
Dictionaries
NPR Puzzle for November 20, 2022
Science Branch with Two Embedded Anagrams
Last week’s challenge came from Henri Picciotto, of Berkeley, Calif. He coedits the weekly “Out of Left Field” cryptic crossword. Name a branch of scientific study. Drop the last letter. Then rearrange the remaining letters to name two subjects of that study. What branch of science is it?
Link to the challenge
General Approach
I elected to use WPF for this one, for one reason, I was in a bit of a hurry, and I’m faster in WPF. Also, WPF is well suited for file handling, unlike web-based solutions, and the code needs to load a file containing English words, as well as a file containing fields of science. Finally, the code is a bit CPU intensive; Python would run slower, and building a nice UI in Python is harder, at least for me!
Here’s how my UI looks after clicking the ‘Solve’ button:
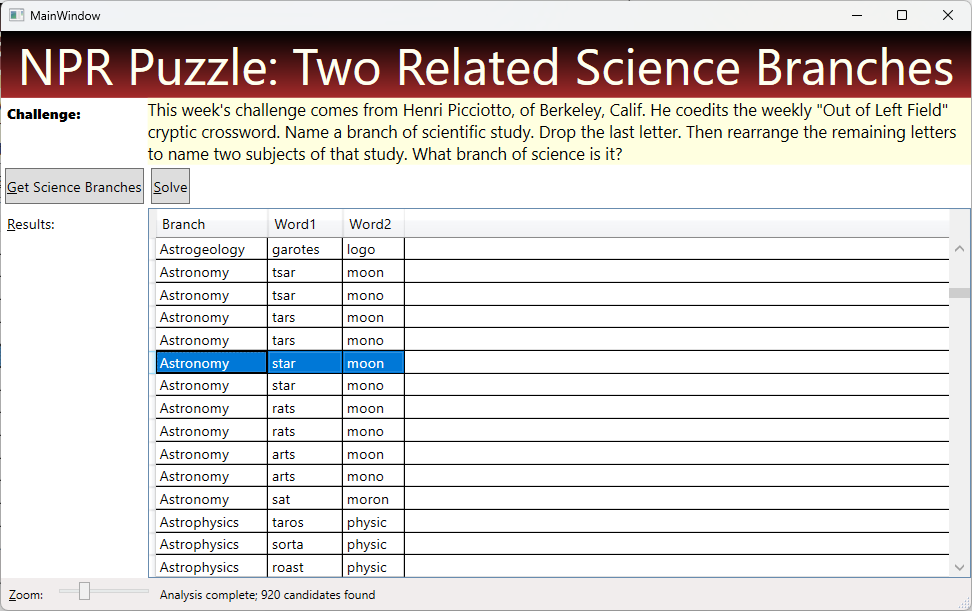
Techniques Used

Synopsis
We can get a list of 716 branches of study from Wikipedia. Using HtmlAgilityPack, we can extract the names from the raw HTML on that page. That is the list we will attempt to manipulate, so we need a list of English words, many of which are available on the web (including this one).
Using those two sources, proceed by first splitting each branch into two parts (after stripping the last letter). Note that each branch can be split at several points, so we use a loop to try every valid split point.
Having split the original, we anagram the two sub-words. To do so, we take advantage of a simple fact relating to anagrams:
Two words are anagrams if their sorted letters are the same

To capitalize on this principle, we build a dictionary, using every word in English, whose keys are the sorted letters, having an associated value composed of the list of words that share those sorted letters. That way, we can easily and efficiently find the anagrams of any word. Here’s what a sample dictionary entry looks like:
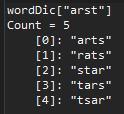
Interpretation: the image above is a screen shot from Visual Studio’s Immediate Pane. It shows the value associated with one particular dictionary key, “arst”, which is a list of 5 words, all of which are anagrams of each other. Just to make it ultra clear, here is the dictionary entry for “mnoo”:
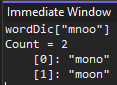
The dictionary will contain 75,818 such entries.
Using the dictionary, we can tell if a candidate has any anagrams by checking if its sorted letters exist in the key. If the key exists, we can get all the anagrams for the candidate by examining the value associated with that key. Remember, each entry in a dictionary is a key/value pair.
So, to recapitulate, we will build a dictionary from all English words, each entry has the sorted letters as the key, and the list of anagrams as the value. We loop through the science branches, splitting each into two candidates. If both candidates are in the dictionary (after sorting their letters), then we have a candidate solution.
Here’s the Code!
To save space, I will omit the part of my code which downloads the list of science branches. But have no fear, you can download all my code and examine it to satisfy your curiosity, using the link at the bottom.
Note that the code below is just an excerpt, representing the most important code. At the point where the excerpt begins, we already have the following variables:
branchList– a list of all 716 branches of science, a simple list of type stringwordDic– a dictionary constructed as described above, using sorted letters as the key to each entry
Obviously, if you want to see the code I haven’t discussed below, you can just download my entire project (link below); I believe the embedded comments in that code should satisfy your curiosity.
Note that each numbered comment in the listing below has a corresponding explanation after the code listing.
//Every candidate solution will go into this collection, which is bound to the display:
var answers = new ObservableCollection<Answer>();
grdResults.ItemsSource = answers;
//The syntax below allows the screen to remain responsive while the algorithm runs
await Task.Run(() => {
int count = 0;
foreach (var candidate in branchList) {
//1) remove the last letter
var trimmed = candidate.ToLower()[..^1];
//2) This inner loop tries splits the science branch at all possible points
//forming two parts, br1 and br2:
for (var i = 1; i < trimmed.Length - 1; i++) {
//3) Take the first part of the candidate and sort its letters
var br1 = trimmed[..i].OrderBy(c => c).Aggregate("", (p, c) => p + c);
//4) If the sorted letters are in the dictionary, work with
//the 2nd part of the branch:
if (wordDic.ContainsKey(br1)) {
//5) Grab the 2nd part of the branch and sort its letters
var br2 = trimmed[(i)..].OrderBy(c => c).Aggregate("", (p, c) => p + c);
//6) If br2 is in the dictionary, we have a potential solution:
if (wordDic.ContainsKey(br2)) {
//7) Each entry (the science branch name part) has a list associated with it
//(the entry's value); display all combinations from those 2 lists
foreach (var word1 in wordDic[br1]) {
foreach (var word2 in wordDic[br2]) {
var addmMe = new Answer { Branch = candidate, Word1 = word1, Word2 = word2 };
answers.Add(addmMe);
}
}
}
}
}
//Update the progress bar
var pct = (int)(100 * count++ / (float)branchList.Count);
Dispatcher.Invoke(() => prg.Value = pct);
}
});
Numbered Comment Explanation
var trimmed = candidate.ToLower()[..^1];- Each branch of science in the list is mixed case, so use “
ToLower” to match our dictionary - [..^1] means take a substring starting at the beginning, all the way to 1 before the end
- Each branch of science in the list is mixed case, so use “
for (var i = 1; i < trimmed.Length - 1; i++) {- The variable
icontrols the split point in the candidate; the first eligible position is 1, because we don’t want any zero-length strings. Similarly, the last split point is 1 before the end - For example, the word “astronomy” would be split as 7 different times, once for each pass through the loop, with the split points shown below, as well as the pertinent variables:
- i = 1, a – stronom, br1 = a, br2 = oomnrst
- i = 2, as – tronom, br1 = as, br2 = oomnrt
- i = 3, ast – ronom, br1 = ast, br2 = oomnr
- i = 4, astr – onom, br1 = arst, br2 = oomn
- i = 5, astro – nom, br1 = aorst, br2 = omn
- i = 6, astron – om, br1 = anorst, br2 = mo
- i = 7, astrono – m, br1 = anoorst, br2 = m
- The variable
var br1 = trimmed[..i].OrderBy(c => c).Aggregate("", (p, c) => p + c);- Take the substring ending at position i. Then sort the letters (“
OrderBy“). Note that the result isIEnumerable<char>– basically a list of characters. Now take the result of that operation andAggregateit so we get a string instead of a list of char. - Interpret the aggregation as follows:
- “” (Empty quotes) This is the seed, we start with an empty string and append everything to it
(p,c) =>this introduces the two parameters used in the operation, they represent the previous (p) value and the current valuec. Previous means the string we have built so farp + cWe simply append the current character to the previous value
- The upshot is this code converts a list of char into a string
- Take the substring ending at position i. Then sort the letters (“
if (wordDic.ContainsKey(br1)) {- Test if the sorted letters (
br1) have an anagram by asking the dictionary if it has a corresponding key. This is like asking the dictionary if ‘arst’ has an entry in the key. Remember, ‘arst’ is an anagram of ‘star’.
- Test if the sorted letters (
var br2 = trimmed[(i)..].OrderBy(c => c).Aggregate("", (p, c) => p + c);- Now take the second part of the science branch and do the same thing
- The only thing that is different is how we take the last part of the original, namely,
trimmed[(i)..]
- This means “take a substring starting at position i, up to the very end
if (wordDic.ContainsKey(br2))- Like before, check if the sorted letters “br2” have any anagrams,
- If so, we have a potential solution!
Remember, the list answers is bound to the display grid, so merely adding it causes it to be displayed. It is then up a human to decide whether the displayed anagrams are actually studied as part of the science branch.
Get the Code to Solve the Puzzle
You can download my complete code, including my list of 716 branches of science, here. Note that you will need a DropBox account to use that link, but that is free. Also, you will need a list of English words; you can get one here. You will need to modify your version of the code to reflect the path where you save this file.
NPR Sunday Puzzle – Language on 3 Adjacent Phone Keys – Solved in Python
Link to the NPR puzzle.
This week’s challenge: What language in seven letters can be spelled using the letters on three consecutive keys on a telephone? It’s a language you would probably recognize, but not one that many people can speak.

This is an easy and fun puzzle that only requires basic tools to solve. I elected to solve the puzzle using Python. Some of the language features used include:
- String handling
- String length
- strip method
- casefold method
- Dictionaries
- Looping
- Basic logic and arithmetic operations
- File reading
Basic Approach
- Build a
dictionarylinking alphabetic letters to keyboard numbers - Open the file containing language names
- Loop through each line in the file
- Use the
stripmethod to make sure the language name has no trailing blanks or newlines - If the language name has length other than 7, go to the next line
- Create two integer variables to reflect the highest and lowest key used by the language, ‘
minKey‘ and ‘maxKey‘- Consider how to type the language ‘Klingon’ on your keypad:
- The highest key is 6, the lowest key is 4. Because K and I are on key 4, while O and N are on key 6
- We know that Klingon is a valid solution because it uses keys 4, 5, 6, which form a set of 3 adjacent keys, as required by the puzzle
- Now, loop through each letter in the language name
- Use our dictionary to look up the key for each letter
- If the current key is lower than the lowest so far, update
minKey - Likewise, update
maxKeyif the current key is higher than the previous max - If the difference between
minKeyandmaxKeyis greater than 2, move to the next line - Finally, after processing every letter in the language, if we haven’t disqualified it, print the language name to the console

Now, let’s look at each of those steps along with the code to implement it. We’ll start with building the dictionary.
Code to Build the Dictionary
import string
# Build a dictionary whose key is the letter and whose value is the keypad key
# For example, keyDic['a'] = 2 because letter 'a' is on key 2
# Another example, keyDic['s'] = 7 because letter 'S' is on key 7
keyDic = {}
key = 0
for lc in string.ascii_lowercase:
# insert an entry into the dictionary, note that // performs integer division
keyDic[lc] = 2 + (key // 3)
# There are letters (PQRS) on key 7 and also 4 on key 9 (WXYZ)
if lc != 'r' and lc != 'y':
key += 1
Interpretation: Build an empty dictionary with this line: “keyDic = {}”. The loop iterates the range consisting of the lower case ascii letters, ‘a’ through ‘z’. We are able to do this by importing string (note the first line of code). Note that integer division ignores fractional values, so 3.333 becomes 3.
We add new entries to the dictionary with this statement: “keyDic[lc] = 2 + (key // 3)”
The dictionary looks like this, note the 4 entries sharing value 4 (PQRS) and the 4 entries sharing value 9 (WXYZ):
{'a': 2,
'b': 2,
'c': 2,
'd': 3,
'e': 3,
'f': 3,
'g': 4,
'h': 4,
'i': 4,
'j': 5,
'k': 5,
'l': 5,
'm': 6,
'n': 6,
'o': 6,
'p': 7,
'q': 7,
'r': 7,
's': 7,
't': 8 ,
'u': 8,
'v': 8,
'w': 9,
'x': 9,
'y': 9,
'z': 9 }
Interpretation: look at the first line. The key is ‘a’, its associated value is 2, because a is on the keboard pad for 2.
Code to Open the Language File and Loop Through Each Line
# This file contains 472 languages from Wikipedia, including constructed languages:
fPath = "C:\\Users\\Randy\\Documents\\LearnPython\\LanguagList.txt"
fHandle = open(fPath, "r", encoding='utf-8')
# Loop handles one language each pass
for aLine in fHandle:
Interpretation: the file name is in a variable ‘fPath’. We need double slashes (i.e. ‘\\’) to separate the path because, normally, \ is uses as a prefix for characters that interfere with the quotation marks. Note that I have to specify the file encoding, i.e. utf-8, because some language names have special characters, such as the languages ‘Brežice’ or ‘Kēlen’.
Code to Clean the Line of code
# Loop handles one language each pass
for aLine in fHandle:
# Need to remove the newline character
cleanLine = aLine.strip()
Check the length of the language
# Puzzle requirements specifies the language has length seven:
if len(cleanLine) == 7:
Interpretation: we’re in a loop, we execute the following lines only if the length is seven
Declare and Initialize Variables minKey and maxKey
#To initialize the minKey/maxKey variables, we use the 1st character
ltr1 = cleanLine[0].casefold()
if ltr1 in keyDic:
# these two variables reflect the highest and lowest keys on the keypad
# as used by the language name
minKey = keyDic[ltr1]
maxKey = keyDic[ltr1]
Interpretation: get the first letter in the language, i.e. ‘cleanLine[0]’. Like every other letter in the language name, we check if it exists in the dictionary before accessing the dictionary value. The ‘casefold’ method converts it to lower case. minKey and maxKey share the same value at first; that will change shortly.
Loop Through the Letters in the Language
# loop through the letters in the language, after converting to
# lower case, and skipping the first character, which we already looked at
for c in cleanLine.casefold()[1:]:
if c in keyDic:
# look up the key for the language letter:
key = keyDic[c]
if key < minKey:
minKey = key
if key > maxKey:
maxKey = key
Interpretation: we already looked at the first letter and we won’t reprocess it. So we slice the word using indexing, i.e. [1:]. (Look at the end of the first line of code in the sample above). This indexing means ‘give me the slice starting at position 1, through the end of the word’. We check if the letter is in the dictionary and update minKey or maxKey as necessary.
If the difference between minKey and maxKey is greater than 2, move to the next line
# The puzzle says the language can be spelled by 3 consecutive keys
if maxKey - minKey > 2:
# Since the diffenece is more than 2, it doesn't qualify
# for example, if maxKey = 4 and minKey = 2, then it qualifies
# but when maxKey = 5 and minKey = 2, it does not
qualifies = False
break
else:
# the letter is not on the keypad, probably it is
# a non-standard letter like â, å, -, etc
qualifies = False
break
Print the Language Name if it Hasn’t Been Disqualified
if qualifies:
print(cleanLine)
That’s it! The code loops around after this last statement and processes the next language name. It runs in a couple milliseconds and we get the output shown below:

Get the Code
I uploaded my code (just 67 short lines) to my DropBox account, along with my language file (472 language names from Wikipedia). You can download the code here: get the code here. Note: you will need your own DropBox account (free).
NPR Puzzle Solved: Actress From the Past
The Challenge
Name a famous actress of the past whose last name has 5 letters. Move the middle letter to the end to name another famous actress of the past. Who are these actresses?
Challenge URL
http://www.npr.org/2014/07/06/328876287/if-you-cut-in-the-middle-go-to-the-end-of-the-line
Summary
I downloaded every kind of actress list I could find (Romanian, Scottish, Khmer, actors who have played Elvis, actors who have played Santa Claus, yada, yada, yada,) After screen-scraping 109 different actor/actress lists, you can bet I was relieved that my code finally worked!
What You Could Learn Here
- .NET string manipulation techniques – useful for many tasks!
- Simple file I/O
- Simple dictionary usage

My Approach
- Read all the actress files, each in turn
- In every file, identify the last name for each actress
- Store the actress in a dictionary,
- Using the last name as the dictionary key
- And the full name as the value
- Now, iterate the dictionary,
- Manipulate the letters in each entry’s key, moving the middle letter to the end, to form a candidate
- For example, “garbo” → “gabor”
- If the dictionary contains a key matching the candidate, we have a solution!
- We check this using the dictionary method ‘ContainsKey’
Code That does the Magic!
Here is the code that does most of the work. It uses a subroutine ‘LoadActressFile’ to build the dictionary from a file.
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Dictionary<string, string> actressDic = new Dictionary<string, string>();
//Load all the text files in current folder
string[] allActressFiles = Directory.GetFiles(".", "*.txt");
foreach (string fName in allActressFiles) {
//If the file name contains 'Actress', proceed
if (Regex.IsMatch(fName, ".*?actress.*", RegexOptions.IgnoreCase)) {
LoadActressFile(actressDic, fName);
}
}
foreach (KeyValuePair<string, string> kvp in actressDic) {
//Combine the first 2 letters, then the last, then letters 2-3
string candidate = kvp.Key.Substring(0, 2)
+ kvp.Key.Substring(3)
+ kvp.Key.Substring(2, 1);
//For some actresses, when you manipulate their names,
//you get the same result, such as 'Foxxx' --> 'Foxxx', so ignore
if (candidate != kvp.Key) {
//Do we have a winner?
if (actressDic.ContainsKey(candidate)) {
//Append the result to the textbox:
txtAnswer.Text += kvp.Value + " - "
+ actressDic[candidate] + "\n";
}
}
}
}
Here is my method to load the dictionary, ‘LoadActressFile’
private static void LoadActressFile(Dictionary<string, string> actressDic, string fileName) {
using (StreamReader sr = File.OpenText(fileName)) {
while (sr.Peek() != -1) {
string anActress = sr.ReadLine();
//Find the last name, it is after the last space char:
int p = anActress.LastIndexOf(' ');
string lastName= anActress.Substring(p + 1).ToLower();
if (lastName.Length == 5) {
//If there is a duplicate key, append to existing value
if (actressDic.ContainsKey(lastName)) {
actressDic[lastName] += "," + anActress;
} else {
actressDic.Add(lastName, anActress);
}
}
}
}
}
Dictionaries are Fun!

- Dictionaries utilize hashing lookups for extreme efficiency
- This means I can check if ‘garbo’ is in the dictionary without looking at every entry, which would be slow!
- Dictionaries use brackets and a key to fetch a value out of the dictionary, like this:
- string anActress = actressDic[“garbo”];
- The key above is ‘garbo’. I used a string, but a variable containing ‘garbo’ also works.
- But, this would cause an error if there is no entry with a key of ‘garbo’!
- So, to avoid errors, you always test before retrieving with a key:
- if (actressDic.ContainsKey(“garbo”)) { … }
- To add to a dictionary, use the ‘Add’ method and provide a key and a value, like this:
- actressDic.Add(“gabor”, “Eva Gabor”);
- If the dictionary already has a key ‘garbo’, that would cause an error. Keys must be unique!
- So, when building the dictionary, if I find a collision, I append the second actress to the pre-existing value
-
-
if (actressDic.ContainsKey(lastName)) { //Append the new actress to the existing entry: actressDic[lastName] += "," + anActress; } else { actressDic.Add(lastName, anActress); }
-
Summary
Once you have the correct list of actresses, solving is a simple matter of string manipulation and checking if your manipulation results in another last name.
NPR Puzzle Solved: June 29, 2014
The Challenge:
This week’s challenge comes from Steve Baggish of Arlington, Mass., the father of the 11-year-old boy who created the challenge two weeks ago. Name a boy’s name and a girl’s name, each in four letters. The names start with the same letter of the alphabet. The boy’s name contains the letter R. Drop that R from the boy’s name and insert it into the girl’s name. Phonetically, the result will be a familiar two-word phrase for something no one wants to have. What is it?
Challenge URL
Link to the Sunday Puzzle
Overview
This was kind of interesting: even though my code won’t yield an exact solution, I was still able to produce a short list of potential solutions and then manually pick the best answer from that list. Main problem: the English language does not have simple pronunciation rules! I am using the Soundex algorithm to compare the pronunciation of phrases against words I construct (from boy/girl names), and the Soundex algorithm is only an approximation. Among its many drawbacks, Soundex doesn’t account for differences in vowel pronunciation. Creating your own replacement for Soundex is a lot of work, email me if you have a better way!
The soundex algorithm is a very useful algortithm; if you read this article, you will learn one good way to use it. You can download implementations of the algorithm from many places; I think I got my version from the Code Project. I have a link below to its description on Wikipedia.
You can also learn from my examples using Linq and .NET Dictionaries, both very useful tools to master!
Solution

Algorithms I Used
Soundex Algorithm for Mapping Pronunciation
The Soundex function takes a string for input and generates a number that corresponds to the pronunciation. Words that sound alike have similar soundex values. For example,
- Soundex(“Robert”) == R163
- Soundex(“Rupert”) == R163
- Soundex(“Rubin”) == R150
- Since Robert sounds a lot like Rubert, both names have the same soundex value.
- As you can see, the soundex algorithm is just an approximate way to match similar words; according to soundex, “bated” sounds the same as as “bad” (because they both have the same soundex value of B300)
In my solution (explained below), I manipulate boy/girl names to construct candidate solutions. If my two candidate names have the same soundex values as a common phrase, then I know that boy and girl might be the answer I seek.
You could use the Soundex algorithm for a customer service app, when the customer talks with marbles in their mouth and your users need to quickly find possible spellings for what customer is telling them!
Levenshtein Distance for Measuring String Similarity
The Levenshtein Distance indicates the similarity of two strings. The modified algorithm I used, computes a distance between 0 and 100; when the distance is 100, the two strings have nothing in common, when their distance is 0, they are identical. The lower the number, the more similar. For example,
- LevenshteinDistance(“kitten”, “kitting”) == 28
- LevenshteinDistance(“kitten”, “sitting”) == 42
- ImprovedLevenshteinDistance(“kitten”, “asdf”) == 100
Thanks to Sten Hjelmqvist for his improved implementation of the Levenshtein altorithm, which you can download here: Code Project Article by Sten.
Why do I need the Levenshtein distance? Because the soundex algorithm is an imperfect mapping. For example, “Bated breath” and “bad breath” have the same soundex scores. But, by using Levenshtein, whenever to phrases have the same soundex score, I can pick the phrase which is closest to the original words. In this case, “BadBreth” is closer to “bad breath” than “bated breath”, because the the Levenshtein distance is smaller.
Sten uses Levenshtein distance to judge how much web pages have changed; apparently he crawls a lot of sites and needs to know who has been updated a lot.
Data
I got a list of boy and girl names from government web site a few years ago and now I can’t find the link. It might have been from the census bureau. If anyone wants a copy of my name files, leave a comment with your email and I can send them.
I got the list of phrases from various web sites and built my own list, using regular expressions and screen scraping techniques that I have explained in previous articles. Again, if anyone wants a copy of my list, leave a comment with your email.
My Approach
- Build a dictionary ‘phraseSoundexPairs’ containing:
- For dictionary value, use Phrases . Per puzzle instructions, only use 2-word phrases where each word has length == 4
- For the dictionary entry keys, use the Soundex values of the two words
- For example, the dictionary entry for “bad breath” will receive a key of “B300B630”, where B300 is the soundex of “bad” and B630 is the soundex of “breath”.
- Why did I construct my key this way? Because I can easily determine if any a candidate boy/girl matches (based on soundex) the pronunciation of any phrase in the dictionary. If the candidate soundex does not match any dictionary keys, then I know it is not a solution.
- Find all the boy names with length 4, make a list
- Find all the girl names with length 4, make a list
- Using Linq, join (match) the two lists on their first letters, rejecting any boy names that don’t contain the letter ‘r’
- Now, iterate the result of the join above
- For each match, remove the r from the boy and insert it into the girl’s name (there are 5 possible positions to insert it)
- For example, manipulate “brad” –> “bad”, “beth” –> “rbeth”, “breth”, “berth”, “betrh”, “bethr”
- Compute the soundex for the manipulated boy/girl name and check if it is in the dictionary. If so, we have a possible solution!
-
- Soundex(“bad”) == B300
- Soundex(“breth”) == B630
- Candidate key –> “B300B630”
- My dictionary has a matching key!
- phraseSoundexPairs[“B300B630”] == “bad breath”, telling us we have the solution!
- Since my dictionary actually has several entries with similar soundex values, use the Levenshtein distance to find the best among those similar entries.
- For example, “bated breath” and “bad breath” both have the same soundex scores, but the Levenshtein distance is better for “bad breath”
The Top-Level Code
Take a look at the top-level code that solves the puzzle and writes the answer to a textbox named ‘tbAnswer’:
private void btnSolve_Click(object sender, RoutedEventArgs e) {
tbAnswer.Clear();
//Load the boy and girl names into the list, restricting them to length 4:
List<string> boyList = LoadNameFile(
DATA_FOLDER + BOY_FILE, NAME_LENGTH);
List<string> girlList = LoadNameFile(
DATA_FOLDER + GIRL_FILE, NAME_LENGTH);
//Build a dictionary containing value= phrases, key=soundex scores
Dictionary<string, string> phraseSoundexPairs
= BuildSoundex_PhraseDictionary();
//Join the two lists on their first letters:
var namePairs = from b in boyList join g in girlList
on b.Substring(0, 1) equals g.Substring(0, 1)
where b.Contains('r') &&
b.Length == 4 &&
g.Length == 4
select new { Boy = b, Girl = g };
//Iterate the joined result and construct candidate soundex values:
foreach (var aPair in namePairs) {
string boyName = aPair.Boy.Replace("r", "");
string boySoundex = PuzzleHelper.Soundex(boyName);
//There are 5 ways to construct each girl name,
//because there are 5 places to insert the 'r'
for (int p = 0; p < 5; p++) {
string girlName = aPair.Girl.Insert(p, "r");
string girlSoundex = PuzzleHelper.Soundex(girlName);
//Check if we have a dictionary entry composed
//of both soundex values
if (phraseSoundexPairs.ContainsKey(boySoundex + girlSoundex)) {
//Use Levenstein distance to find the best match
//if multiple are present:
string closestPhrase = ClosestMatchFromCSVEntries(
phraseSoundexPairs[boySoundex + girlSoundex],
boyName + girlName);
tbAnswer.Text +=
string.Format
("Phrase: {0}/Boy:{1} Girl: {2} (Manipulated boy: {3}, Manipulated girl:{4})\n",
closestPhrase, aPair.Boy, aPair.Girl, boyName, girlName);
break;
}
}
}
}
Finding the Closest Match using Levenshtein Distance
This method takes an entry from the dictionary and splits it on commas. (Because when I have multiple phrases with the same soundex value, I append the new phrase using a comma to separate them.) Using Linq, I make a list of anonymous type containing the distance and the phrase, then choosing the first entry from that list, which has the lowest distance.
private string ClosestMatchFromCSVEntries(string csvPhrases, string combinedName) {
var distList = from p in csvPhrases.Split(',')
select new {
dist = PuzzleHelper.ImprovedLevenshteinDistance(combinedName, p),
Phrase = p };
return (from p in distList
orderby p.dist
select p
).First().Phrase;
}
Notes: Loading the Name Lists and Building the Dictionary
I don’t bother to explain function “LoadNameFile”; you should find it pretty easy to load the boy/girl names from file and construct a list; I only used simple C# IO methods. For examples, please refer to some of my previous puzzle solutions. Constructing the dictionary is a little bit tricker, only because of how I handle duplicate keys. It is easier just to display the code:
private static Dictionary<string, string> BuildSoundex_PhraseDictionary() {
Dictionary<string, string> result = new Dictionary<string,string>();
using (StreamReader sr = File.OpenText(DATA_FOLDER + PHRASE_FILE)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine().ToLower().Trim();
//Look for phrases containing exactly 1 space,
//ie. 2-word phrases
if (aLine.Where(c => c == ' ').Count() == 1) {
int p = aLine.IndexOf(' ');
string word1 = aLine.Substring(0, p);
string word2 = aLine.Substring(p + 1);
if (PuzzleHelper.AllLettersAreAlpha(word1 + word2)) {
string soundex = PuzzleHelper.Soundex(word1)
+ PuzzleHelper.Soundex(word2);
//The only tricky part: if two phrases have the same
//soundex, then append the second phrase after a comma:
if (result.ContainsKey(soundex)) {
result[soundex] += ", " + aLine;
} else {
result.Add(soundex, aLine);
}
}
}
}
}
return result;
}
Alternative Solution
I am not totally happy with this approach, due to difficulties with pronouncing English words, as discussed above. I considered using my list of common words mapped to their phonemes, which I downloaded from Carnegie Mellon University. (A phoneme is a way to pronounce a single syllable; the list of Phonemes for English consists of every possible sound we use in our common language.) That approach would have had the advantage of mapping words onto a value one-to-one. That would eliminate any duplicates from my list. Unfortunately, that list does not have any mappings for imaginary words like ‘breth’, so I can’t use it.
Summary
I hope you enjoyed this solution; Soundex has a number of uses, as does the Levenshtein distance. If you can use either of these in your code, leave a comment to that effect! I also hope you enjoyed my simple example of using Linq to join the list of boys and girls, I found that particular piece of code rather pleasing.
Body Parts From Literary Character – NPR Puzzle!
The Challenge:
This week’s challenge comes from listener Steve Baggish of Arlington, Mass. Name a title character from a classic work of fiction, in 8 letters. Change the third letter to an M. The result will be two consecutive words naming parts of the human body. Who is the character, and what parts of the body are these?
Link to the puzzle: http://www.npr.org/2014/02/09/273644645/break-loose-break-loose-kick-off-your-sunday-shoes

Satisfying, But Complex!
I was able to solve this one with
- A list of book titles I previously harvested from http://www.goodreads.com
- A list of boy and girl names I got from the census bureau a long time ago (sorry, can’t find the exact link)
- Various lists of body parts I scraped from some English Vocabulary sites, such as http://www.enchantedlearning.com/wordlist/body.shtml
- A list of English words I got from puzzlers.org
- A list of prepositions I got from http://www.englishclub.com/grammar/prepositions-list.htm
The Algorithm
The hard part was identifying names from my book list, especially when you consider that the winner is no longer a common name, even though he is featured in the title of three books. Many more book characters are not common names! The basic idea is to examine the list of books and consider, as a name candidate, any words that meet the following criteria:
- If it is used in a possessive, such as “Charlotte’s Web”
- Or if it is found in our first-name list (boys and girls), and has 8 letters
- Or if it is a word pair, starting with an entry in our first-name list
- Or if the length of the title is exactly 8 letters, excluding spaces, hyphens, like “Jane Eyre”
- Finally, if it is a word or word pair preceded by a preposition, such as “Flowers for Algernon”
Once we have the list of candidate names, we compare them against our list of body parts. After, of course, substituting ‘m’ for the 3rd character.
The shortest body part in my list has length 3; each literary name has length 8. We also know, from Will’s directions, that the two body-part words are consecutive. Therefore, each literary name can be split three different ways, which we perform with a loop htat splits the name into 3 candidates, such as
- gum/liver
- guml/iver
- gumli/ver
I elected to store my books and associated names in a dictionary; the name (e.g. ‘gulliver’) will be my key, while the value will be the book title. You can loop through a .NET dictionary using a for-each loop, and each entry will be a KeyValuePair, in my case, using string data type for the key and string data type for the value.
For each dictionary pair (name/book title), split the name, and if we can find both resulting words in our body parts list, we have a winner! As discussed above, there are 3 ways to split each name.
Code Snippet for the Win
//Loop through the dictionary 'characterDic'; each entry is a name (the key) and a value (book title)
foreach (KeyValuePair<string, string> kvp in characterDic) {
//replace 3th letter with 'M',
//for example 'gulliver' --> 'gumliver'
string theCharacter = kvp.Key.Substring(0, 2)
+ "m" + kvp.Key.Substring(3);
//Chop theCharacter at several points to see
//if they might be body parts
for (int divPt = 3; divPt <= 5; divPt++) {
string word1 = theCharacter.Substring(0, divPt);
string word2 = theCharacter.Substring(divPt);
//Check if both words are found in our body
//parts list using BinarySearch
//Binary search returns an index, which will be
//greater or equal to zero, where the search item was found
if (bodyPartsList.BinarySearch(word1) >= 0
&& bodyPartsList.BinarySearch(word2) >= 0) {
//Append the two words, plus the book
//title(s) to the text box for ansers
txtAnswers.Text += word1 + "+" + word2 + " ? " + kvp.Value + "\n";
}
}
}
Notes
- Binary search is very fast (it runs in O(Log(n)) time; I could have used a dictionary for even more speed but my lists aren’t that big. As noted above, when you run a .NET binary search, it returns the index of the entry if it finds what you searched for.
- I used a dictionary for the characters and their associated title characters, not for the speed, but because it offers a convenient way to store a pair and avoid duplicates. As you probably noticed from my solution screen shot, ‘Gulliver’ is the title character in 3 books
- To handle that, I elected to use ‘Gulliver’ for the dictionary key, when I found other books with the same title character, I simply appended the new book name to the entry whose key is ‘Gulliver’
Code Listing
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Input;
using System.IO;
using System.Text.RegularExpressions;
namespace Feb_9_2014 {
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window {
private const string BOOK_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\CleanedBookList.txt";
private const string BODY_PARTS_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\BodyPartsList.txt";
private const string BOY_NAME_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\CommonBoyNames.txt";
private const string GIRL_NAME_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\CommonGirlNames.txt";
private const string PREPOSITION_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\EnglishPrepositions.txt";
private const string WORD_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\web2.txt";
//links to body parts list:
//http://www.ego4u.com/en/cram-up/vocabulary/body-parts
//http://www.enchantedlearning.com/wordlist/body.shtml
//Booklist from http://www.goodreads.com
public MainWindow() {
InitializeComponent();
}
/// <summary>
/// Fired when user clicks the Solve button
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
//Build a unique list of names from the census list of first names:
List<string> firstNameList = new List<string>();
AugmentNameListFromFile(BOY_NAME_LIST, firstNameList);
AugmentNameListFromFile(GIRL_NAME_LIST, firstNameList);
//Most of the work is done here, creating potential
//character names from m list of books
Dictionary<string, string> characterDic
= Build8LetterCharcterList(firstNameList);
List<string> bodyPartsList = BuildBodyPartsList();
//Now use our list of potential character names
//and the body parts list to solve:
foreach (KeyValuePair<string, string> kvp in characterDic) {
//replace 3th letter with 'M',
//for example 'gulliver' --> 'gumliver'
string theCharacter = kvp.Key.Substring(0, 2)
+ "m" + kvp.Key.Substring(3);
//Chop theCharacter at several points to see
//if they might be body parts
for (int divPt = 3; divPt <= 5; divPt++) {
string word1 = theCharacter.Substring(0, divPt);
string word2 = theCharacter.Substring(divPt);
//Check if both words are found in our body
//parts list using BinarySearch
//Binary search returns an index, which will be
//greater or equal to zero, where the search item was found
if (bodyPartsList.BinarySearch(word1) >= 0
&& bodyPartsList.BinarySearch(word2) >= 0) {
//Append the two words, plus the book
//title(s) to the text box for ansers
txtAnswers.Text += word1 + "+" + word2 + " ? " + kvp.Value + "\n";
}
}
}
Mouse.OverrideCursor = null;
}
/// <summary>
/// Reads a file, finds the boy/girl name at position 1-15,
/// and adds to the list if not already present
/// </summary>
/// <param name="fName">File Name containing boy/girl names</param>
/// <param name="firstNameList">List to augment</param>
/// <remarks>
/// The list we build will be sorted by virtue of how we insert new names
/// </remarks>
private void AugmentNameListFromFile(string fName, List<string> firstNameList) {
using (StreamReader sr = File.OpenText(fName)) {
while (sr.Peek() != -1) {
string aName = sr.ReadLine().ToLower().Substring(0, 15).TrimEnd();
int p = firstNameList.BinarySearch(aName);
if (p < 0) {
//When p < 0, it means the name is not present in the list
//Also, when we invert p, that becomes the index where
//it belongs to keep the list sorted
firstNameList.Insert(~p, aName);
}
}
}
}
/// <summary>
/// Builds a dictionary of character names (8 letters long)
/// and the book titles they are found in
/// </summary>
/// <param name="firstNameList">List of fist names</param>
/// <returns>The dictionary</returns>
/// <remarks>
/// We will consider a word a name if
/// 1) it is used in the possessive, such as "Charlotte's Web"
/// 2) It is found in our first-name list and has 8 letters
/// 3) It is a word pair starting with an entry in our first-name list
/// 4) The length of the title is 8 letters,
/// excluding spaces, hyphens, like Jane Eyre
/// 5) It is a word or word pair preceded by a preposition,
/// such as Flowers for Algernon
/// </remarks>
private Dictionary<string, string> Build8LetterCharcterList(List<string> firstNameList) {
Dictionary<string, string> result = new Dictionary<string, string>();
//the word list will contain almost every English
//word that is not in our firstname list
List<string> wordList = BuildWordList(firstNameList);
//A list of 50 words like to/as/for
List<string> prepositionList = BuildPrepositionList();
//This Regular expression will detect 8 (or 9 with a space)
//letter words followed by apostrphe s
Regex rePossive = new Regex(@"
( #start capture group
\b #Demand a word break
[A-Za-z\s] #any letter a-z, lower or upper case, plus space
{8,9} #The preceeding must have length 8 or 9
\b #demand another word break
) #close our capture group
's #demand apostrphe s",
RegexOptions.Multiline | RegexOptions.IgnorePatternWhitespace);
//Loop through the book list and see if each title
//matches any of the listed conditions
//Each method will add to the dictionary using the
//character name as the key and the title as the value
using (StreamReader sr = File.OpenText(BOOK_LIST)) {
while (sr.Peek() != -1) {
string title = sr.ReadLine();
CheckPossive(title, rePossive, result, wordList);
Check8LetterNames(firstNameList, result, title);
CheckFullTitle(title, result);
CheckPreposition(title, prepositionList, wordList, result);
}
}
return result;
}
/// <summary>
/// Opens the WORD_LIST file and adds every entry which
/// is not found in the list of first names
/// </summary>
/// <param name="firstNameList">Sorted list of first names</param>
/// <returns><The list of words/returns>
/// <remarks>
/// The word list is useful to reject potential character names
/// which might be a common English word
/// </remarks>
private List<string> BuildWordList(List<string> firstNameList) {
List<string> result = new List<string>();
using (StreamReader sr = File.OpenText(WORD_LIST)) {
while (sr.Peek() != -1) {
string aWord = sr.ReadLine().ToLower();
if (firstNameList.BinarySearch(aWord) < 0) {
result.Add(aWord);
}
}
}
return result;
}
/// <summary>
/// Builds a list of prepositions (string) from the file
/// PREPOSITION_LIST, which is already sorted
/// </summary>
/// <returns>The list of words</returns>
private List<string> BuildPrepositionList() {
List<string> result = new List<string>();
using (StreamReader sr = File.OpenText(PREPOSITION_LIST)) {
while (sr.Peek() != -1) {
result.Add(sr.ReadLine());
}
}
return result;
}
/// <summary>
/// Examines every word in the specified title to determine
/// if it matches the possive form (and have 8-9 characters)
/// </summary>
/// <param name="title">A book title to search</param>
/// <param name="rePossive">A regular expression that will
/// match a possessive form</param>
/// <param name="characterTitleDic">Dictionary to add results to</param>
/// <param name="wordList">List of english words to exclude</param>
private void CheckPossive(string title, Regex rePossive,
Dictionary<string, string> characterTitleDic,
List<string> wordList) {
Match m = rePossive.Match(title);
if (m.Success) {
string candidate = m.Groups[1].Value.ToLower().Trim().Replace(" ", "");
if (candidate.Length == 8 && wordList.BinarySearch(candidate) < 0) {
if (characterTitleDic.ContainsKey(candidate)) {
characterTitleDic[candidate] += ", " + title;
} else {
characterTitleDic.Add(candidate, title);
}
}
}
}
/// <summary>
/// Examines the specified title to see if any words could
/// be an 8-letter first name or else a first name followed
/// by any other word when the pair has a combined length of 8
/// </summary>
/// <param name="firstNameList">List of first names</param>
/// <param name="characterTitleDic">List to add the result to</param>
/// <param name="title">Book title that might contain names</param>
/// <remarks>
/// We could have a hit under two conditions:
/// 1) We find an 8-letter name in the title, such as 'JONATHAN'
/// 2) We find a name of any length followed by another word,
/// such as 'Jane Eyre', the two having a combined
/// length of 8
/// </remarks>
private void Check8LetterNames(List<string> firstNameList,
Dictionary<string, string> characterTitleDic, string title) {
string[] words = title.ToLower().Split(' ');
for (int i = 0; i< words.Length; i++) {
string aWord = words[i];
//Check case 1, 8 letter names
if (aWord.Length == 8 && firstNameList.BinarySearch(aWord) >= 0) {
if (characterTitleDic.ContainsKey(aWord)) {
characterTitleDic[aWord] += ", " + title;
} else {
characterTitleDic.Add(aWord, title);
}
} else if (i < words.Length - 1
&& firstNameList.BinarySearch(aWord) > 0) {
//Case two, we have a first name followed
//by another name with total length of 8
if (aWord.Length + words[i + 1].Length == 8) {
string candidate = aWord + words[i+1];
if (candidate.Length == 8) {
if (characterTitleDic.ContainsKey(candidate)) {
characterTitleDic[candidate] += ", " + title;
} else {
characterTitleDic.Add(candidate, title);
}
}
}
}
}
}
/// <summary>
/// We will identify any titles having length 8 (excluding
/// spaces) and add them to the dictionary
/// </summary>
/// <param name="title">A book title</param>
/// <param name="characterTitleDic">Where we store hits</param>
/// <remarks>
/// For example, 'Jane Eyre'
/// </remarks>
private void CheckFullTitle(string title,
Dictionary<string, string> characterTitleDic) {
string candidate = title.Replace(" ", "").ToLower();
if (candidate.Length == 8) {
if (characterTitleDic.ContainsKey(candidate)) {
characterTitleDic[candidate] += "," + title;
} else {
characterTitleDic.Add(candidate, title);
}
}
}
/// <summary>
/// Identify 8-letter words following a preposition
/// that are not common English words
/// </summary>
/// <param name="title">A book title</param>
/// <param name="prepositionList">List of prepositions</param>
/// <param name="wordList">List of English words
/// that are not first names</param>
/// <param name="characterTitleDic">Dictionary to
/// augment with hits</param>
/// <remarks>
/// Sample: 'A Ball for Daisy'. 'for' is the preposition,
/// 'Daisy' is the word that follows.
/// </remarks>
private void CheckPreposition(string title, List<string> prepositionList,
List<string> wordList, Dictionary<string, string> characterTitleDic) {
string[] words = title.ToLower().Split(' ');
for (int i = 0; i < words.Length; i++) {
string aWord = words[i];
if (prepositionList.BinarySearch(aWord) > 0
&& i < words.Length - 1
&& words[i+1].Length == 8
&& wordList.BinarySearch(words[i+1]) < 0) {
if (characterTitleDic.ContainsKey(words[i + 1])) {
characterTitleDic[words[i + 1]] += ", " + title;
} else {
characterTitleDic.Add(words[i + 1], title);
}
}
}
}
/// <summary>
/// Builds a string list from the body parts in the
/// file BODY_PARTS_LIST, which is already sorted
/// </summary>
/// <returns>The sorted list</returns>
private List<string> BuildBodyPartsList() {
List<string> result = new List<string>();
using (StreamReader sr = File.OpenText(BODY_PARTS_LIST)) {
while (sr.Peek() != -1) {
result.Add(sr.ReadLine().ToLower());
}
}
return result;
}
}
}
Now, the XAML
<Window x:Class="Feb_9_2014.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Title Character to Body Parts" Height="350" Width="725"
WindowStartupLocation="CenterScreen"
Icon="/Feb_9_2014;component/Images/Book.jpg">
<Grid>
<Grid.Background>
<ImageBrush Opacity=".3"
ImageSource="/Feb_9_2014;component/Images/gullivers600x390.jpg" />
</Grid.Background>
<Grid.RowDefinitions>
<RowDefinition Height="auto" />
<RowDefinition Height="auto" />
<RowDefinition />
</Grid.RowDefinitions>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="auto" />
<ColumnDefinition Width="auto" />
<ColumnDefinition />
</Grid.ColumnDefinitions>
<Border Grid.ColumnSpan="3">
<Border.Background>
<LinearGradientBrush EndPoint="0.5,1" StartPoint="0.5, 0">
<GradientStop Color="Black" Offset="0" />
<GradientStop Color="#FFD5CCC0" Offset="1" />
</LinearGradientBrush>
</Border.Background>
<TextBlock HorizontalAlignment="Center" FontSize="36"
Foreground="Chartreuse"
Text="Title Character Plus M ? 2 Body Parts">
<TextBlock.Effect>
<DropShadowEffect />
</TextBlock.Effect>
</TextBlock>
</Border>
<TextBlock Grid.Row="1" Grid.ColumnSpan="3" FontSize="14"
TextWrapping="Wrap" Margin="3" >
This week's challenge comes from listener Steve Baggish of
Arlington, Mass. Name a title character from a classic work
of fiction, in 8 letters. Change the third letter to an M.
The result will be two consecutive words naming parts
of the human body. Who is the character, and what parts
of the body are these?
</TextBlock>
<Button Grid.Row="2" Content="_Solve" Name="btnSolve"
Height="30" VerticalAlignment="Top" Margin="5 0"
Click="btnSolve_Click" FontSize="14" FontWeight="Black" />
<Label Grid.Row="2" Grid.Column="1" Content="_Answer:"
Target="{Binding ElementName=txtAnswers}" FontWeight="Bold" />
<TextBox Grid.Row="2" Grid.Column="3" Name="txtAnswers"
AcceptsReturn="True" TextWrapping="Wrap"
Background="Transparent" FontWeight="Bold"
FontSize="16"/>
</Grid>
</Window>
That’s all!
Puzzle Solved! NPR Sunday Puzzle, 5-Letter Word + AY Anagrams to 7 Letter Related Word
The Challenge:
Name something in five letters that’s generally pleasant, it’s a nice thing to have. Add the letters A and Y, and rearrange the result, keeping the A and Y together as a pair. You’ll get the seven-letter word that names an unpleasant version of the five-letter thing. What is it?

I had a bit of struggle meeting the requirement that the two words be related! Plus, the puzzle forced me to use a big dictionary. There are about 20-30 word pairs that you can re-arrange to anagram, but finding words that are related to each other required me to us an on-line dictionary.
Algorithm Part One: Finding Related Words
I used this dictionary web2.txt from puzzlers.org’s word lists page. It is pretty extensive and I needed it to get a rare word like ‘daymare’.
- Find all the 5-letter words
- Add ‘ay’ and sort the letters
- Put the result into a dictionary –> the key will be the sorted letters; the payload (value) will be the original word
- Now find all the 7-letter words which contain ‘ay’
- Sort their letters and check the dictionary to see if there is any matching key
- If so, we have a pair that might be related
Dictionary<string, string> anagramDic
= new Dictionary<string, string>();
using (StreamReader sr = File.OpenText(WORD_FILE)) {
//Keep reading to the end of the file
while (sr.Peek() != -1) {
string aWord = sr.ReadLine().ToLower();
if (aWord.Length == 5) {
//add 'ay' to the word and sort the letters:
string key = ("ay" + aWord)
.Select(c => c)
.OrderBy(c => c)
.Aggregate("", (r, c) => r + c);
//if it is already in the dictionary, append
//to the value with a comma
if (anagramDic.ContainsKey(key)) {
anagramDic[key] += "," + aWord;
} else {
anagramDic.Add(key, aWord);
}
}
}
}
//Now get the 7-letter words and check whether their sorted letters are keys in the dictionary:
using (StreamReader sr = File.OpenText(WORD_FILE)) {
while (sr.Peek() != -1) {
string aWord = sr.ReadLine();
//the word must be 7 letters long and contain ay
if (aWord.Length == 7 && aWord.Contains("ay")) {
string sorted = aWord
.Select(c => c)
.OrderBy(c => c)
.Aggregate("", (r, c) => r + c);
//Two words are anagrams if they are the same after sorting
//Sort 'cat' --> 'act', sort 'tac' --> also 'act', therefore anagrams
//If the dictionary contains a key composed of the sorted letters, match!
if (anagramDic.ContainsKey(sorted)) {
//This method checks the web site to see if the
//words are related
string synonym
= UrbanDicSynonym(aWord, anagramDic[sorted]);
if (!String.IsNullOrEmpty(synonym)) {
answer += aWord + " - " + synonym + "\n";
}
}
}
}
}
Algorithm Part Two: Determining Whether Two Words are Rough Synonyms
I couldn’t find any decent lists of synonyms, and I only needed to look-up a few dozen word pairs, so I used an on-line dictionary: the Urban Dictionary. You can manipulate their query string to specify which word you want defined, and it will return your definition.
For example, if you paste “http://www.urbandictionary.com/define.php?term=daymare” into your browser address bar, it will build you a page with the definition of daymare. And you can substitute any word you like in place of ‘daymare’. That makes it very convenient to do look-ups in code!
With that in mind:
- Take your matching word pairs from part 1 of the algorithm, such as ‘daymare’ and ‘dream’
- Look-up the first of each pair on the Urban Dictionary, using a WebClient Object, which allows you to perform an OpenRead operation on the URL you build using the word candidate
- Parse the results of the results from your OpenRead operation and extract the parts of the web page you need.
- For Urban Dictionary, the definitions are surrounded by special tags, like this:
-
<div class=definition:>A seriously bad dream, but experienced during daylight hours.</div>
-
- You can extract the text between those tags using a fairly simple regular expression.
- Take all the words you extract and see if any of them are your second word; if so, you probably have a winner!
Here’s the code that does that:
private string UrbanDicSynonym(string word1, string word2) {
string urbanUrl = @"http://www.urbandictionary.com/define.php?term=";
string pattern = @"
<div #Literal match
\s #Whitspace
class=""definition""> #Literal match
([^<]+?) #Capture group/anything but <
</div> #Literal match";
Regex reDef = new Regex(pattern,
RegexOptions.Multiline
|
RegexOptions.IgnorePatternWhitespace);
string[] anagramList = word2.Split(',');
using (WebClient wc = new WebClient()) {
string url = urbanUrl + word1;
using (StreamReader sr = new StreamReader(wc.OpenRead(url))) {
string allText = sr.ReadToEnd();
Match m = reDef.Match(allText);
while (m.Success) {
string payLoad = m.Groups[1].Value;
foreach (string anAnagram in anagramList) {
if (payLoad.IndexOf(anAnagram,
StringComparison.CurrentCultureIgnoreCase) > 0) {
return anAnagram;
}
}
m = m.NextMatch();
}
}
}
return "";
}
Some Nitty-Gritty
Since it is fairly slow to perform web look-ups using the techniques described above, I elected to display a progress bar and cancel button. That, in turn, made it almost necessary to use a Background worker process, which supports cancellation and also makes it easier to update the screen. Without using a separate thread, the progress bar won’t update until after your work is complete! Because the same thread that does the work is the thread that updates the screen.
Here’s the code
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows;
using System.Windows.Controls;
using System.IO; //To read/write to files
using System.Text.RegularExpressions; //To match text patterns
using System.Net; //To fetch data from the web
using System.Windows.Input; //To manipulate the cursor
using System.ComponentModel; //For Background Worker
namespace Jan_5_2014 {
/// <summary>Logic to solve the puzzle</summary>
public partial class MainWindow : Window {
private const string WORD_FILE = @"C:\Users\Randy\Documents\Puzzles\Data\web2.txt";
//You can get this file here:
//http://www.puzzlers.org/dokuwiki/doku.php?id=solving:wordlists:about:start
BackgroundWorker _Wrker;
/// <summary>Constructor</summary>
public MainWindow() {
InitializeComponent();
}
/// <summary>
/// Responds when user clicks the Solve button
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
/// <remarks>
/// First we find all the 5-letter words, append 'ay',
/// and build an anagram lookup dictionary with them,
/// using the sorted letters as the lookup key.
///
/// Then we find all the 7-letter words that contain
/// 'ay' and see if they have a match in the anagram dictionary.
///
/// If we find an anagram pair, look-up the 2nd word
/// in the urban dictionary and see if 1st word is contained
/// any definition returned contains
///
/// </remarks>
private void btnSolve_Click(object sender, RoutedEventArgs e) {
//Instantiate the background worker and wire-up its events
_Wrker = new BackgroundWorker();
_Wrker.WorkerReportsProgress = true;
_Wrker.WorkerSupportsCancellation = true;
_Wrker.RunWorkerCompleted += new RunWorkerCompletedEventHandler(Wrker_RunWorkerCompleted);
_Wrker.ProgressChanged += new ProgressChangedEventHandler(Wrker_ProgressChanged);
_Wrker.DoWork += new DoWorkEventHandler(Wrker_DoWork);
txtAnswer.Clear();
Mouse.OverrideCursor = Cursors.Wait;
tbCurWord.Visibility = System.Windows.Visibility.Visible;
prgBar.Visibility = System.Windows.Visibility.Visible;
btnCancel.Visibility = System.Windows.Visibility.Visible;
_Wrker.RunWorkerAsync();
}
void Wrker_DoWork(object sender, DoWorkEventArgs e) {
string answer = "";
//First build dictionary of 5-letter words using their
//sorted letters, plus "ay", as the key
Dictionary<string, string> anagramDic
= new Dictionary<string, string>();
//This loop will go really fast compared to the next loop
int lineNum = 0;
using (StreamReader sr = File.OpenText(WORD_FILE)) {
while (sr.Peek() != -1) {
lineNum++;
string aWord = sr.ReadLine().ToLower();
if (aWord.Length == 5) {
//add 'ay' to the word and sort the letters:
string key = ("ay" + aWord)
.Select(c => c)
.OrderBy(c => c)
.Aggregate("", (r, c) => r + c);
//if it is already in the dictionary, append
//to the value with a comma
if (anagramDic.ContainsKey(key)) {
anagramDic[key] += "," + aWord;
} else {
anagramDic.Add(key, aWord);
}
}
}
}
//Re-open the word list and get the 7-letter words
int totalLines = lineNum;
lineNum = 0;
using (StreamReader sr = File.OpenText(WORD_FILE)) {
while (sr.Peek() != -1) {
lineNum++;
string aWord = sr.ReadLine();
if (aWord.Length == 7 && aWord.Contains("ay")) {
int pctDone = (int)(100 * lineNum / totalLines);
//progress is current line # / total lines
//include current word
_Wrker.ReportProgress(pctDone, aWord);
string sorted = aWord
.Select(c => c)
.OrderBy(c => c)
.Aggregate("", (r, c) => r + c);
if (anagramDic.ContainsKey(sorted)) {
string synonym
= UrbanDicSynonym(aWord, anagramDic[sorted]);
if (!String.IsNullOrEmpty(synonym)) {
answer += aWord + " - " + synonym + "\n";
}
}
}
//bail out if user cancelled:
if (_Wrker.CancellationPending) {
break;
}
}
}
e.Result = answer;
}
/// <summary>
/// Determines whether the UrbanDictionary lists word1 in
/// the definitions returned by looking-up word 2
/// </summary>
/// <param name="word1">A word whose synomym might be in word 2</param>
/// <param name="word2">A word (or CSV word list)
/// that might be synonym of word 1</param>
/// <returns>The word that is synonym of word 1</returns>
/// <remarks>
/// UrbanDictionary allows lookups passing the word you seek as part
/// of the querystring. For example, you can look-up 'daymare'
/// with this querystring:
/// http://www.urbandictionary.com/define.php?term=daymare
///
/// Their site returns some html with the definitions embedded inside
/// div tags that look like this:
/// <div class="definition">definition is here</div>
///
/// Note that word2 can be a single word or a CSV list of anagrams,
/// such as "armed,derma,dream,ramed,"
/// </remarks>
private string UrbanDicSynonym(string word1, string word2) {
string urbanUrl = @"http://www.urbandictionary.com/define.php?term=";
string pattern = @"
<div #Literal match
\s #Whitspace
class=""definition""> #Literal match
([^<]+?) #Capture group/anything but <
</div> #Literal match";
Regex reDef = new Regex(pattern,
RegexOptions.Multiline
|
RegexOptions.IgnorePatternWhitespace);
string[] anagramList = word2.Split(',');
using (WebClient wc = new WebClient()) {
string url = urbanUrl + word1;
using (StreamReader sr = new StreamReader(wc.OpenRead(url))) {
string allText = sr.ReadToEnd();
Match m = reDef.Match(allText);
while (m.Success) {
string payLoad = m.Groups[1].Value;
foreach (string anAnagram in anagramList) {
if (payLoad.IndexOf(anAnagram,
StringComparison.CurrentCultureIgnoreCase) > 0) {
return anAnagram;
}
}
m = m.NextMatch();
}
}
}
return "";
}
/// <summary>
/// Fires when worker reports progress, updates progress bar
/// and current word
/// </summary>
/// <param name="sender">The background worker</param>
/// <param name="e">Event args</param>
void Wrker_ProgressChanged(object sender, ProgressChangedEventArgs e) {
prgBar.Value = e.ProgressPercentage;
tbCurWord.Text = (string)e.UserState;
}
/// <summary>
/// Fires when the background worker finishes
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
void Wrker_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e) {
txtAnswer.Text = (string)e.Result;
prgBar.Visibility = System.Windows.Visibility.Hidden;
tbCurWord.Visibility = System.Windows.Visibility.Hidden;
btnCancel.Visibility = System.Windows.Visibility.Hidden;
Mouse.OverrideCursor = null;
MessageBox.Show("Sovling complete!",
"Mission Accomplished",
MessageBoxButton.OK, MessageBoxImage.Exclamation);
}
/// <summary>
/// Fires when user clicks the cancel button
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
private void btnCancel_Click(object sender, RoutedEventArgs e) {
_Wrker.CancelAsync();
}
}
}
Now, here’s the XAML
<Window x:Class="Jan_5_2014.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
WindowStartupLocation="CenterScreen"
Title="Anagram Synonym (with A + Y)" Height="300" Width="500">
<DockPanel>
<!-- The status bar has a slider, progress bar and textblock -->
<!-- We define it 1st so the next thing, the main content,
will fill the remaining space -->
<StatusBar DockPanel.Dock="Bottom">
<Slider Name="sldZoom" Minimum=".5" Maximum="2.0" Width="100"
ToolTip="Resize Form" Value="1" />
<ProgressBar Name="prgBar" Minimum="1" Maximum="100"
Visibility="Hidden" Background="DarkBlue"
Height="20"
Foreground="Yellow" Width="200" />
<TextBlock Name="tbCurWord" Visibility="Hidden" />
</StatusBar>
<!-- The Main grid, fills the DockPanel because it is added last-->
<Grid>
<!-- Page header -->
<Border Grid.ColumnSpan="3">
<Border.Background>
<LinearGradientBrush EndPoint="0.5,1" StartPoint="0.5,0">
<GradientStop Color="LightYellow" Offset="0" />
<GradientStop Color="PaleGreen" Offset="1" />
</LinearGradientBrush>
</Border.Background>
<TextBlock FontSize="32" Text="5-Letter Anagram With A + Y"
Foreground="Blue" HorizontalAlignment="Center">
<TextBlock.Effect>
<DropShadowEffect Opacity=".6" BlurRadius="5"
Color="LightBlue" />
</TextBlock.Effect>
</TextBlock>
</Border>
<!-- Challenge -->
<TextBlock Grid.Row="1" Grid.ColumnSpan="3" FontSize="14"
TextWrapping="Wrap" Margin="3">
<Bold>Challenge:</Bold> Name something in five letters
that's generally pleasant, it's
a nice thing to have. Add the letters A and Y,
and rearrange the result, keeping the A and Y
together as a pair. You'll get the seven-letter word
that names an unpleasant version of the five-letter
thing. What is it?
</TextBlock>
<!-- 3 Controls: Solve button/label/answer textbox -->
<Label Grid.Row="3" Content="A_nswer:"
Target="{Binding ElementName=txtAnswer}" />
<TextBox Grid.Row="3" Grid.Column="1" Name="txtAnswer"
TextWrapping="Wrap" AcceptsReturn="True"
VerticalScrollBarVisibility="Auto"
FontSize="14" />
<StackPanel Orientation="Vertical" Grid.Row="3"
Grid.Column="2" VerticalAlignment="Top">
<Button Grid.Row="3" Grid.Column="2" Name="btnSolve"
Height="30" VerticalAlignment="Top"
Margin="3" Content="_Solve"
Click="btnSolve_Click" />
<Button Name="btnCancel" Margin="3" Height="30"
Content="_Cancel"
Visibility="Hidden"
Click="btnCancel_Click" />
</StackPanel>
<!-- The Transform works with the slider to resize window -->
<Grid.LayoutTransform>
<ScaleTransform
ScaleX="{Binding ElementName=sldZoom,Path=Value}"
ScaleY="{Binding ElementName=sldZoom,Path=Value}" />
</Grid.LayoutTransform>
<!-- Define our rows and columns -->
<Grid.RowDefinitions>
<RowDefinition Height="auto" />
<RowDefinition Height="auto" />
<RowDefinition />
</Grid.RowDefinitions>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="auto" />
<ColumnDefinition />
<ColumnDefinition Width="auto" />
</Grid.ColumnDefinitions>
</Grid>
</DockPanel>
<!-- In lieu of linking to a file, I elected to draw
the letters 'ABC' in Xaml -->
<Window.Icon>
<DrawingImage>
<DrawingImage.Drawing>
<GeometryDrawing>
<GeometryDrawing.Geometry>
<RectangleGeometry Rect="0,0,20,20" />
</GeometryDrawing.Geometry>
<GeometryDrawing.Brush>
<VisualBrush>
<VisualBrush.Visual>
<TextBlock Text="ABC" FontSize="8"
Background="Yellow"
Foreground="Blue" />
</VisualBrush.Visual>
</VisualBrush>
</GeometryDrawing.Brush>
</GeometryDrawing>
</DrawingImage.Drawing>
</DrawingImage>
</Window.Icon>
</Window>
that’s all
