold’ + i + ‘er’ → soldier
- If the result is a bona fide word word a pronounced ‘L’, print the result
- Then add another letter at position 5, for example:
- For each such list entry, add a letter at the beginning of the word, for example:

You can download a list of phonemes from Github
Code: A Class to Hold a Word/Phoneme Pair
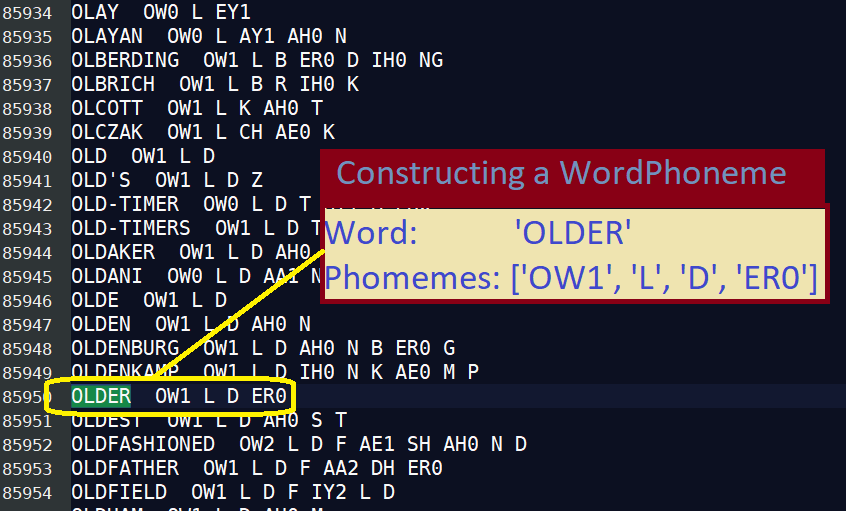
I want a list of words and their associated phonemes. My list will hold members of a class I call ‘WordPhoneme‘, defined below:
class WordPhoneme:
Word = ""
Phonemes = []
# Constructor takes a line that looks like the following:
# SOLDER S AA1 D ER0
# I.e. the word followed by 2 spaces, then a list of phonemes
def __init__(self, aLine):
# Following the example above, tokens will look like the following:
# tokens = ['SOLDER', '', 'S', 'AA1', 'D', 'ER0']
tokens = aLine.rsplit(" ")
self.Word = tokens[0]
self.Phonemes = []
# Now assign the values to our new phoneme list,
# starting after the empty string:
for p in tokens[2:]:
self.Phonemes.append(p.strip())
The class above has two properties: Word and Phonemes, i.e. a string and a list. The first two lines above define those two properties. The next lines define the constructor, which is responsible for initializing the class.
The constructor takes a parameter ‘aLine‘ which represents a line of code from the file. All we have to do is split that line using a built-in function called ‘rsplit‘ that gives us a list with one entry for each distinct string of characters in the line.
rsplitneeds a delimiter, such as a space, comma, slash, etc. I specify a space because that is what separates the tokens in the file- The result is a list, as noted in my code comment above
- We grab the first entry (
tokens[0]) and shove it into ourWordproperty - And then grab the remainder of the tokens for our
Phonemeslist- Examine the following line of code:
for p in tokens[2:]:
- Remember that the first entry in token list has index 0, so we can reference it with
tokens[0] - But we already grabbed the first token (the word), and the next token is a space, so we want to skip it too
- That tells us we need to we start at index 2 and take the remainder of the tokens. Using range indexing, we could have (for example) specified [2:3] to get the tokens at index 2 and 3, but my code doesn’t specify the end index, we instead get the remainder of the line using “
[2:]” for the index. - Refer to this article explaining range indexing in python
- Examine the following line of code:

Now, let’s open the file of phonemes and make a list of WordPhoneme pairs.
Code: Build the List of WordPhoneme Pairs by Reading the File
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\cmudict.0.7a"
fHandle = open(fName, 'rt')
phonemeList = []
for aLine in fHandle:
if aLine[0].isalpha():
# Invoke the constructor using the line we just read
addMe = WordPhoneme(aLine)
phonemeList.append(addMe)
Observe the file name in variable ‘fName‘; I use double slashes ‘\\’ instead of slashes. This is necessary because a single slash is a special character that normally modifies the following character, but a double slash is interpreted as just a slash. A single slash starts an escape character sequence. Note that my file is text, but for some reason doesn’t have a file extension “.txt”.
- The
openstatement takes a string parameter ‘rt’, meaning open it for Read, Text. - The following line checks if the line we read starts with a letter:
if aLine[0].isalpha():
- I need to do this because the top of the file contains documentation and those lines start with something other than a letter, typically a semicolon
- The following line invokes the class constructor, discussed above:
- addMe = WordPhoneme(aLine)
Great news! After executing this code, we now have a list of WordPhoneme pairs. Next, we define a binary search method.
Binary Search
Binary search is an extremely efficient way to search a list. That is important when searching a big list. Since I discussed this code before (NPR Puzzle February 5, 2022), I will only list the code and not discuss the algorithm.

def binary_search(lst, aWord):
low = 0
high = len(lst) - 1
mid = 0
while low <= high:
# Compute index 'mid' for our next guess, the middle of high and low
mid = (high + low) >> 1
# Check if aWord is present at mid
if lst[mid].Word < aWord:
low = mid + 1
# If aWord is greater, so search to the right of mid
elif lst[mid].Word > aWord:
high = mid - 1
# aWord is smaller, so search to the left of mid
else:
return mid
# element not found, return -1
return -1
Now that we have a method to perform a binary search, we will use it to search our list of WordPhoneme pairs. We need to search because we are creating strings that might or might not be legitimate words; if the search comes up dry, then we know the string is not a word.
Code to Solve!
So far, we have built a list of WordPhonemes and defined a Binary Search method. Now we use them to solve.
# Now that we have built the word-phoneme list, loop through it for wp in phonemeList: # Check if the word is 5 letters long and the L is pronounced if len(wp.Word) == 5 and 'L' in wp.Phonemes: # In ASCII, 'A' is represented by 65 and 'Z' is represented by 90 for i in range(65, 90): ltr = chr(i) # Build a potential new word by adding the letters # A-Z to the word in question. Each loop pass adds a successive letter maybeWord = ltr + wp.Word # Check if we created a bona fide word: ndx = binary_search(phonemeList, maybeWord) # If we found its index, it is in the list and indeed a word. # Proceed if so and also the L is pronounced, i.e. in the phoneme list if ndx >= 0 and not 'L' in phonemeList[ndx].Phonemes: # Loop through the alphabet again for i2 in range(65, 90): ltr = chr(i2) # Construct a potential word by taking the first 4 letters # plus the letter and the remainder of the word candidate = maybeWord[0:4] + ltr + maybeWord[4:] # Check if candidate is a word: ndx = binary_search(phonemeList, candidate) if ndx >= 0 and 'L' in phonemeList[ndx].Phonemes: # Print our result print(wp.Word, maybeWord, candidate)
Analysis
Below I list some interesting lines of code from above and discuss what they do.
if len(wp.Word) == 5 and 'L' in wp.Phonemes:- The puzzle says we start with a 5-letter word, so first we check the length of the
Wordproperty of theWordPhoneme - If the letter ‘L’ is present in the phoneme list for the
WordPhoneme, that means the L is not silent
- The puzzle says we start with a 5-letter word, so first we check the length of the
for i in range(65, 90):- This code says start a loop where variable i holds values starting at 65 and goes up to 90
- This is because the ASCII code represents letters as numbers ‘behind the scenes’, so we can easily convert the number to a character. Here’s some examples of the ASCII representation of letters:
- ‘A’ = 65
- ‘B’ = 66
- ‘C’ = 67
- …
- ‘Z’ = 90
ltr = chr(i)- This line of code makes a character from a number. For example, it converts 65 to ‘A’.
maybeWord = ltr + wp.Word- Here I construct a string by prepending a letter to the
Wordin theWordPhoneme, for example:- ‘A’ + ‘OLDER’ = ‘AOLDER’
- ‘B’ + ‘OLDER’ = ‘BOLDER’
- …
- ‘S’ + ‘OLDER’ = ‘SOLDER’
- Here I construct a string by prepending a letter to the
ndx = binary_search(phonemeList, maybeWord)- Search the list for
maybeWord
- Search the list for
if ndx >= 0 and not 'L' in phonemeList[ndx].Phonemes:ndxis the index, in our list, where we found the word we searched for- If the word is not in our list, ndx has value -1
- For example, ‘OLDER’ is located at index 85,826, because there are 85,825 entries before it
- Note the 2nd part if the if statement:
and not 'L' in phonemeList[ndx].Phonemes:
- In other words, the ‘L’ is silent, because it is not present in the phoneme list
candidate = maybeWord[0:4] + ltr + maybeWord[4:]- Just to review, at this point in code, we have started with a 5-letter word with a pronounced ‘L’, added a letter to the start of the word, tested the result to see if it is a word and also a word with a silent ‘L’. Now we construct a 3rd string
- My 3rd string (
candidate) takes the first 4 letters ofmaybeWord, adds the loop variable ltr, then finally adds the remainder ofmaybeWord
ndx = binary_search(phonemeList, candidate)- Check if
candidateis a bona fide word by searching our list
- Check if
if ndx >= 0 and 'L' in phonemeList[ndx].Phonemes:- This code checks that the
candidateis present in the list and has a pronounced ‘L’. Ifcandidatepasses that test, we have a winner! Ding! Ding! Ding!
- This code checks that the
Code Summary
My program is 42 lines of code and 42 lines of comments or blank lines. That’s pretty short! Of course, you need a special file of phonemes to solve it, so thank you to the folks at Carnegie Mellon University who created and released this file.
The code works because we can create strings that might be words and search our list to see if they are found in that list, and also because we can determine if the ‘L’ is silent by whether an ‘L’ is present in the phoneme list for the word we are working with.
Get the Code
You can download the code here, from my Dropbox account. Note that you will need to create a free account to do so.
Sunday Puzzle March 6, 2022
Find a Word That Ought to Start with a ‘Q’
This week’s challenge comes from listener Ward Hartenstein, of Rochester, N.Y. Words starting with a “kw-” sound usually start with the letters QU-, as in question, or “KW-,” as in Kwanzaa. What common, uncapitalized English word starting with a “kw-” sound contains none of the letters Q, U, K, or W?
Link to the challenge

Discussion
This is a simple puzzle if you have a list of words and their associated phonemes! You can download one here, though I have to admit I downloaded mine a very long time ago. Phonemes are a “unit of sound”, i.e. a standardized way of representing the sounds that make up a word.
The entries in the word/phoneme list look like these three samples:
- KWANZA K W AA1 N Z AH0
- QUICK K W IH1 K
- CHOIR K W AY1 ER0
Note that each word is followed by two spaces and then the phonemes that represent how that word is pronounced in North America. The main thing we care about is whether the word is followed by a K, and a W.
Skills and Techniques to Solve
Again, I elected to solve with Python, and the specific programming skills include:
- String processing
- File handling
The program is extremely short.
Here’s the Code
Since the program is so short, I’ll paste the whole 18 lines here:
def HasNoBadLetters(word):
result = True
badLetters = ['Q', 'U', 'K', 'W', '(']
for l in word:
if l in badLetters:
result = False
break
return result
fHandle = open('C:\\Users\\Randy\\Documents\\Puzzles\\Data\\cmudict.0.7a', 'rt')
for aLine in fHandle:
if (aLine.startswith('Q') or aLine.startswith('KW')):
continue
elif aLine[0:1].isalpha():
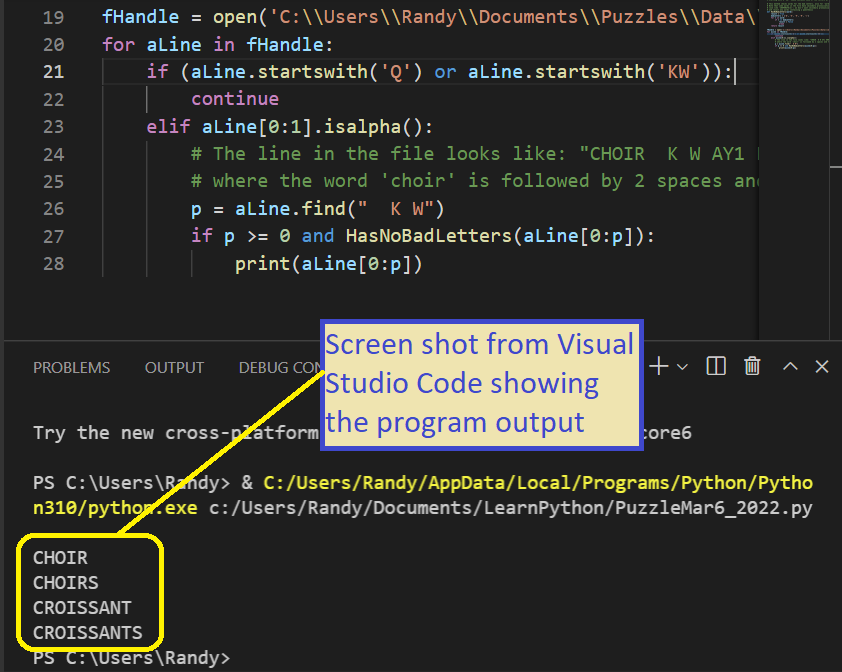
# The line in the file looks like: "CHOIR K W AY1 ER0"
# where the word 'choir' is followed by 2 spaces and then the phoneme list
p = aLine.find(" K W")
if p >= 0 and HasNoBadLetters(aLine[0:p]):
print(aLine[0:p])Code Discussion
My code listing starts by defining a short method called ‘HasNoBadLetters‘. As per the instructions, I use this method to exclude any word that has bad letters in it, namely, ‘Q’, ‘U‘, ‘K‘, ‘W’ and ‘(‘. If the input parameter, named ‘word‘, has none of these letters, we return True for our result. Otherwise, we return False. Note that I invoke this method in the second-to-last line above.
Note: Puzzle Master Will said to exclude 4 specific letters, but I exclude one more: the parenthesis. The reason for this is that some words in the file have secondary pronunciations, like the following:
- COOPERATE(2) K W AA1 P ER0 EY2 T
Apparently some weirdos pronounce it like ‘quooperate’!
Next, we open the file for reading as text (passing parameter ‘rt‘ to the open method). We loop through the lines in the file, reading each line into variable ‘aLine‘.
Next, we skip any words that start with Q or K, and also require that the first letter be alphabetic.
if (aLine.startswith('Q') or aLine.startswith('KW')):
continueThe ‘continue‘ keyword effectively means “go to the next line in our loop”.
The following line of code makes sure the first letter is not punctuation, numeric, spaces, or anything else:
elif aLine[0:1].isalpha():
Why check this? The reason for this is that the top of the phoneme file has a bunch of notes and explanation, while the remainder of the file is the word listing. All the notes/explanation lines start with a semicolon, parenthesis, or other punctuation.

Finally, having determined that the line we read from the file is a word followed by its phonemes, we test to see if it is pronounced like a word starting with “QU”, which means we look for 2 spaces followed by K W. The following three lines of code does that:
p = aLine.find(" K W")
if p >= 0 and HasNoBadLetters(aLine[0:p]):
print(aLine[0:p])The ‘find‘ method searches for a sub-string inside another string and returns the position where it was found; if not found, it returns -1.
Since the the word itself ends where “ K W” begins, we can extract it by using the notation aLine[0:p]; in other words, grab the text starting at position 0 and ending before position p.
As a side note, I didn’t realize “croissant” was pronounced with a KW sound, maybe I’m just a philistine?
No Download this Time – Too Short
If you want my code, just cut-and-paste it from the 18-line listing above. And run it yourself with the phoneme file which you can download from my link above.
Puzzle Solved! Politician Name Swap
The Challenge
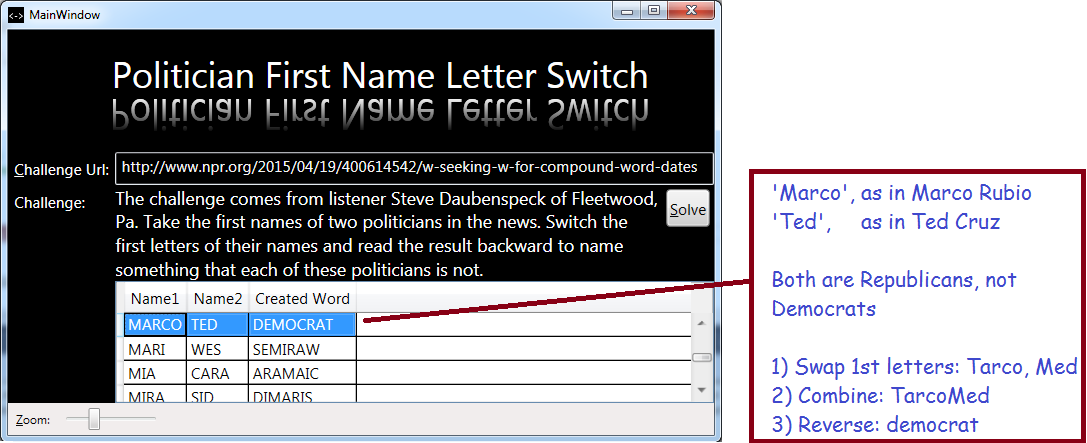
The challenge comes from listener Steve Daubenspeck of Fleetwood, Pa. Take the first names of two politicians in the news. Switch the first letters of their names and read the result backward to name something that each of these politicians is not.
Link: http://www.npr.org/2015/04/19/400614542/w-seeking-w-for-compound-word-dates
Techniques to Solve
My algorithm uses the following techniques:
- Background Workers
- Linq, Lambda Expressions and String Manipulation
- Binary Search
- File IO
Algorithm Overview
I don’t know of any list containing ‘politicians in the news’. I looked around on the web, and the closest thing I could find was a Wikipedia list of lists. It generally takes a quite while to chase down all those sub-lists, but I already had couple of nice lists of common first names (boy names and girl names). I elected to try checking all first names that might match the solution and then see how many names applied to politicians I recognized. Since only a small number (51) names could be manipulated to form an English word, it was relatively easy to look through those 51 and manually check if any matched-up with prominent politicians.
BackgroundWorker – Rationale
I used a BackgroundWorker because I wanted the grid to display work-in progress while it worked, instead of waiting until the end to see the all results. Since it takes over 2 minutes to solve, it’s a nice way to tell the users progress is being made. Important: in order to make this work, your grid should be bound to an ObservableCollection so that your grid will be aware of your updates.
When you use a BackgroundWorker, you hook-it-up to several methods which it will run at the appropriate time, including:
- DoWork – your method where you do the work!
- ProgressChanged – an event that is raised, where your other method can update the UI
- RunWorkerCompleted – fired when the DoWork method completes
The point is that we will update the UI in our ProgressChanged method, which will be on a different thread than the DoWork method. This allows the UI to update almost immediately, instead of waiting for the main thread to finish. Here’s how I set-up my worker:
//Declare the background worker at the class-level
private BackgroundWorker _Worker;
//... Use it inside my button-click event:
_Worker = new BackgroundWorker();
_Worker.WorkerReportsProgress = true;
//Tell it the name of my method, 'Worker_DoWork'
_Worker.DoWork += Worker_DoWork;
//Tell the worker the method to run when it needs to report progress:
_Worker.ProgressChanged += Worker_ProgressChanged;
//Likewise, tell it the name of the method to run when complete:
_Worker.RunWorkerCompleted += Worker_RunWorkerCompleted;
_Worker.RunWorkerAsync();
Hopefully this is pretty clear, my methods are nothing special. If you’re confused, I invite you to download my code (link at the bottom of this post) and take a look, Now let’s talk about the Linq and Lambda expressions I used inside my method ‘Worker_DoWork’.
Linq and Lambda Expressions
I didn’t use Linq/Lambda a lot, but I did use them to work with my list of names, specifically
- to perform a ‘self-join’ on my list of names
- to reverse my string (which gives me a list of char)
- and the ‘Aggregate’ method to convert my list of char back to a string
Here’s what I’m talking about:
var candidates = from n1 in allNames
from n2 in allNames
where n1 != n2
select new SolutionCandidate {
Combined = (n2[0] + n1.Substring(1) + n1[0] + n2.Substring(1))
.Reverse()
.Aggregate("", (p, c) => p + c),
Name1 = n1,
Name2 = n2
};
What is this code doing? It takes every entry in allNames, in combination with a corresponding entry in another instance of allNames (in case you’re wondering, ‘allNames’ is just a list of first names). The names in the first instance are referred to using the variable name ‘n1’, and the names in the second instance are referred to using name ‘n2’. In other words, create every possible 2-name combination. This is the equivalent of a Cartesian Product, which you should normally avoid due to huge results sets. But in this case, we actually want a Cartesian Product. If you’re thinking algorithm analysis, this code runs in O(n2) time. (Link explains my notation: http://en.wikipedia.org/wiki/Big_O_notation)
For every name pair (and there are quite a few!), the code above creates a SolutionCandidate, which is a little class with three properties, namely, ‘Combined‘, ‘Name1‘ and ‘Name2‘.
Take a look at how I create the ‘Combined’ property:
- n2[0] – this means: take the 0th char from n2 (i.e., the name from the 2nd instance of allNames)
- + n1.Substring(1) this means take a substrig of n1, starting at index 1, up to the end. In other words, all of it except the first letter (at index 0), and concatenate it the previous term (the plus sign means concatenate)
- + n1[0] this means get the 0th char of the name from the 1st instance of allNames, concatenate it too
- + n2.Substring(1) this means get all of the 2nd name except the first letter, and concatenate
After I do that, I invoke the ‘Reverse’ method on the result. Reverse normally works with lists (actually, with IEnumerable objects), but a string is actually a list of letters (char) so it will revers a string too. The problem is that the result is a list of char.
Finally, I convert my list of char back to a string using the ‘Aggregate‘ method. If I performed Aggregate on an list of numbers, I could use it to add each entry to create a sum, for example (I can do anything I want with each entry). But for a list of char, the equivalent to addition is concatenation.
Binary Searching
Binary search is an efficient way to check if some candidate is in your list. In our case, I want to check my list of all words to see if I created a real word by manipulating two first names. Here’s how I do that, remember that I build my list ‘candidates’ above and it contains a bunch of potential solutions:
foreach (var candidate in candidates)
if (allWords.BinarySearch(candidate.Combined) >= 0) {
//pass the candidate to a method on another thread to add to the grid;
//because it is on another theread, it loads immediately instead of when the work is done
_Worker.ReportProgress(0, candidate);
}
When I invoke ‘BinarySearch’, it returns the index of the entry in the list. But if the candidate is not found, it returns a negative number. BinarySearch runs in O(Log(n)) time, which is good enough for this app, which really only runs once. (I could squeeze out a few seconds by using a Dictionary or other hash-based data structure, but the dictionary would look a bit odd because I only need the keys, not the payload. The few seconds I save in run time is not worth the confusion of using a dictionary in a weird way.)
File IO
OK, I used some simple file IO to load my list of names, and also my list of all words. The code is pretty straightforward, so I’ll just list it here without any exegesis.
List//allNames will hold boy and girl names
//I run this code inside 'Worker_DoWork'
ReadNameFile(ref allNames, BOY_NAME_FILE, allWords);
ReadNameFile(ref allNames, GIRL_NAME_FILE, allWords);
//Here's the method that loads a file and adds the name to the list
private void ReadNameFile(ref List allNames, string fName, List allWords) {
string[] wordsArray = allWords.ToArray();
using (StreamReader sr = File.OpenText(fName)) {
while (sr.Peek() != -1) {
//The name is columns 1-16, so trim trailing blanks
string aName = sr.ReadLine().Substring(0, 15).TrimEnd();
int p = allNames.BinarySearch(aName);
if (p < 0)
//By inverting the result form BinarySearch, we get the position
//where the entry would have been. Result: we build a sorted list
allNames.Insert(~p, aName);
}
}
}
Notes on Improving the Efficiency
We pretty much need to perform a self-join on the list of names, and that is by far the slowest part of the app. It would be faster if we could reduce the size of the name list. One way to do that is to reject any names that could never form a solution. For example, ‘Hillary’ could not be part of a solution because,
- when we remove the first letter (H),
- we are left with hillar,
- which, when reversed, becomes ‘rallih’
- Since there are no English words that start with, or end with, ‘rallih’, I know that ‘Hillary’ is never part of the solution
I briefly experimented with this method; there are some issues. First, the standard implementation of BinarySearch only finds exact matches, not partial hits. Same thing for hash-based data structures, and a linear search is way too slow. You can write your own BinarySearch that will work with partial hits, but that leads us to the second issue.
The second issue is that, in order to do an efficient search for words that end with a candidate string, you need to make a separate copy of the word list, but with all the words spelled backwards, and run your custom binary search on it, again modifying the search to find partial matches.
After starting down that path, I elected to call it a wrap. My app runs in 2 minutes, which is slow but still faster than re-writing my code, perhaps to save 30 seconds of run time. To any ambitious readers, if you can improve my algorithm, please leave a comment!
Summary
I build a list of common names (with some simple file IO) and matched it against itself to form all combinations of common names (using Linq/Lambda Expressions); for each pair, I manipulated the names by swapping first letters and concatenating them. I then checked that candidate against my master list of all words, using a BinarySearch to check if the candidate exists in that list..
Download your copy of my code here
NPR Puzzle Solved!
What a blast to solve this one! Once in a while, everything works exactly right, and this was one of those fabulous times. My program ran the first time! (Which only happens a few times a year), plus I had all the right files on hand, and I didn’t need to fuss with any bad data. Bottom line: it took way longer to write this blog post than it took to solve the puzzle.
The challenge:
This week’s challenge comes from listener Smatt Read of Somerville, Mass. Actor Tom Arnold goes by two first names — Tom and Arnold, both male, of course. And actress Grace Kelly went by two first names — Grace and Kelly, both female. Name a famous living actress who goes by three first names, all of them traditionally considered male. The names are 5, 3 and 6 letters long, respectively.
The Solution

Techniques You Will Learn
- Simple File IO
- String manipulation
- Binary search and generic list manipulation
The Code
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
txtSolution.Clear();
//Load the list of boy names into a sorted list
List<string> boyNames = new List<string>();
using (StreamReader sr = File.OpenText(BOY_NAME_FILE)) {
//Read every line in the file
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//The name is the first thing on the line, and it is immediately followed by a space
int p = aLine.IndexOf(' ');
//Grab the name out of the line we just read:
string aName = aLine.Substring(0, p);
p = boyNames.BinarySearch(aName);
if (p < 0) {
//Binary search returns a negative number if not found, by inverting
//the number, we get the index where the name belongs in the sort order
boyNames.Insert(~p, aName);
}
}
}
//This folder contains a number of files, for with names
//like, for example, 'British_silent_film_actresses.txt'
string[] actressFiles = Directory.GetFiles(ACTRESS_FOLDER);
foreach (string fName in actressFiles.Where(f => f.IndexOf("actress") >= 0)) {
//Open all the actress files and check each against the boy name list
using (StreamReader sr = File.OpenText(fName)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//build an array with each name filling a slot in that array
string[] tokens = aLine.ToUpper().Split(' ');
if (tokens.Length > 2) {
int matchCount = 0;
//Count how many names, for this actress, are found in the boy list:
foreach (string aName in tokens) {
int p = boyNames.BinarySearch(aName);
//Binary search is very fast and returns a non-negative number if found
if (p >= 0)
matchCount++;
}
//If we have at least 3 matches, we found a winner!
if (matchCount > 2) {
txtSolution.Text += aLine + "\n";
}
}
}
}
}
Mouse.OverrideCursor = null;
}Data Comments
I originally got the actress files from wikipedia http://en.wikipedia.org/wiki/Lists_of_actresses to solve a different puzzle. I believe I obtained the list of boy names from the census bureau a long time ago, but I can’t find the link any more.
Sunday Puzzle Solved! Countries and Captials
That one was fun, and pretty simple too! It was fun because I got to use some set-manipulation features of Linq. And it was easy because I already had the data files to solve with. Furthermore, I found two answers, and the puzzler thinks there is only one. Yipee, I found an extra answer! The only unsatisfactory part was suppressing duplicates in my answer list; perhaps some intrepid reader can suggest a more elegant solution.
The challenge:
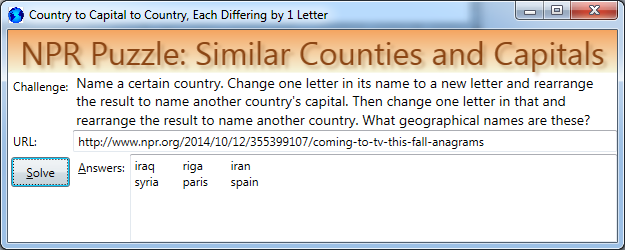
Name a certain country. Change one letter in its name to a new letter and rearrange the result to name another country’s capital. Then change one letter in that and rearrange the result to name another country. What geographical names are these?
Challenge URL: http://www.npr.org/2014/10/12/355399107/coming-to-tv-this-fall-anagrams
What You Could Learn Here
- How to use Linq to compare lists in a fairly novel manner.
- How to use the Intersect method to tell if two words differ by just one letter. Hurray, set theory!
- How to sort strings using the Aggregate method
Algorithm
- Build a list of countries, all in lower case
- Build a list of capitals, also in lower case
- Using Linq, build a list of countries matching capitals…
- According to the following comparison method:
- They must have the same length (i.e., country must be same length as capital)
- And, when we take the intersection of the country with the capital, the result must have length 1 less than the original length
- When this condition is met, we have satisfied Will’s requirement to “change one letter in its name and rearrange the result to match another country’s capital”
- Take the resulting list from above and use Linq to compare it against the country list, using the same criteria
- The result will be a list containing our answer!
- The only problem is that each answer is listed twice, the countries having different order
- For example, Iraq/Riga/Iran will be listed, and so will Iran/Riga/Iraq
Here’s the Code
private void btnSolve_Click(object sender, RoutedEventArgs e) {
List<string> countryList, capitalList;
LoadTextFiles(out countryList, out capitalList);
//Match countries against capitals
var step1 = from cty in countryList
from cap in capitalList
where cap.Length == cty.Length
//Key functionality: the intersect function
&& cty.Intersect(cap).Count() == cty.Length - 1
select new { Country = cty, Capital = cap};
//Now match the result from above against the country list again
var step2 = from pair1 in step1
from cty in countryList
where pair1.Capital.Length == cty.Length
&& pair1.Country != cty
&& pair1.Capital.Intersect(cty).Count() == pair1.Capital.Length - 1
select new { Country1 = pair1.Country, Capital = pair1.Capital, Country2 = cty };
//At this point, we have the answers, but they are duplicated, for example
//"Iran Riga Iraq" vs. "Iraq Riga Iran"
//Use the list below to avoid displaying dups:
List<string> distinctLetters = new List<string>();
foreach (var answer in step2) {
//Concatenate the countryies/captial, then sort;
//the sorted letters will determine duplicates
string sortedLetters = (answer.Country1 + answer.Capital + answer.Country2)
.OrderBy(c => c)
//'Aggregate' transforms the list back into a string:
.Aggregate("", (p, c) => p + c);
//If we have not yet displayed this answer, do so now and
//record that fact in distinctLetters
if (!distinctLetters.Contains(sortedLetters)) {
distinctLetters.Add(sortedLetters);
string displayMe = string.Format("{0}\t{1}\t{2}\n",
answer.Country1, answer.Capital, answer.Country2);
txtAnswer.Text += displayMe;
}
}
}
/// <summary>
/// Load the Capital/Country file into two lists
/// </summary>
/// <param name="countryList">The list of countries</param>
/// <param name="captialList">The list of capitals</param>
private void LoadTextFiles(out List<string> countryList,
out List<string> captialList) {
countryList = new List<string>();
captialList = new List<string>();
using (StreamReader sr = File.OpenText(CAPITAL_FILE)) {
while (sr.Peek() != -1) {
//Sample line looks like this: Athens~Greece
string aLine = sr.ReadLine().ToLower();
//find the tilde so we can separate the capital from the country
int p = aLine.IndexOf("~");
captialList.Add(aLine.Substring(0, p));
countryList.Add(aLine.Substring(p + 1));
}
}
}
Download my code here: https://www.dropbox.com/s/wix8r5jb1pipjha/12Oct2014.zip?dl=0
Calculator Letters Puzzle – Solved!
Or, Fun with Lambdas and Set Functions!
The challenge:
This three-part challenge comes from listener Lou Gottlieb.
If you punch 0-1-4-0 into a calculator, and turn it upside-down, you get the state OHIO.
What numbers can you punch in a calculator, and turn upside-down, to get a state capital,
a country and a country’s capital?

Puzzle Location:
http://www.npr.org/2014/09/14/348220755/the-puzzle-and-the-pea
The Solution Revealed!

- State Capitals
- World Capitals
- Countries
I’ve included those data files in my code download; if you run my code, note that their path will be different on your PC than mine.
Next, we’ll make a list of the available letters, which I have listed in the image below:

Once we have the data, it is basically a matter of determining whether one string set is entirely included within another string set. In other words, we will ask, for a number of solution candidates, whether it is a proper subset of the set of calculator letters.
To determine whether we have a subset, it is fun to use the Linq built-in set operators. In particular, we can use the method ‘Except‘. I also could have used the HashSet functionality, which actually has a method named ‘IsProperSubSet’, but HashSet is not as convenient as Linq and I just wanted to crank-out some code!
Using Linq, we can determine that one string is a proper subset of another if, when we use Except on them, the result is the empty set, i.e. a list with no members. Examples:
- “atlanta”.Except(“beignlos”) will return a list containing (‘a’, ‘t’), i.e. not a subset.
- “cheyenne”.Except(“beignlos”) will return a list containing (‘c’, ‘h’, ‘y’). Also not a subset.
- “boise”.Except(“beignlos”) returns the empty set, i.e. it is the answer!
Note: “beignlos” is a string containing all the calculator letters. The true benefit of the ‘Except’ method is apparent below:
Here’s a Super-Cool Sample of the .NET Set-Operator ‘Except’
var leftoverLetters = "boise".Except("beignlos");
if (leftoverLetters.Count() == 0)
Console.WriteLine("Ding ding ding - we have a winner!");
Conclusion: ‘boise’ is a subset of ‘beignlos’ –> you can spell ‘Boise’ using upside down calculator letters, and the Except function tells us that.
Use Set-Operators at Work, Too!
At work, I have recently used the ‘Except’ operator to find orders that were lost. Something along these lines: ‘var missing = outboundOrders.Except(inBoundOrders);‘
My guess is you can use the Except operator to identify a lot of other things!.
Using Lambdas as ‘First Class’ Objects
First, a little bit of terminiology: “First class objects” are objects that you can use like any other entity. Such uses include passing them as parameters. When you pass a Lambda expression as a parameter, you are taking advantage of the fact that Lambdas are first class objects.
Why did I tell you that? Because my code benefited from it in this fun little app. In particular, I have these needs:
- I need to perform the same work on 3 different files (state capitals, world capitals, countries)
- Each file has a different layout
- I would like to write a single method to do the same work for each file
- To do so, I could write 3 different lambdas; each knowing how to extract the candidate from a line in a file
- And then pass each lambda as an input parameter it to my method
- Benefit: I write one method, which uses a lambda to extract the candidate, instead of 3 methods, each with their own
techinque to extract the candidates
Here’s the Code
private void btnSolve_Click(object sender, RoutedEventArgs e) {
//Make a definition list of the calculator letters.
//This maps letters to the numbers they represent in a calculator.
//Each letter is in lower case to make matching easier
//Note: a 'tuple' is a type of anonymous class
List<Tuple<char, int>> calculatorLetterMap =
new List<Tuple<char, int>>() { Tuple.Create('b', 8),
Tuple.Create('e', 3),
Tuple.Create('i', 1),
Tuple.Create('g', 6),
Tuple.Create('n', 4),
Tuple.Create('l', 7),
Tuple.Create('o', 0),
Tuple.Create('s', 5)
};
//The next 3 lines process state capitals:
Func<string, string> extractStatCap = (aLine => {
//Look for hyphen, take the rest of the line, trimmed, in lowercase
return aLine.Substring(aLine.IndexOf('-') + 2)
.TrimEnd()
.ToLower();
});
List<string> stateCapHits = GetFileMatchesAgainstLetterSet(STATE_CAPITALS_FILE,
calculatorLetterMap, extractStatCap);
DisplayHits(stateCapHits, "State Capitals", calculatorLetterMap, txtResults);
//Now world capitals:
//The function is a bit more complicated because some names have spaces, such as 'Abu Dhabi'
Func<string, string> extractPlaceFunc = (aLine => {
//Look for a tilde and take everything prior to it, removeing non-letters
return aLine.Substring(0, aLine.IndexOf('~'))
.Where(c => char.IsLetter(c))
.Aggregate("", (p,c) => p + c);
});
List<string> worldCapHits = GetFileMatchesAgainstLetterSet(WORLD_CAPITALS_FILE,
calculatorLetterMap, extractPlaceFunc);
DisplayHits(worldCapHits, "World Capitals", calculatorLetterMap, txtResults);
//Finally, country names:
Func<string, string> extractCountryFunc = (aLine => aLine);
List<string> countryHits = GetFileMatchesAgainstLetterSet(COUNTRIES_FILE,
calculatorLetterMap, extractCountryFunc);
DisplayHits(countryHits, "Countries", calculatorLetterMap, txtResults);
}
/// <summary>
/// Loops through a file and returns a list of every entry which
/// can be composed solely with 'calculator letters'
/// </summary>
/// <param name="fName">The file containing things that might match</param>
/// <param name="calculatorLetterMap">List of letters derived from upside-down
/// calculator numbers</param>
/// <param name="extractPlaceFunc">Function to extract the item of interest
/// from each line in the file</param>
/// <returns></returns>
private static List<string> GetFileMatchesAgainstLetterSet(string fName,
List<Tuple<char, int>> calculatorLetterMap,
Func<string, string> extractPlaceFunc) {
List<string> result = new List<string>();
using (StreamReader sr = File.OpenText(fName)) {
while (sr.Peek() != -1) {
//Execute the Lambda provided by our caller:
string candidate = extractPlaceFunc(sr.ReadLine());
var leftOverLetters = candidate
.ToLower()
.Except(calculatorLetterMap.Select(m => m.Item1));
//If there are no leftover letters, we have a winner!
if (leftOverLetters.Count() == 0) {
string propperCase = char.ToUpper(candidate[0]) + candidate.Substring(1);
result.Add(propperCase);
}
}
}
return result;
}
/// <summary>
/// Displays every hit in the list with its equivalent in 'calculator letters'
/// </summary>
/// <param name="hitList">List if items to dispaly</param>
/// <param name="caption">Caption, such as 'State Capitals'</param>
/// <param name="calculatorLetterMap">List of letter/number pairs for translating</param>
/// <param name="txtResult">Textbox to hold the result</param>
private static void DisplayHits(List<string> hitList, string caption,
List<Tuple<char, int>> calculatorLetterMap, TextBox txtResult) {
txtResult.Text += caption + "\n";
foreach (string aHit in hitList) {
string number = MapLettersToCalculatorNumbers(aHit, calculatorLetterMap);
txtResult.Text += string.Format("\t{0} = {1}\n", number, aHit);
}
}
/// <summary>
/// Translates the puzzle answer ('candidate') back into 'Calculator letters'
/// </summary>
/// <param name="candidate">Such as 'boise' or 'benin' or 'lisbon'</param>
/// <param name="calculatorLetterMap">List of letter/number pairs</param>
/// <returns>A string composed of numerals</returns>
private static string MapLettersToCalculatorNumbers(string candidate,
List<Tuple<char, int>> calculatorLetterMap) {
string result = (from c in candidate
join m in calculatorLetterMap on c equals m.Item1
select m.Item2
).Aggregate("", (p, c) => p + c);
return result;
}
Download the code here: Puzzle Code
NPR Puzzle Solved: 3 Similar Names
That puzzle was the fastest solve ever, I had the whole thing done in less than an hour! Yee-haw! The funny thing is that, just last week, Will actually said that he designs the puzzles to be just as hard to solve manually as with code. But solving this one in code was so easy that perhaps Will didn’t understand what that means…
The Challenge
This week’s challenge comes from listener Matt Jones of Portland, Ore. There are three popular men’s names, each six letters long, that differ by only their first letters. In other words, the last five letters of the names are all the same, in the same order. Of the three different first letters, two are consonants and one is a vowel. What names are these?
Challenge URL: http://www.npr.org/2014/07/27/335590211/a-flowery-puzzle-for-budding-quizmasters

What You Will Learn from Reading!
- Improve your understanding of generic dictionaries in .NET
- Specifically, how dictionary entries can contain complex structures, such as lists
- String manipulation, specifically searching for substrings and extracting them from larger strings
- A sample use of a lambda expression, using the operator ‘Aggregate’, which I use to build a comma-delimited list from a list of string
Solving the Puzzle
I have a file of the to 1,219 most common boy’s names, and was able to use it to find the three forming the solution. Sorry, I don’t remember where I got it; I thought it was from the Census Bureau, but now I can’t find it on their site. Using that file,
- Build a dictionary to hold candidate names
- Open the file of names for reading
- Examine every name whose length is 6
- Extract the last 5 letters from each name
- Check if the dictionary already has a pre-existing entry, using the last 5 letters of each name as the key
- If so, append the current name to the dictionary entry
- Each entry in the dictionary is a list (because a dictionary can use any data type for the entries)
- But, if the dictionary lacks an entry identified by the current last 5 letters, add one now
- After loading the dictionary,
- Traverse all its entries
- If any entry has exactly 5 names in its list, we have a candidate!
- Check the vowel/consonant counts, if there are 2 consonants, we’ve got a winner
Here’s the heart of the code:
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Dictionary<string, List<string<< nameDic = new Dictionary<string, List<string<<();
//Open the file and read every line
using (StreamReader sr = File.OpenText(NAME_FILE)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//Sample lines looks like this:"DUSTIN 0.103 70.278 176"
// "JUSTIN 0.311 49.040 56"
// "AUSTIN 0.044 78.786 301"
//The name is position 1-15, the other columns are frequency counts and rank
//Locate the end of the name
int p = aLine.IndexOf(' ');
if (p == NAME_LEN) {
//grab the first 6 characters:
string aName = aLine.Substring(0, NAME_LEN);
//Now grab the last 5 letters of the name:
string last5 = aName.Substring(1);
//If we already have an entry (grouping) for the last 5 letters, add to the name list:
if (nameDic.ContainsKey(last5)) {
nameDic[last5].Add(aName);
} else {
//Start a new grouping using the last 5 letters as the key and the full name as the first strin entry
List<string< nameList = new List<string< { aName };
nameDic.Add(last5, nameList);
}
}
}
}
//Now find groups of names having length 3, such as 'Justin', 'Dustin', 'Austin'
foreach (KeyValuePair<string, List<string<< kvp in nameDic) {
if (kvp.Value.Count == 3) {
int vowelCount = 0;
int consonantCount = 0;
//Get the vowel/consonant counts of the first letters:
foreach (string aName in kvp.Value) {
//Binary search returns a non-negative value if it finds a match:
//In retrospect, a binary search is not appropriate for an array of size 5, but it doesn't hurt
if (Array.BinarySearch(vowels, aName[0]) <= 0)
vowelCount++;
else
consonantCount++;
}
//according to the rules, there should be 1 name starting with a vowel and 2 with consonants:
if (consonantCount == 2) {
//We can use a lambda expression to concatenate the list entries with commas
string combined = kvp.Value.Aggregate("", (p,c) =< p + ", " + c);
txtAnswer.Text += combined.Substring(2) + "\n";
}
}
}
}
I’ve posted the complete project here if you would like to download it. The code should run in Visual Studio 2010 or higher; you can use the free version of Visual Studio (“Express”) if you like. The data file is included in the zip folder; you can find it in the bin folder.
