
Latest Event Updates
Sunday Puzzle for April 10, 2022
Add Letters to a Word Twice to Get New Words with/without Silent ‘L’
This week’s challenge comes from listener Ari Ofsevit, of Boston. Think of a 5-letter word with an “L” that is pronounced. Add a letter at the start to get a 6-letter word in which the “L” is silent. Then add a new letter in the fifth position to get a 7-letter word in which the “L” is pronounced again. What words are these?
Link to the challenge on the NPR website

Discussion
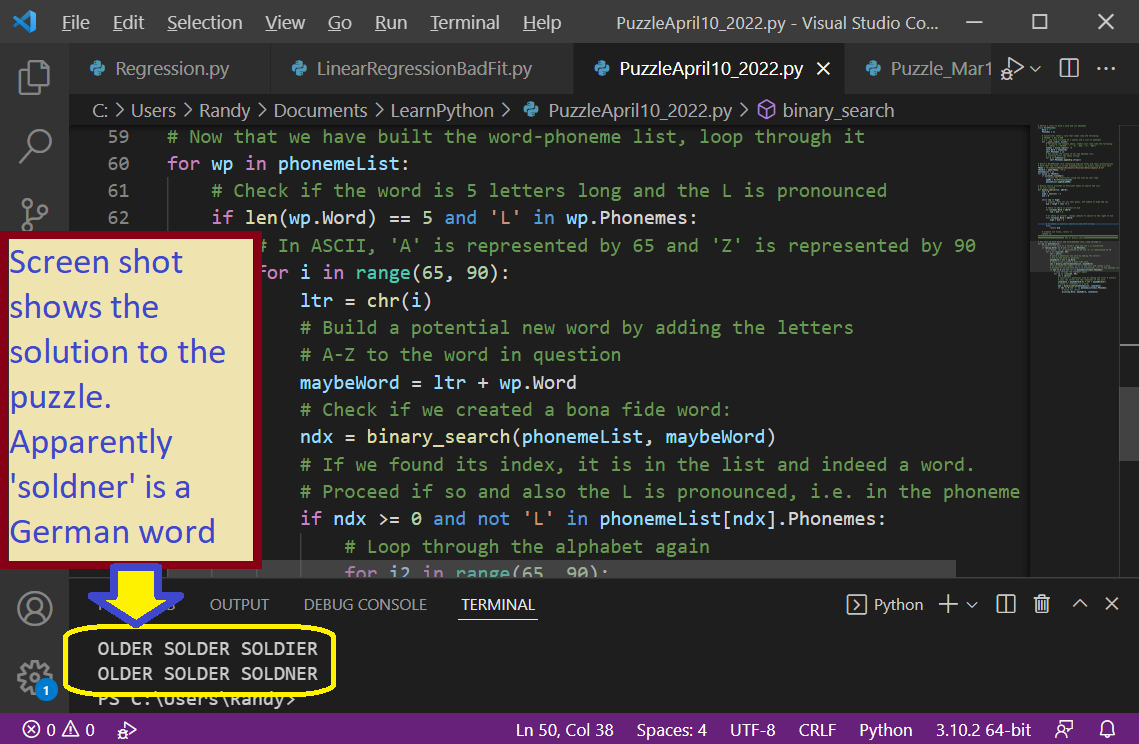
That’s a fun little puzzle, and one I suspect is a lot easier if you can write code. I love saying “Older Solder Soldier“! The puzzle can be solved if you have a list of English words and their phonemes. A phoneme is the smallest phonetic unit in a language that is capable of conveying a distinction in meaning, as the m of mat and the b of bat in English.
I use the phoneme list to determine if the ‘L’ is silent. For example, consider the following 3 words and their phonemes:
- OLDER OW1 L D ER0
- SOLDER S AA1 D ER0
- SOLDIER S OW1 L JH ER0
Note that the phoneme list for ‘older‘ contains an ‘L’, so it is pronounced. But the phoneme list for ‘solder‘ does not contain an ‘L’, so it is silent. Again, ‘soldier‘ contains an ‘L’, so it is pronounced.
Programming Techniques to Solve
- File handling
- String manipulation
- Binary search
- Classes
- Simple ranges
- General logic and looping
Code Synopsis
- Build a list of words and their associated phonemes
- Iterate the list, seeking 5-letter words containing an L
- For each such list entry, add a letter at the beginning of the word, for example:
- ‘s’ + older → solder
- If the result is a bona fide word with a silent ‘L’,
- Then add another letter at position 5, for example:
- ‘sold’ + i + ‘er’ → soldier
- If the result is a bona fide word word a pronounced ‘L’, print the result
- Then add another letter at position 5, for example:
- For each such list entry, add a letter at the beginning of the word, for example:

You can download a list of phonemes from Github
Code: A Class to Hold a Word/Phoneme Pair
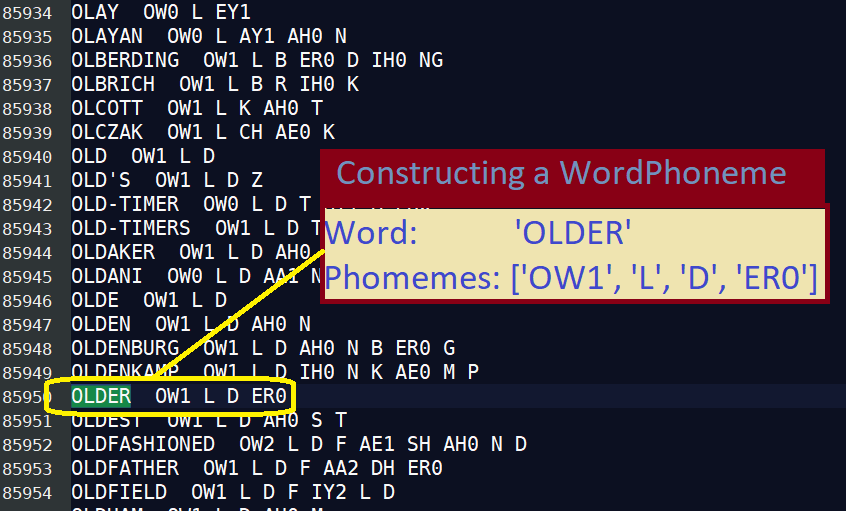
I want a list of words and their associated phonemes. My list will hold members of a class I call ‘WordPhoneme‘, defined below:
class WordPhoneme:
Word = ""
Phonemes = []
# Constructor takes a line that looks like the following:
# SOLDER S AA1 D ER0
# I.e. the word followed by 2 spaces, then a list of phonemes
def __init__(self, aLine):
# Following the example above, tokens will look like the following:
# tokens = ['SOLDER', '', 'S', 'AA1', 'D', 'ER0']
tokens = aLine.rsplit(" ")
self.Word = tokens[0]
self.Phonemes = []
# Now assign the values to our new phoneme list,
# starting after the empty string:
for p in tokens[2:]:
self.Phonemes.append(p.strip())
The class above has two properties: Word and Phonemes, i.e. a string and a list. The first two lines above define those two properties. The next lines define the constructor, which is responsible for initializing the class.
The constructor takes a parameter ‘aLine‘ which represents a line of code from the file. All we have to do is split that line using a built-in function called ‘rsplit‘ that gives us a list with one entry for each distinct string of characters in the line.
rsplitneeds a delimiter, such as a space, comma, slash, etc. I specify a space because that is what separates the tokens in the file- The result is a list, as noted in my code comment above
- We grab the first entry (
tokens[0]) and shove it into ourWordproperty - And then grab the remainder of the tokens for our
Phonemeslist- Examine the following line of code:
for p in tokens[2:]:
- Remember that the first entry in token list has index 0, so we can reference it with
tokens[0] - But we already grabbed the first token (the word), and the next token is a space, so we want to skip it too
- That tells us we need to we start at index 2 and take the remainder of the tokens. Using range indexing, we could have (for example) specified [2:3] to get the tokens at index 2 and 3, but my code doesn’t specify the end index, we instead get the remainder of the line using “
[2:]” for the index. - Refer to this article explaining range indexing in python
- Examine the following line of code:

Now, let’s open the file of phonemes and make a list of WordPhoneme pairs.
Code: Build the List of WordPhoneme Pairs by Reading the File
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\cmudict.0.7a"
fHandle = open(fName, 'rt')
phonemeList = []
for aLine in fHandle:
if aLine[0].isalpha():
# Invoke the constructor using the line we just read
addMe = WordPhoneme(aLine)
phonemeList.append(addMe)
Observe the file name in variable ‘fName‘; I use double slashes ‘\\’ instead of slashes. This is necessary because a single slash is a special character that normally modifies the following character, but a double slash is interpreted as just a slash. A single slash starts an escape character sequence. Note that my file is text, but for some reason doesn’t have a file extension “.txt”.
- The
openstatement takes a string parameter ‘rt’, meaning open it for Read, Text. - The following line checks if the line we read starts with a letter:
if aLine[0].isalpha():
- I need to do this because the top of the file contains documentation and those lines start with something other than a letter, typically a semicolon
- The following line invokes the class constructor, discussed above:
- addMe = WordPhoneme(aLine)
Great news! After executing this code, we now have a list of WordPhoneme pairs. Next, we define a binary search method.
Binary Search
Binary search is an extremely efficient way to search a list. That is important when searching a big list. Since I discussed this code before (NPR Puzzle February 5, 2022), I will only list the code and not discuss the algorithm.

def binary_search(lst, aWord):
low = 0
high = len(lst) - 1
mid = 0
while low <= high:
# Compute index 'mid' for our next guess, the middle of high and low
mid = (high + low) >> 1
# Check if aWord is present at mid
if lst[mid].Word < aWord:
low = mid + 1
# If aWord is greater, so search to the right of mid
elif lst[mid].Word > aWord:
high = mid - 1
# aWord is smaller, so search to the left of mid
else:
return mid
# element not found, return -1
return -1
Now that we have a method to perform a binary search, we will use it to search our list of WordPhoneme pairs. We need to search because we are creating strings that might or might not be legitimate words; if the search comes up dry, then we know the string is not a word.
Code to Solve!
So far, we have built a list of WordPhonemes and defined a Binary Search method. Now we use them to solve.
# Now that we have built the word-phoneme list, loop through it for wp in phonemeList: # Check if the word is 5 letters long and the L is pronounced if len(wp.Word) == 5 and 'L' in wp.Phonemes: # In ASCII, 'A' is represented by 65 and 'Z' is represented by 90 for i in range(65, 90): ltr = chr(i) # Build a potential new word by adding the letters # A-Z to the word in question. Each loop pass adds a successive letter maybeWord = ltr + wp.Word # Check if we created a bona fide word: ndx = binary_search(phonemeList, maybeWord) # If we found its index, it is in the list and indeed a word. # Proceed if so and also the L is pronounced, i.e. in the phoneme list if ndx >= 0 and not 'L' in phonemeList[ndx].Phonemes: # Loop through the alphabet again for i2 in range(65, 90): ltr = chr(i2) # Construct a potential word by taking the first 4 letters # plus the letter and the remainder of the word candidate = maybeWord[0:4] + ltr + maybeWord[4:] # Check if candidate is a word: ndx = binary_search(phonemeList, candidate) if ndx >= 0 and 'L' in phonemeList[ndx].Phonemes: # Print our result print(wp.Word, maybeWord, candidate)
Analysis
Below I list some interesting lines of code from above and discuss what they do.
if len(wp.Word) == 5 and 'L' in wp.Phonemes:- The puzzle says we start with a 5-letter word, so first we check the length of the
Wordproperty of theWordPhoneme - If the letter ‘L’ is present in the phoneme list for the
WordPhoneme, that means the L is not silent
- The puzzle says we start with a 5-letter word, so first we check the length of the
for i in range(65, 90):- This code says start a loop where variable i holds values starting at 65 and goes up to 90
- This is because the ASCII code represents letters as numbers ‘behind the scenes’, so we can easily convert the number to a character. Here’s some examples of the ASCII representation of letters:
- ‘A’ = 65
- ‘B’ = 66
- ‘C’ = 67
- …
- ‘Z’ = 90
ltr = chr(i)- This line of code makes a character from a number. For example, it converts 65 to ‘A’.
maybeWord = ltr + wp.Word- Here I construct a string by prepending a letter to the
Wordin theWordPhoneme, for example:- ‘A’ + ‘OLDER’ = ‘AOLDER’
- ‘B’ + ‘OLDER’ = ‘BOLDER’
- …
- ‘S’ + ‘OLDER’ = ‘SOLDER’
- Here I construct a string by prepending a letter to the
ndx = binary_search(phonemeList, maybeWord)- Search the list for
maybeWord
- Search the list for
if ndx >= 0 and not 'L' in phonemeList[ndx].Phonemes:ndxis the index, in our list, where we found the word we searched for- If the word is not in our list, ndx has value -1
- For example, ‘OLDER’ is located at index 85,826, because there are 85,825 entries before it
- Note the 2nd part if the if statement:
and not 'L' in phonemeList[ndx].Phonemes:
- In other words, the ‘L’ is silent, because it is not present in the phoneme list
candidate = maybeWord[0:4] + ltr + maybeWord[4:]- Just to review, at this point in code, we have started with a 5-letter word with a pronounced ‘L’, added a letter to the start of the word, tested the result to see if it is a word and also a word with a silent ‘L’. Now we construct a 3rd string
- My 3rd string (
candidate) takes the first 4 letters ofmaybeWord, adds the loop variable ltr, then finally adds the remainder ofmaybeWord
ndx = binary_search(phonemeList, candidate)- Check if
candidateis a bona fide word by searching our list
- Check if
if ndx >= 0 and 'L' in phonemeList[ndx].Phonemes:- This code checks that the
candidateis present in the list and has a pronounced ‘L’. Ifcandidatepasses that test, we have a winner! Ding! Ding! Ding!
- This code checks that the
Code Summary
My program is 42 lines of code and 42 lines of comments or blank lines. That’s pretty short! Of course, you need a special file of phonemes to solve it, so thank you to the folks at Carnegie Mellon University who created and released this file.
The code works because we can create strings that might be words and search our list to see if they are found in that list, and also because we can determine if the ‘L’ is silent by whether an ‘L’ is present in the phoneme list for the word we are working with.
Get the Code
You can download the code here, from my Dropbox account. Note that you will need to create a free account to do so.
Sunday Puzzle for March 13, 2022
Manipulate Words from a Common Phrase Containing ‘in the’
This week’s challenge comes from Tyler Hinman, of San Francisco. He’s the reigning champion of the American Crossword Puzzle Tournament, which is coming up again on April 1-3. Think of two four-letter words that complete the phrase “_ in the _.” Move the first letter of the second word to the start of the first word. You’ll get two synonyms. What are they?
Link to the challenge

Discussion
The code to solve the puzzle was easy. Getting the list of phrases was tough! Eventually, I built up a list of over 10,000 common phrases and used it to solve the puzzle. Once again, I elected to use python.
Skills and Techniques to Solve
- File handling
- String manipulation
Again, the code is quite short, just 57 lines, including 16 comment lines

Code Discussion
For simplicity, I will show the key code, saving 3 things for later:
- Building a list of English words called ‘wordLst’
- Defining a method ‘GetPriorWord’
- Defining another method ‘GetNextWord’
Here is the important, key word, skipping the three items above:
fName = 'C:\\Users\\Randy\\Documents\\Puzzles\\Data\\CommonPhrases.txt'
fHandle = open(fName, 'rt', encoding="utf8")
# Read each line in the file (about 10,000) and process lines containing ' in the '
for aLine in fHandle:
p = aLine.find(' in the ')
if p > 0:
#Remove trailing linefeed
fixed = aLine.strip()
previous = GetPriorWord(fixed, p)
if len(previous) == 4:
next = GetNextWord(fixed, p)
if len(next) == 4:
#At this point, we know both words have length 4,
#now manipulate them according to the instructions:
candidate1 = next[0] + previous
candidate2 = next[1:]
#if both candidates are valid words, print the result:
if candidate1 in wordLst and candidate2 in wordLst:
print(fixed, ' → ', candidate1, candidate2)First, we open the file with this code:
fHandle = open(fName, 'rt', encoding="utf8").
- ‘rt’ means ‘read’ ‘text’
- encoding=”utf8″ means expect and handle non-standard letters, like à la carte
Next, we loop through the lines in the file, we look for a line containing ‘in the’
p = aLine.find(' in the ')variable ‘p’ is the position where we find that substring; if not found, p will be -1. Only about 20 phrases qualify. Next, we get the words immediately before and immediately after the position where we found ‘in the’:
previous = GetPriorWord(fixed, p)
if len(previous) == 4:
next = GetNextWord(fixed, p)
if len(next) == 4:As discussed above, I will explain ‘GetPriorWord’ and ‘GetNextWord’ below. For now, the code above creates two variables holding the words we want, named ‘previous’ and ‘next’. If both have length 4, we proceed:
#At this point, we know both words have length 4,
#now manipulate them according to the instructions:
candidate1 = next[0] + previous
candidate2 = next[1:]
#if both candidates are valid words, print the result:
if candidate1 in wordLst and candidate2 in wordLst:
print(fixed, ' → ', candidate1, candidate2)‘candidate1’ is built by concatenating the first letter of next with previous. ‘candidate2’ is every letter following the first. If both are in my list of words ‘wordLst’, then we have a solution. Note that only one phrase matches this, so I didn’t write code to determine whether they are synonyms.
The Three Parts I Skipped Over
Here’s how I built wordLst:
# First load a list of English words
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\2of12inf.txt"
fHandle = open(fName, 'rt')
wordLst = []
for aWord in fHandle:
wordLst.append(aWord.strip())Here are the definitions of my two methods ‘GetPriorWord’ and ‘GetNextWord’:
#When given a position p in a string 'aLine', finds the word preceeding it
def GetPriorWord(aLine, p):
i = p - 1
while i >= 0 and aLine[i] != ' ':
i -= 1
result = ''
if i < p:
result = aLine[i + 1:p - i - 1]
return result
#When given a position p in string 'aLine, finds the word succeeding it
def GetNextWord(aLine, p):
i = p + 8
while i < len(aLine) and aLine[i].isalpha():
i += 1
result = ''
if i > p + 8:
result = aLine[p + 8:i]
return resultDownload My Code
You can download my solution, plus the phrase file, from my Dropbox account. You will need to create a free account with Dropbox to do so.
Sunday Puzzle March 6, 2022
Find a Word That Ought to Start with a ‘Q’
This week’s challenge comes from listener Ward Hartenstein, of Rochester, N.Y. Words starting with a “kw-” sound usually start with the letters QU-, as in question, or “KW-,” as in Kwanzaa. What common, uncapitalized English word starting with a “kw-” sound contains none of the letters Q, U, K, or W?
Link to the challenge

Discussion
This is a simple puzzle if you have a list of words and their associated phonemes! You can download one here, though I have to admit I downloaded mine a very long time ago. Phonemes are a “unit of sound”, i.e. a standardized way of representing the sounds that make up a word.
The entries in the word/phoneme list look like these three samples:
- KWANZA K W AA1 N Z AH0
- QUICK K W IH1 K
- CHOIR K W AY1 ER0
Note that each word is followed by two spaces and then the phonemes that represent how that word is pronounced in North America. The main thing we care about is whether the word is followed by a K, and a W.
Skills and Techniques to Solve
Again, I elected to solve with Python, and the specific programming skills include:
- String processing
- File handling
The program is extremely short.
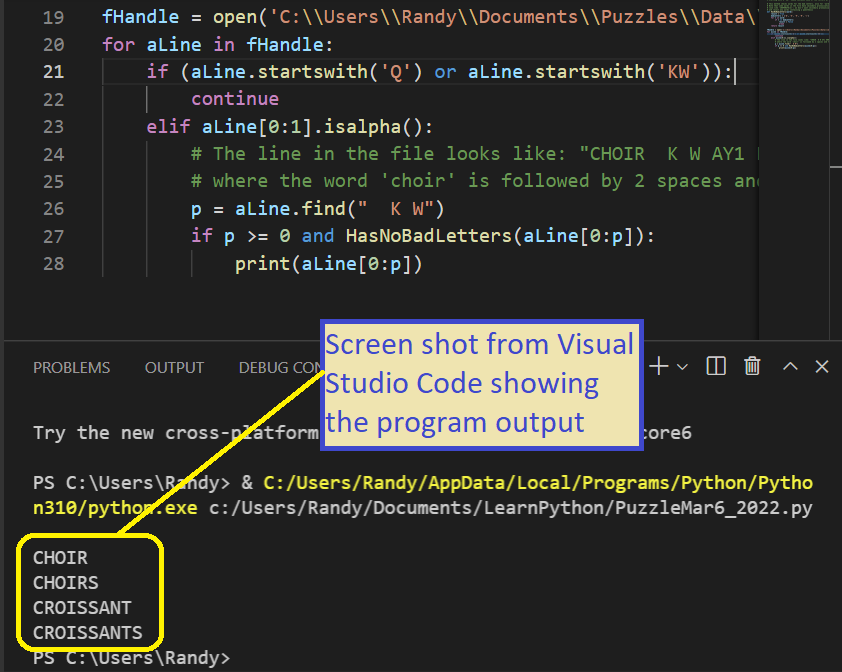
Here’s the Code
Since the program is so short, I’ll paste the whole 18 lines here:
def HasNoBadLetters(word):
result = True
badLetters = ['Q', 'U', 'K', 'W', '(']
for l in word:
if l in badLetters:
result = False
break
return result
fHandle = open('C:\\Users\\Randy\\Documents\\Puzzles\\Data\\cmudict.0.7a', 'rt')
for aLine in fHandle:
if (aLine.startswith('Q') or aLine.startswith('KW')):
continue
elif aLine[0:1].isalpha():
# The line in the file looks like: "CHOIR K W AY1 ER0"
# where the word 'choir' is followed by 2 spaces and then the phoneme list
p = aLine.find(" K W")
if p >= 0 and HasNoBadLetters(aLine[0:p]):
print(aLine[0:p])Code Discussion
My code listing starts by defining a short method called ‘HasNoBadLetters‘. As per the instructions, I use this method to exclude any word that has bad letters in it, namely, ‘Q’, ‘U‘, ‘K‘, ‘W’ and ‘(‘. If the input parameter, named ‘word‘, has none of these letters, we return True for our result. Otherwise, we return False. Note that I invoke this method in the second-to-last line above.
Note: Puzzle Master Will said to exclude 4 specific letters, but I exclude one more: the parenthesis. The reason for this is that some words in the file have secondary pronunciations, like the following:
- COOPERATE(2) K W AA1 P ER0 EY2 T
Apparently some weirdos pronounce it like ‘quooperate’!
Next, we open the file for reading as text (passing parameter ‘rt‘ to the open method). We loop through the lines in the file, reading each line into variable ‘aLine‘.
Next, we skip any words that start with Q or K, and also require that the first letter be alphabetic.
if (aLine.startswith('Q') or aLine.startswith('KW')):
continueThe ‘continue‘ keyword effectively means “go to the next line in our loop”.
The following line of code makes sure the first letter is not punctuation, numeric, spaces, or anything else:
elif aLine[0:1].isalpha():
Why check this? The reason for this is that the top of the phoneme file has a bunch of notes and explanation, while the remainder of the file is the word listing. All the notes/explanation lines start with a semicolon, parenthesis, or other punctuation.

Finally, having determined that the line we read from the file is a word followed by its phonemes, we test to see if it is pronounced like a word starting with “QU”, which means we look for 2 spaces followed by K W. The following three lines of code does that:
p = aLine.find(" K W")
if p >= 0 and HasNoBadLetters(aLine[0:p]):
print(aLine[0:p])The ‘find‘ method searches for a sub-string inside another string and returns the position where it was found; if not found, it returns -1.
Since the the word itself ends where “ K W” begins, we can extract it by using the notation aLine[0:p]; in other words, grab the text starting at position 0 and ending before position p.
As a side note, I didn’t realize “croissant” was pronounced with a KW sound, maybe I’m just a philistine?
No Download this Time – Too Short
If you want my code, just cut-and-paste it from the 18-line listing above. And run it yourself with the phoneme file which you can download from my link above.
NR Puzzle Feb 25, 2022
This week’s challenge comes from listener Alan Hochbaum, of Duluth, Ga. Name a famous actor — first and last names. Remove the last letter of each name. You’ll be left with an animal and an adjective that describes that animal, respectively. Who is the actor?
Link to Puzzle at NPR

Another easy puzzle, and again I elected to solve it using Python. Skills and techniques include:
- File processing
- String manipulation
- Simple Regular Expressions
- Binary search
- Loops and basic logic

Comments
I’m pretty confident in my code, and I have a lists of 16,000 actors, 5,000 adjectives, and 2,000 animals. But, I don’t have all the actors, animals and adjectives! So there could be other solutions that I missed, even though my code works satisfactorily. “Redd Foxx” is not a well known actor these days. Sorry if either is your favorite actor, but I’ve never heard of my other two actors, Cody Longo and Sean Whalen. So, come Sunday, I would not be surprised if Will says some other actor is the solution. But, as you can see, given my data, these three are legitimate solutions.

Strategy
- Load the animal file into a list. Note my file is alphabetically sorted
- Load the adjective file into another list
- Open the actor file and process each entry
- Split the name into separate words
- Using a regular expression expressing to control the separator character
- Split the name into separate words
- Take the first word – call it the first name,
- Take the last word – call it the actor’s last name
- Avoid any suffix, such as ‘Jr.’, ‘Sr.’, etc.
- Use a binary search to quickly search the animal and adjective lists
- If we get a hit for first and last names, print a candidate solution
- Take the last word – call it the actor’s last name
Here’s The Code
Step 1: Load the two Files
import re
# Open and load the animals file; note it is presorted
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\CommonAnimals.txt"
animals = []
# Note: file is already sorted
fHandle = open(fName, 'rt')
for aLine in fHandle:
animals.append(aLine.strip())
# Open and load the adjectives file, also presorted
adjectives = []
# This file is sorted too
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\Adjectives.txt"
fHandle = open(fName, 'rt')
for aLine in fHandle:
adjectives.append(aLine.strip())A couple notes:
- I use a double backslash \\ in the file path because a single backslash is used to designate special characters
- I invoke the ‘strip’ method primarily to remove the linefeed
Step 2: Define the Binary Search Method
def binary_search(list1, n):
low = 0
high = len(list1) - 1
mid = 0
while low <= high:
# Compute index for our next guess, the middle of high and low
mid = (high + low) >> 1
# Check if n is present at mid
if list1[mid] < n:
low = mid + 1
# If n is greater, compare to the right of mid
elif list1[mid] > n:
high = mid - 1
# If n is smaller, compared to the left of mid
else:
return mid
# element not found, return -1
return -1Notes
- Binary search is extremely fast (it runs in
O (log(n))time). Meaning that the search time is proportionate to the log of the list size. For example, if the list has a million entries, binary search would find an entry in an average 6 operations (because Log(1000000) = 6). Note that it works if the list is sorted. low, mid and highare indexes to the list. ‘mid‘ is the middle of the current search subsection.- We examine the element at position
mid- If it matches our target ‘n’, we found it
- But if it is smaller, recompute high (which then causes mid to be recomputed)
- Alternatively, if it is higher, recompute low (which also causes mid to be recomputed next guess)
- Bit-shift for even more speed: the following is the faster version of division by 2:
mid = (high + low) >> 1
- It does this by shifting the bits to the right one position. I do this for a minor increase in speed; note that division is by far the slowest arithmetic operator
Step 3: Process the Actor File
# Use this list to make sure we get the correct surname
suffixes = ['Jr', 'Sr', 'II', 'III']
fName = "C:\\Users\\Randy\\Documents\\Puzzles\\Data\\Actors\\Actors.txt"
# The file has some non-standard letters, so open with utf-8
fHandle = open(fName, 'rt', encoding="utf8")
for aLine in fHandle:
# By splitting the name, we can get each name part as
# a separate entry in the list 'tokens':
tokens = re.split(r'[ ,.]', aLine.strip())
first = tokens[0][:-1]
last = ''
lastIndex = len(tokens) - 1
if tokens[lastIndex] in suffixes and lastIndex >= 2:
last = tokens[lastIndex -1][:-1]
elif lastIndex >= 1:
last = tokens[lastIndex][:-1]
# At this point, the first and last names have been stripped of
# their last characters. Some names might not work
# because they have length 1,
# such as the actor 'X Brands' or 'A.J. Trauth',
# so skip over empty first/last names
if last != '' and first != '':
# see if first name starts corresponds to an animal
aniIndex = binary_search(animals, first)
# -1 means no match; so now let's see
# if first name works with adjectives:
if aniIndex == -1:
adjIndex = binary_search(adjectives, first.lower())
if adjIndex != -1:
aniIndex = binary_search(animals, last)
if aniIndex != -1:
print(aLine.strip(), '-->', adjectives[adjIndex], animals[aniIndex].lower())
else:
# First name is an animal; try last name for adjectives
adjIndex = binary_search(adjectives, last.lower())
if adjIndex >= 0:
print(aLine.strip(), '-->', adjectives[adjIndex], animals[aniIndex].lower())
Comments
- I use a regular expression to split the actor name into a list of separate strings
tokens = re.split(r'[ ,.]', aLine.strip())
- For example, “William Collier, Jr.”
- Becomes [“William”, “Collier”, “Jr”], i.e. a list of 3 strings
- The separator characters (delimiters) are space, comma and period, specified here:
r'[ ,.]'
- The first name is at position 0 of the list, the first element
- The following line of code creates a variable ‘first’ by removing the last character from the first element:
first = tokens[0][:-1]- Using string slicing
- Usually, the last string in my list is the actor’s surname, but sometimes they have a suffix like “Sr.”
- The following code tests if the last string is such a suffix:
if tokens[lastIndex] in suffixes and lastIndex >= 2:
- After assigning the first and last name, we use those variables to perform a binary search
- If
firstis an adjective and last is ananimal, print a solution - Or, if
lastis an adjective andfirstis an animal, print
Download the Code
You can download my code and data files here. Note that you will be required to create a free DropBox account to do so.
NPR Sunday Puzzle – Language on 3 Adjacent Phone Keys – Solved in Python
Link to the NPR puzzle.
This week’s challenge: What language in seven letters can be spelled using the letters on three consecutive keys on a telephone? It’s a language you would probably recognize, but not one that many people can speak.

This is an easy and fun puzzle that only requires basic tools to solve. I elected to solve the puzzle using Python. Some of the language features used include:
- String handling
- String length
- strip method
- casefold method
- Dictionaries
- Looping
- Basic logic and arithmetic operations
- File reading
Basic Approach
- Build a
dictionarylinking alphabetic letters to keyboard numbers - Open the file containing language names
- Loop through each line in the file
- Use the
stripmethod to make sure the language name has no trailing blanks or newlines - If the language name has length other than 7, go to the next line
- Create two integer variables to reflect the highest and lowest key used by the language, ‘
minKey‘ and ‘maxKey‘- Consider how to type the language ‘Klingon’ on your keypad:
- The highest key is 6, the lowest key is 4. Because K and I are on key 4, while O and N are on key 6
- We know that Klingon is a valid solution because it uses keys 4, 5, 6, which form a set of 3 adjacent keys, as required by the puzzle
- Now, loop through each letter in the language name
- Use our dictionary to look up the key for each letter
- If the current key is lower than the lowest so far, update
minKey - Likewise, update
maxKeyif the current key is higher than the previous max - If the difference between
minKeyandmaxKeyis greater than 2, move to the next line - Finally, after processing every letter in the language, if we haven’t disqualified it, print the language name to the console

Now, let’s look at each of those steps along with the code to implement it. We’ll start with building the dictionary.
Code to Build the Dictionary
import string
# Build a dictionary whose key is the letter and whose value is the keypad key
# For example, keyDic['a'] = 2 because letter 'a' is on key 2
# Another example, keyDic['s'] = 7 because letter 'S' is on key 7
keyDic = {}
key = 0
for lc in string.ascii_lowercase:
# insert an entry into the dictionary, note that // performs integer division
keyDic[lc] = 2 + (key // 3)
# There are letters (PQRS) on key 7 and also 4 on key 9 (WXYZ)
if lc != 'r' and lc != 'y':
key += 1
Interpretation: Build an empty dictionary with this line: “keyDic = {}”. The loop iterates the range consisting of the lower case ascii letters, ‘a’ through ‘z’. We are able to do this by importing string (note the first line of code). Note that integer division ignores fractional values, so 3.333 becomes 3.
We add new entries to the dictionary with this statement: “keyDic[lc] = 2 + (key // 3)”
The dictionary looks like this, note the 4 entries sharing value 4 (PQRS) and the 4 entries sharing value 9 (WXYZ):
{'a': 2,
'b': 2,
'c': 2,
'd': 3,
'e': 3,
'f': 3,
'g': 4,
'h': 4,
'i': 4,
'j': 5,
'k': 5,
'l': 5,
'm': 6,
'n': 6,
'o': 6,
'p': 7,
'q': 7,
'r': 7,
's': 7,
't': 8 ,
'u': 8,
'v': 8,
'w': 9,
'x': 9,
'y': 9,
'z': 9 }
Interpretation: look at the first line. The key is ‘a’, its associated value is 2, because a is on the keboard pad for 2.
Code to Open the Language File and Loop Through Each Line
# This file contains 472 languages from Wikipedia, including constructed languages:
fPath = "C:\\Users\\Randy\\Documents\\LearnPython\\LanguagList.txt"
fHandle = open(fPath, "r", encoding='utf-8')
# Loop handles one language each pass
for aLine in fHandle:
Interpretation: the file name is in a variable ‘fPath’. We need double slashes (i.e. ‘\\’) to separate the path because, normally, \ is uses as a prefix for characters that interfere with the quotation marks. Note that I have to specify the file encoding, i.e. utf-8, because some language names have special characters, such as the languages ‘Brežice’ or ‘Kēlen’.
Code to Clean the Line of code
# Loop handles one language each pass
for aLine in fHandle:
# Need to remove the newline character
cleanLine = aLine.strip()
Check the length of the language
# Puzzle requirements specifies the language has length seven:
if len(cleanLine) == 7:
Interpretation: we’re in a loop, we execute the following lines only if the length is seven
Declare and Initialize Variables minKey and maxKey
#To initialize the minKey/maxKey variables, we use the 1st character
ltr1 = cleanLine[0].casefold()
if ltr1 in keyDic:
# these two variables reflect the highest and lowest keys on the keypad
# as used by the language name
minKey = keyDic[ltr1]
maxKey = keyDic[ltr1]
Interpretation: get the first letter in the language, i.e. ‘cleanLine[0]’. Like every other letter in the language name, we check if it exists in the dictionary before accessing the dictionary value. The ‘casefold’ method converts it to lower case. minKey and maxKey share the same value at first; that will change shortly.
Loop Through the Letters in the Language
# loop through the letters in the language, after converting to
# lower case, and skipping the first character, which we already looked at
for c in cleanLine.casefold()[1:]:
if c in keyDic:
# look up the key for the language letter:
key = keyDic[c]
if key < minKey:
minKey = key
if key > maxKey:
maxKey = key
Interpretation: we already looked at the first letter and we won’t reprocess it. So we slice the word using indexing, i.e. [1:]. (Look at the end of the first line of code in the sample above). This indexing means ‘give me the slice starting at position 1, through the end of the word’. We check if the letter is in the dictionary and update minKey or maxKey as necessary.
If the difference between minKey and maxKey is greater than 2, move to the next line
# The puzzle says the language can be spelled by 3 consecutive keys
if maxKey - minKey > 2:
# Since the diffenece is more than 2, it doesn't qualify
# for example, if maxKey = 4 and minKey = 2, then it qualifies
# but when maxKey = 5 and minKey = 2, it does not
qualifies = False
break
else:
# the letter is not on the keypad, probably it is
# a non-standard letter like â, å, -, etc
qualifies = False
break
Print the Language Name if it Hasn’t Been Disqualified
if qualifies:
print(cleanLine)
That’s it! The code loops around after this last statement and processes the next language name. It runs in a couple milliseconds and we get the output shown below:

Get the Code
I uploaded my code (just 67 short lines) to my DropBox account, along with my language file (472 language names from Wikipedia). You can download the code here: get the code here. Note: you will need your own DropBox account (free).
Serializing a List Containing Disjoint Class Instances
Serializing a list, all of the same class, is easy. Serializing a list of different class instances is not. (All class instances implement the same interface.) Since I couldn’t readily find how to do this anywhere else, I decided to write-up my results and share. Maybe I’ll need it again some day.
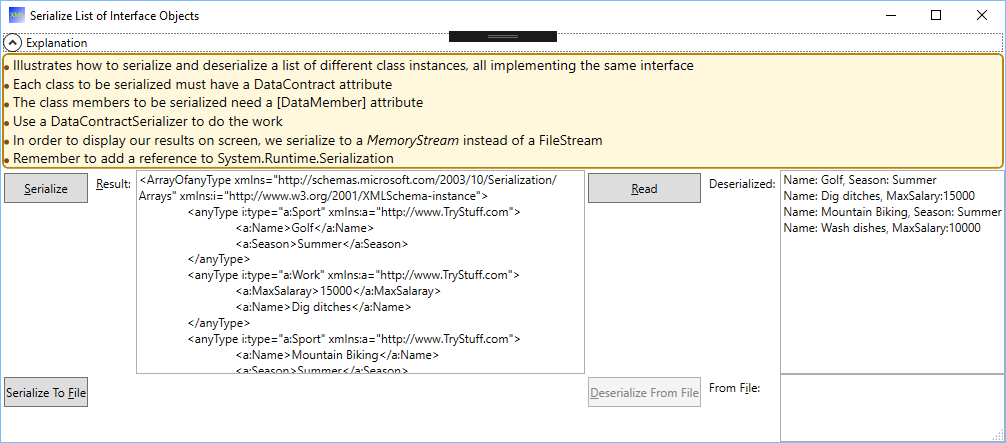
Just to make it perfectly clear, I want to serialize a list like the following
var serializeThis = new List<IActivity> {
new Sport { Name = "Golf", Season = "Summer" },
new Work { Name = "Dig ditches", MaxSalaray = 15000 },
new Sport { Name = "Mountain Biking", Season = "Summer" },
new Work { Name = "Wash dishes", MaxSalaray = 10000 }
};
Key Points
- Use DataContractSerializer to do the work
- When you initialize your serializer, provide a list of Types representing the class types in your list
- Mark your classes with a [DataContract] attribute
- Mark the class members to serialize with [DataMember] attribute
- Remember to add a reference to System.Runtime.Serialization
Note that the list contains Sport objects and Work objects; both implement IActivity. “Normal” serialization techniques won’t work here.
The Code
using System;
using System.Collections.Generic;
using System.IO;
using System.Runtime.Serialization;
using System.Text;
using System.Windows;
using System.Xml;
namespace SerializeListOfInterfaceObjects {
/// <summary>
/// Illustrates how to serialize/deserialize a list of objects of different classes,
/// all implementing the same interface
/// </summary>
/// <remarks>
/// Use DataContracts and DataContracSerializer to do the work. Also use a MemoryStream
/// to hold the result.
/// </remarks>
public partial class MainWindow : Window {
public MainWindow() {
InitializeComponent();
}
/// <summary>This is our practice data</summary>
private List<IActivity> ListToSerialize {
get {
//Note the list has two different kinds of class instances:
return new List<IActivity> {
new Sport { Name = "Golf", Season = "Summer" },
new Work { Name = "Dig ditches", MaxSalaray = 15000 },
new Sport { Name = "Mountain Biking", Season = "Summer" },
new Work { Name = "Wash dishes", MaxSalaray = 10000 }
};
}
}
/// <summary>
/// Send the list to a memory stream as xml, use a StreamReader to read from
/// that MemoryStream and display the resulting text in the textbox
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
private void BtnSerialize_Click(object sender, RoutedEventArgs e) {
List<IActivity> serializeThis = ListToSerialize;
//Note the list of class types; this tells the
//DataContractSerializer what to expect:
var mySerializer = new DataContractSerializer(serializeThis.GetType(),
new Type[] { typeof(Sport), typeof(Work) });
using (var memStr = new MemoryStream()) {
mySerializer.WriteObject(memStr, serializeThis);
memStr.Seek(0, SeekOrigin.Begin);
using (var sw = new StreamReader(memStr)) {
var theText = sw.ReadToEnd();
txtSerialized.Text = theText;
}
}
btnDeSerialize.IsEnabled = true;
}
/// <summary>
/// Read the text in the textbox and deserialize it
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
private void BtnDeserialize_Click(object sender, RoutedEventArgs e) {
List<IActivity> activityList = null;
//We will use a UTF8Encoding to write to this memory stream,
//the DataContractSerializer will read from it
using (var memStr = new MemoryStream()) {
UTF8Encoding utf8Enc = new UTF8Encoding();
byte[] byteThis = utf8Enc.GetBytes(txtSerialized.Text);
memStr.Write(byteThis, 0, byteThis.Length);
memStr.Seek(0, SeekOrigin.Begin);
//The MemoryStream has the data, the DataContractReader will now read from it:
XmlDictionaryReader reader = XmlDictionaryReader.CreateTextReader(memStr,
new XmlDictionaryReaderQuotas());
var ser = new DataContractSerializer(typeof(List<IActivity>),
new Type[] { typeof(Sport), typeof(Work) });
activityList = (List<IActivity>)ser.ReadObject(reader, true);
reader.Close();
}
//activityList is now magically populated with a list of
//IActivity objects; display on screen:
txtSerializedResult.Clear();
foreach (IActivity act in activityList) {
txtSerializedResult.Text += act.ToString() + "\n";
}
}
/// <summary>
/// Send the same list to a file
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
private void BtnSerializeToFile_Click(object sender, RoutedEventArgs e) {
var serializeThis = ListToSerialize;
using (FileStream fs = new FileStream("ActivityList.xml", FileMode.Create)) {
var mySerializer = new DataContractSerializer(serializeThis.GetType(),
new Type[] { typeof(Sport), typeof(Work) });
mySerializer.WriteObject(fs, serializeThis);
}
btnDeserializeFromFile.IsEnabled = true;
txtMessage.Text = "Serialized to file 'ActivityList.xml'";
}
/// <summary>
/// Read the file we just wrote and deserialize into a list again
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
private void BtnDeserializeFromFile_Click(object sender, RoutedEventArgs e) {
List<IActivity> lstOfActivities = new List<IActivity>();
using (FileStream fs = new FileStream("ActivityList.xml", FileMode.Open)) {
var mySerializer = new DataContractSerializer(lstOfActivities.GetType(),
new Type[] { typeof(Sport), typeof(Work) });
lstOfActivities = (List<IActivity>)mySerializer.ReadObject(fs);
}
//Display the deserialized result:
txtFromFile.Clear();
foreach (var activity in lstOfActivities)
txtFromFile.Text += activity.ToString() + "\n";
}
}
////////////////////////////////////////////////////////////////////////////
/// <summary>We will serialize a list of these</summary>
interface IActivity {
string Name { get; set; }
}
////////////////////////////////////////////////////////////////////////////
/// <summary>This will be one of the items in the list we serialize</summary>
/// <remarks>The following attribute enables the DataContractSerializer to work</remarks>
[DataContract(Name = "Sport", Namespace = "http://www.TryStuff.com")]
class Sport : IActivity {
/// <summary>A parameterless constructor is required</summary>
public Sport() { }
/// <summary>Members with the following attribute will be serialized:</summary>
[DataMember]
public string Name { get; set; }
[DataMember]
public string Season { get; set; }
public override string ToString() {
return $"Name: {Name}, Season: {Season}";
}
}
////////////////////////////////////////////////////////////////////////////
/// <summary>Another class implementing the same interface</summary>
[DataContract(Name = "Work", Namespace = "http://www.TryStuff.com")]
class Work : IActivity {
public Work() { }
[DataMember]
public string Name { get; set; }
[DataMember]
public int MaxSalaray { get; set; }
public override string ToString() {
return $"Name: {Name}, MaxSalary:{MaxSalaray}";
}
}
}
Highlight: The Code That Does the Work
var mySerializer = new DataContractSerializer(serializeThis.GetType(),
new Type[] { typeof(Sport), typeof(Work) });
using (var memStr = new MemoryStream()) {
mySerializer.WriteObject(memStr, serializeThis);
Note the Type array I provide to the serializer, that tells what types to expect. You will need to replace this with a list of your own types, unfortunately it can’t autodetect your class types.
The serializer needs to send your text to a stream; MemoryStream is a handy place to send it when all you want to do is display it on screen. You can then use a StreamReader to get the XML out of the MemoryStream and do whatever you want with it.
Marking-Up My Classes
I had to decorate my classes with the following attribute:
[DataContract(Name = "Sport", Namespace = "http://www.TryStuff.com")]
class Sport : IActivity { ... }
And I had to decorate the class members to serialize with a [DataMember] tag. You can use the attribute on public and private members, but only certain data types are serializable. Anything you don’t want serialized –> omit the tag.
Possible Alternate Technique
I tried implementing the IXmlSerializable interface on my classes; that interface allows you to control how your classes are serialized. It seemed like it might work, but it didn’t. The bottom line is you will get an error to the effect of “A parameterless constructor is required“.
Since you can’t specify a constructor in an interface, this prevents you from serializing a list of interface intstances via this technique. Potentially you could the technique with abstract classes instead of interfaces; I was not in a position to refactor my code to try.
Summary
The DataContractSerializer will send your list to XML in a fairly automatic way. The Microsoft example shows how to do this (to a file) out-of-the-box. However, it doesn’t discuss handling different classes all in the same list. In order to do that, you need to provide a parameter specifying a list of types to serialize.
Unlike the MS example, if you want to manipulate your serialized XML without sending it to a file, you need to use a memory stream. You can read the results using a StreamReader (which is a lot easier than the examples Microsoft has on MSDN).
Reversing the process is fairly straightforward, the tricky part was I had to use a UTFEncoding to read from the memory stream; for some reason, XML doesn’t like to deserialize from Unicode, even though going the other way Unicode works perfectly fine. I didn’t experiment using a StreamReader, instead of a UTF8Encoding, but I’ll guess it won’t work.
Download the Code
You can download my code here, note that DropBox will ask you to create a new (free) account in order to access it.
NPR Sunday Puzzle, World Capital to Farm Animal
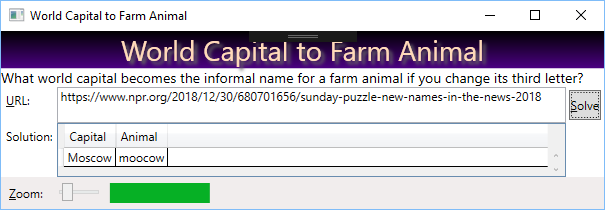
Synopsis
What makes this puzzle challenging is the lack of a good list of “informal” farm animals. There are lists of farm animal names, they don’t work. Also, the solution, “moocow”, requires a really big dictionary, though my PC has plenty of power to solve the puzzle in a few seconds. However, it is nice to have a progress bar, so my code does so.
Approach
I don’t have a list of informal farm animal names; maybe I can find an ordinary word which contains a farm animal inside it. Check every capital which can be morphed into other words, and then check to see if any of those words contain a farm animal name.
Specifics
- Build a dictionary of every word, the dictionary key will be the capital with the 3rd letter chopped out, each entry’s payload (value) will be the original word(s)
- For example, “moscow” → [“mocow”, “moscow”], i.e. the key is the chopped word and the value is the original word
- Sometimes the same dictionary key corresponds to multiple words, for example, Accra, acara and Acura all turn into ‘acra’ when you chop-out the 3rd letter
- Besides building the dictionary, build a list of every common farm animal, this will be pretty short
- Next, process the file containing capital names.
- For every capital, chop-out the 3rd letter and look-up the corresponding words in the dictionary
- At this point, we need to check every farm animal and see if any of them are a substring of any of the words the capital can morph into
- If so, display it as part of the solution
Additional Techniques
I used the IProgress construct, along with asynchronous invocation of my solving method to allow the UI to remain responsive, and update my progress bar, while the code runs.
The Code
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using System.Windows;
using System.Windows.Input;
using System.IO;
using System.Collections.ObjectModel;
namespace Dec30_2018 {
/// <summary>
/// Holds the controls and code to solve the puzzle
/// </summary>
public partial class MainWindow : Window {
/// <summary>Bound to the solution grid</summary>
private ObservableCollection<Tuple<string, string>> _SolutionList;
public MainWindow() {
InitializeComponent();
}
/// <summary>
/// Fires when user clicks the solve button
/// </summary>
/// <param name="sender">The buton</param>
/// <param name="e">Event args</param>
private async void BtnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
btnSolve.IsEnabled = false;
_SolutionList = new ObservableCollection<Tuple<string, string>>();
grdSolution.ItemsSource = _SolutionList;
//This code fires when the SolvePuzzle method reports progress:
var progress = new Progress<Tuple<int, string, string>>(args => {
prg.Value = args.Item1;
if (!string.IsNullOrWhiteSpace(args.Item2))
_SolutionList.Add(Tuple.Create(args.Item2, args.Item3));
});
//Run the solution on a different thread so the UI will be interactive
await Task.Run(() => SolvePuzzle(progress));
btnSolve.IsEnabled = true;
Mouse.OverrideCursor = null;
}
/// <summary>
/// Solves the puzzle using a big word list, a list of captials, and a list of farm animals
/// </summary>
/// <param name="rptProg">Basically a method to invoke when we want to report progress</param>
private void SolvePuzzle(IProgress<Tuple<int, string, string>> rptProg) {
string wordFile = @"C:\Users\User\Documents\Puzzles\Data\NPLCombinedWordList.txt";
//Key to the dictionary will be the word with its 3rd letter cut-out, the payload will
//be a comma-separated list of words that correspond to it.
//For example, for Moscow, the key will be 'mocow' and the value will be 'Moscow'
//For Accra, the key will be 'acra' and the value will be 'acara,accra, acura'
var wordDic = new Dictionary<string, string>();
var fSize = (new FileInfo(wordFile)).Length;
int processedBytes = 0;
int lastPct = 0;
using (StreamReader sr = File.OpenText(wordFile)) {
while (sr.Peek() != -1) {
string aWord = sr.ReadLine();
if (aWord.Length > 3) {
string key = (aWord.Substring(0, 2) + aWord.Substring(3)).ToLower();
if (wordDic.TryGetValue(key, out string fullWords))
wordDic[key] += "," + aWord;
else
wordDic.Add(key, aWord);
}
//Calculate the percentage of the file processd and report progress if it increase by 1 point
processedBytes += aWord.Length + 2;
var pct = (int)(100 * ((double)processedBytes / fSize));
if (pct != lastPct) {
rptProg.Report(Tuple.Create(pct, "", ""));
lastPct = pct;
}
}
}
//Build a list of farm animals:
var farmAnimalList = new List<string>();
string farmAnimalFile = @"C:\Users\User\Documents\Puzzles\Data\FarmAnimals.txt";
using (StreamReader sr = File.OpenText(farmAnimalFile)) {
while (sr.Peek() != -1) {
farmAnimalList.Add(sr.ReadLine());
}
}
//Process the list of capitals and, for each entry, check to see if it forms a solution
string capitalFile = @"C:\Users\User\Documents\Puzzles\Data\WorldCapitals.txt";
using (StreamReader sr = File.OpenText(capitalFile)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//A typical line looks like 'Moscow~Russia' or 'London~Great Britian'
int p = aLine.IndexOf('~');
string capital = aLine.Substring(0, p);
if (capital.Length > 3) {
//Chop-out the 3rd letter and get the words that correspond to it in the word dictionary:
string key = (capital.Substring(0, 2) + capital.Substring(3)).ToLower();
if (wordDic.TryGetValue(key, out string morphedWords)) {
//Build an array for all the words which share the same key:
var splitWords = morphedWords.Split(new[] { ',' }, StringSplitOptions.RemoveEmptyEntries);
//Perform a Cartesian product so we get every combination from the farm animal list and the words
//corresponding to the key:
var joinList = splitWords.Join(farmAnimalList,
s => "", f => "",
(s, f) => new { Word = s, Animal = f });
//Examine every combo in the cartesian product:
foreach (var candidate in joinList) {
//If the animal is a substring of the word, then we have a solution,
//such as "moocow".IndexOf("cow") = 3, because cow is a substring of moocow at position 3
if (candidate.Word.IndexOf(candidate.Animal) >= 0
&& capital.ToLower() != candidate.Word) {
//Report progress with the solution pair, which will disply it in the grid:
rptProg.Report(Tuple.Create(100, capital, candidate.Word));
}
}
}
}
}
}
}
}
}
Get the Code
Download the code here, from my dropbox account. Note: they will ask you to create a free account to perform the download.
Puzzle: Chicagoan Name to Actor Name
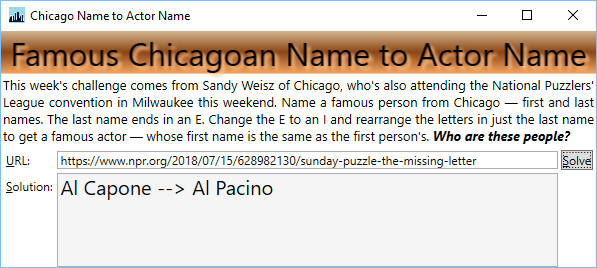
Synopsis
Another easy one! The appropriate name lists are available on Wikipedia, and the main coding issue is knowing how to check whether two names are anagrams. (Easy! Sort both candidates –> anagrams are the same after sorting . E.g. ‘caponi -> acinop, also pacino -> acinop.)
Getting the Names
I checked Wikipedia, they had a nice list of about 500 famous people from Chicago. I looked through the names and immediately suspected Al Capone, since he was the most famous of the few whose names ended with ‘e’. The hard part would be finding an actor to match.
Happily, I already had a set of files for actor’s names from a previous puzzle, also harvested from Wikipedia.
I elected to grab the name of every Chicagoan and save them in a file, who knows, I might need them again. This time, I manually cut-and pasted the data, cleaned it up, and saved to a file. I’ll include the file in the code download, listed below.

Algorithm Outline
- Read the Chicagoan name file, keep the few whose name ends in ‘e’
- Read the actor name files, store the results in a dictionary
- Use the sorted last name as the dictionary key
- Use the first/last names as the value for each entry
- For convenience, store them as a Tuple<string, string>
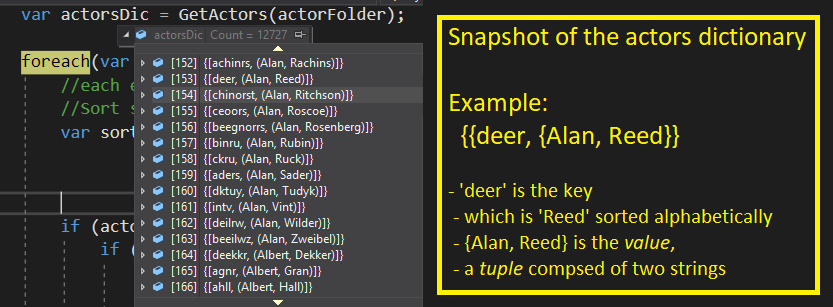
- Note that a ‘Tuple’ is simply a means of holding two (or more) things in a single object, in this case, my tuple is composed of Item1 = first name and Item2 = last name.
- For each Chicagoan, replace the last ‘e’ with an i (capone –> caponi)
- Sort the revised name (caponi -> acionp)
- Use the result to check if there is an entry in the dictionary with matching that key
- Because dictionaries use hashing, this check is super efficient.
- If the dictionary contains such a key, retrieve the value and check if the first name matches the candidate from Chicago.
- If so, we found the solution!
Techniques Used
Selected Code Highlights
Here’s the code from the button click event method:
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
string chicogoansFile = @"C:\Users\User\Documents\Puzzles\Data\Chicogoans.csv";
var chicogoans = GetChicogoansEndingWithE(chicogoansFile);
string actorFolder = @"C:\Users\User\Documents\Puzzles\Data\Actors";
var actorsDic = GetActors(actorFolder);
foreach(var chicagoPerson in chicogoans) {
//each entry is a Tuple of two strings, the last name is item2
//Sort swap the e for an i and sort
var sortedName = (chicagoPerson.Item2.Substring(0, chicagoPerson.Item2.Length - 1) + "i")
.ToLower()
.OrderBy(c => c)
.Aggregate("", (p, c) => p + c);
//Is there an actor whose name is an anagram of 'sortedName'?
if (actorsDic.ContainsKey(sortedName)) {
//OK, now check if the Actor's first name is the same:
if (actorsDic[sortedName].Item1 == chicagoPerson.Item1) {
string firstName = actorsDic[sortedName].Item1;
string lastName = actorsDic[sortedName].Item2;
//Build a string to display in the UI:
string candidate = $"{chicagoPerson.Item1} {chicagoPerson.Item2}" +
"-->" +
"{firstName} {lastName}\n";
txtSolution.Text += candidate;
}
}
}
Mouse.OverrideCursor = null;
}
Notes
- “GetChicogoansEndingWithE” is a method I wrote to build a list of people from Chicago. Download my code (below) for details
- “GetActors” is another method I wrote that builds a dictionary of actors, using their sorted last name as the key
- I sort the last name using a lambda expression
- The following fragment replaces the ‘e’ with ‘i’ in the Chicagoan’s last name:
- (chicagoPerson.Item2.Substring(0, chicagoPerson.Item2.Length – 1) + “i”)
- “.ToLower()” converts the result from above to lower case, i.e. ‘Caponi’ -> ‘caponi’
- The following fragment sorts the letters in the result from above:
- .OrderBy(c => c)
- Note that this code treats a string as a list of char elements
- In the syntax above, ‘c’ represents the thing to order by, namely, each char
- The result from above is another list of char
- The following fragment converts the list back to a string:
- .Aggregate(“”, (p, c) => p + c)
- Where “” is the seed to use for agregation
- (p,c) represents the arguments used for the aggregation function, ‘p’ is result from the previous aggregation operation, ‘c’ is the current value
- p + c is the aggregation operation, i.e. take the previous and add current to it
- The following fragment replaces the ‘e’ with ‘i’ in the Chicagoan’s last name:
Download the Code!
I uploaded my code to my DropBox site, you can download it here. Note that they will ask you to create a free account in order to download.
Sunday Puzzle: State/City Built from Abbreviations
Synopsis: Fun and Easy!
This was an very easy challenge. If you have a list of cities by state, you can check the spelling of each state/city and see if it is constructed from state abbreviations.
To make it interesting, I did some binary searching and also wrote a fun little method to test if a string has even or odd length. Binary searches are super efficient, and so is my method for testing if a string is even/odd. Since the lists are short, I don’t really need that efficiency; I did it mostly for fun.
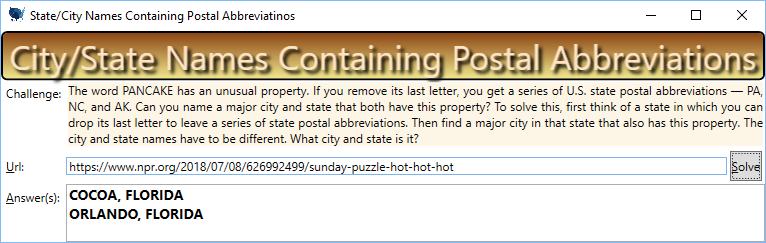
Answer Explained
Even though the city “Cocoa, Florida” technically meets the criteria, it isn’t a major city, so Will must be looking for “Orlando, Florida“:
- OR + LA + ND = Orland = Orland + o
- I.e., Or=Oregon, LA=Louisiana, ND=North Dakota
Techniques Used
- File IO
- String Manipulation
- Binary Searching
- Simple Classes
City/State List
You can get a big list of American cities by state here: https://homepage.divms.uiowa.edu/~luke/classes/STAT4580/maps.html, look for the link to the file “PEP_2017_PEPANNRES.zip“. This is the 2017 version of the file and might be formatted differently than the 2016 version I used to solve the puzzle.
Algorithm: The Big Picture
- Make a list of the state abbreviations
- Using the file discussed above, make a list of the cities for every state
- Write a function “NameContainsAbbrs” that indicates if the specified name (such as “Florida”) is built from state abbreviations
- Find the states whose names meet Will’s condition
- For the cities in that state, find the ones which meet Will’s condition
Implementation
The method below performs the steps listed above. (If you download the code below, you will notice that this code fires when you click the button on the UI.)
private void btnSolve_Click(object sender, RoutedEventArgs e) {
//Build a list of state abbreviations
List stateAbbrvs = InializeStateList();
//List contains every state; each state entry contains a list of cities
List citiesByState = ReadCityStateFile();
var validstates = citiesByState
.Where(s => NameContainsAbbrs(s.StateName, stateAbbrvs));
foreach(var vState in validstates) {
foreach(var aCity in vState.CityList) {
if(aCity != vState.StateName
&& NameContainsAbbrs(aCity, stateAbbrvs)) {
txtSolution.Text += $"{aCity}, {vState.StateName}\n";
}
}
}
}
An explanation of each step follows.
Algorithm Step 1: Read the States and Cities
Pertaining to step 2 above, “make a list of the cities for every state“, read the cities-by-state file described above. Use it to build a list of cities by state that looks like the image below:
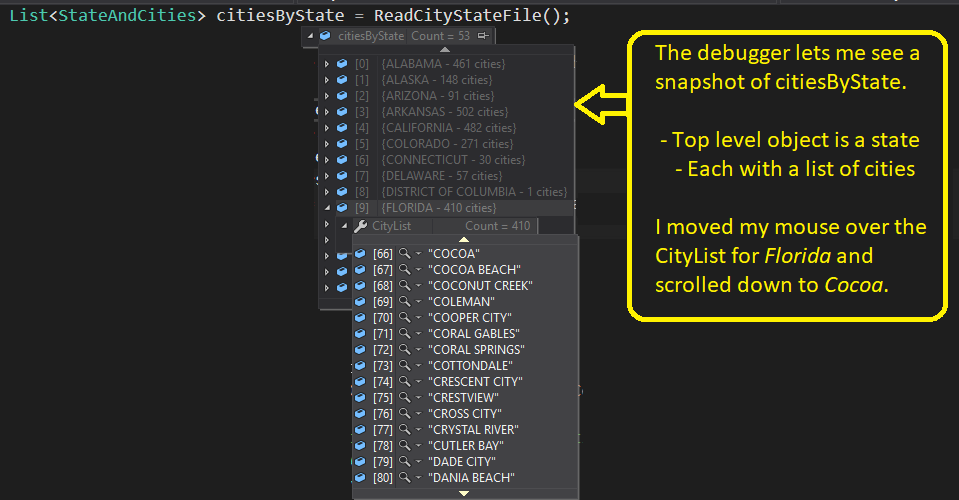
Code for Class ‘StateAndCities’
public class StateAndCities {
public StateAndCities() {
CityList = new List();
}
public string StateName { get; set; }
public List CityList { get; set; }
public override string ToString() {
return $"{StateName} - {CityList.Count} cities";
}
}
The list discussed above is a list where each entry is an instance of the class ‘StateAndCities’.
Algorithm Step 2: Write a Method ‘NameContainsAbbrs’
private bool NameContainsAbbrs(string aName, List stateAbbrvs) {
bool result = true;
string nameNoSpace = aName.Replace(" ", "");
bool lengthIsOdd = (nameNoSpace.Length & 1) == 1;
if (lengthIsOdd) {
//remove trailing letter:
string candidate = nameNoSpace.Substring(0, nameNoSpace.Length - 1);
var comp = new StateAbbrvPairComparer();
for (int i = 0; i < candidate.Length; i += 2) {
string abbrv = candidate.Substring(i, 2);
int p = stateAbbrvs.BinarySearch(new StateAbbrvPair { Abbrv = abbrv }, comp);
if (p < 0) {
result = false;
break;
}
}
} else
result = false;
return result;
}
Notes:
- The method takes a parameter ‘stateAbbrvs’ that looks like the following:
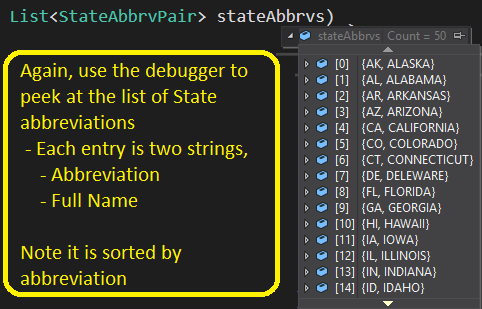
- The first thing we do is remove spaces from the name we are checking,
- For example, “NEW York” –> “NEWYORK”
- Next, we make sure the name length is odd, for example, ‘Florida” has 7 letters, so it is odd.
- We want odd-length names because we need to subtract the last letter, such as “Florida” –> “Florid”
- And the result must be capable of forming a sequence of 2-letter abbreviations, such as “FL” – “OR” – “ID”
- Here is the code to check if the length is odd:
-
bool lengthIsOdd = (nameNoSpace.Length & 1) == 1;
- This effectively checks whether the length, when represented in binary, ends with a 1
- Example: Florid has length 7
- In binary, 7 is 111. Obviously it ends with a 1
- Note that the and operator here performs binary arithmetic, i.e.
- 111 & 001 = 001
- To wit, 7 & 1 == 1
- Indicating that Florida’s length is odd.
- This effectively checks whether the length, when represented in binary, ends with a 1
- What’s the point? I could have divided by 2 and checked if there was a non-zero remainder. Normally, that is fine, but quite a bit slower than my method. Division is one of the slowest primitive operators in programming, but performing an “and” operation is lightning quick.
- As I mentioned above, speed is not critical for this puzzle – I mostly did it for fun and to illustrate a different technique
- If you needed to determine if, say, a million words were even or odd, then this technique would be way faster than performing division, not just for fun
-
Building the Cities-By-State List
In the code above, the following line of code builds the list of cities by state:
List citiesByState = ReadCityStateFile();
The method ‘ReadCityStateFile’ builds the sorted list discussed above. You may be interested in this method because it illustrates some cool features related to binary searching. Take a look at the code below:
private List ReadCityStateFile() {
string cityFile = @"C:\Users\User\Documents\Puzzles\Data\CensusCities\PEP_2016_PEPANNRES_with_ann.csv";
//Each entry will be a state name containing a list of cities:
var citiesByState = new List();
var comp = new StateAndCityComparer();
using (StreamReader sr = File.OpenText(cityFile)) {
//First two lines contains headers, so skip it
sr.ReadLine();
sr.ReadLine();
while (sr.Peek() != -1) {
//read each successive line
string aLine = sr.ReadLine();
//This simple method extracts the city and state name from the line:
ParseCityState(aLine, out string cityName, out string stateName);
var stateAndCity = new StateAndCities { StateName = stateName };
if (p < 0) {
//Binary complement the negative index returned
//by BinarySearch and insert there:
citiesByState.Insert(~p, stateAndCity);
stateAndCity.CityList.Add(cityName);
} else {
//Append to the existing entry's city list:
citiesByState[p].CityList.Add(cityName);
}
}
}
return citiesByState;
}
Notes on Binary Searching
Let’s examine this line of code from above:
int p = citiesByState.BinarySearch(stateAndCity, comp);
- The search result “p” represents the index inside the list where we find the item in question
- The parameter ‘comp‘ is a very simple class that compares two StateAndCities instances through a method named “Compare”
- It returns 0 if they have the same state name,
- It returns a negative number if the 1st instance is alphabetically prior to the 2nd instance
- And a positive number if the 1st instance is alphabetically after 2nd instance
- Implementation below
- If the state name is not found in the list, p will be a negative number
- When we take the bitwise-complement of p (i.e. ~p), we get the index of the list where we should insert the state in order to keep it sorted,
- As in this code:
- citiesByState.Insert(~p, stateAndCity);
- As in this code:
Class StateAndCityComparer
public class StateAndCityComparer : IComparer<StateAndCities> {
public int Compare(StateAndCities x, StateAndCities y) {
return string.Compare(x.StateName, y.StateName);
}
}
As discussed above, if x == y, we return 0, if x < y, we return a negative number, and if x > y, we return a positive number. “String.Compare” does this for us based on the state name; the result is that our list will be searched by state name.
Get the Code
You can download the code here, at my Dropbox account. In order to download, they will ask you to first create a free account.
Summary
- Using a list of state names with associated cities,
- We can check if each name is composed of state abbreviations
- For speed, a Binary Search is used to perform lookups
Puzzle: Singer Name to Group Type
The Challenge
The Solution
Synopsis
Fun, easy! I was fortunate to have a file lying around with singer names, and it was easy enough to go to Wikipedia to grab a list of musical group types.
Also: woo-woo! I Almost solved it without a single bug! I was able to fix my solitary bug during a debug session, so I can honestly say it ran the first time.
Techniques Used
- Linq
- File-IO
- String-manipuation
- Just for a fun, anonymous functions (delegates)
The Code
string singerFile = @"Singers.txt"; string groupTypeFile = "MusicalGroupTypeList.txt"; //Make a function to sort the letters in a string, converting //to lower case, and removing all but letters Func<string, string> sortLetters = (g) => g .Where(c => char.IsLetter(c)) .Select(c => char.ToLower(c)) .OrderBy(c => c) .Aggregate("", (p, c) => p + c); //The dictionary key is the sorted letters; the //value is the original string var groupTypeDic = new Dictionary<string, string>(); //Open the file of group types; use it to build the dictionary using (StreamReader sr = File.OpenText(groupTypeFile)) { while (sr.Peek() != -1) { string grpType = sr.ReadLine(); string key = sortLetters(grpType); if (!groupTypeDic.ContainsKey(key)) { groupTypeDic.Add(key, grpType); } } } //Now read all the singers from the file using (StreamReader sr = File.OpenText(singerFile)) { while (sr.Peek() != -1) { string singerName = sr.ReadLine(); string[] tokens = singerName.Split(' '); int lastIndex = tokens.Length - 1; if (tokens.Length > 1 && tokens[0].Length == 3 && tokens[lastIndex].Length == 5) { //Combine the first name and /1st 2 letters of last name, //plus the last 2 letters of last name string remove3rdLetterLastName = tokens[0] + tokens[lastIndex].Substring(0, 2) + tokens[lastIndex].Substring(3); string sorted = sortLetters(remove3rdLetterLastName); //Does the dictionary contain the sorted letters? if (groupTypeDic.ContainsKey(sorted)) { //Yipee! Found a solution txtSolution.Text = $"{singerName} → {groupTypeDic[sorted]}"; } } } }
Explanation
Remember, if two words are anagrams, then their sorted letters are the same.
- “Bob Dylan” → “bobdyan” →”abbdnoy”
- “Boy Band” → “boyband” → “abbdnoy”
Encapsulate that Functionality in an Anonymous Function named ‘sortLetters’
Func<string, string> sortLetters = (g) => g
.Where(c => char.IsLetter(c))
.Select(c => char.ToLower(c))
.OrderBy(c => c)
.Aggregate("", (p, c) => p + c);
Here I create a function variable named ‘sortLetters’ that has one input parameter (string) and returns another string.
Inside the function, the input parameter (‘g’) is treated like a list of char, because I invoke Linq methods on it.
- The ‘where-clause’ removes any spaces or other funky chars
- The ‘select-clause’ converts ‘BobDylan’ → ‘bobdylan’
- The ‘OrderBy’ clause converts ‘bobdylan’ to ‘abbdnoy’
- The ‘Aggregate’ clause converts the result back to a string
Read all the Group Types, Hold Each in Variable ‘grpType’
using (StreamReader sr = File.OpenText(groupTypeFile)) {
while (sr.Peek() != -1) {
string grpType = sr.ReadLine();
Store the Group Type in a Dictionary
string key = sortLetters(grpType);
if (!groupTypeDic.ContainsKey(key)) {
groupTypeDic.Add(key, grpType);
}

Read the Singers File, Store Each in Variable ‘singerName’
using (StreamReader sr = File.OpenText(singerFile)) {
while (sr.Peek() != -1) {
string singerName = sr.ReadLine();
Split the Singer Name into Parts, Proceed if Lengths are 3/5
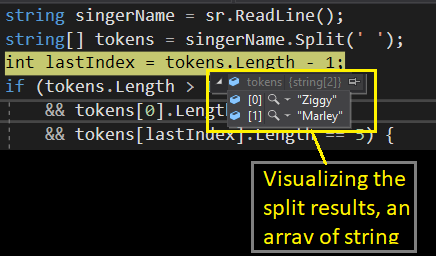
string[] tokens = singerName.Split(' ');
int lastIndex = tokens.Length - 1;
if (tokens.Length > 1
&& tokens[0].Length == 3
&& tokens[lastIndex].Length == 5) {
- The ‘split’ function returns an array of string
Remove 3rd Letter From Singer’s Name, Sort the Letters
string remove3rdLetterLastName = tokens[0]
+ tokens[lastIndex].Substring(0, 2)
+ tokens[lastIndex].Substring(3);
string sorted = sortLetters(remove3rdLetterLastName);
Here we concatenate the first name with the first 2 letters of last name and then the last 2 letters of the last name. Re-use the anonymous function to sort the letters.
If the Sorted Letters Match a Dictionary Entry, Add the Result to the TextBox
if (groupTypeDic.ContainsKey(sorted)) {
//Yipee! Found a solution
txtSolution.Text = $"{singerName} → {groupTypeDic[sorted]}";
}
Get the Code
You can download my code here. Note that you will need to create a (free) dropbox account to access the link.
- ← Previous
- 1
- 2
- 3
- …
- 9
- Next →
