
Linq
Sunday Puzzle: Nationality, Demonyms and Consonyms!
This week’s challenge is a spinoff of my (e.g. Will’s) on-air puzzle. Name two countries that have consonyms that are nationalities of other countries. In each case, the consonants in the name of the country are the same consonants in the same order as those in the nationality of another country. No extra consonants can appear in either name. The letter Y isn’t used.
Link to the Challenge
Definition Demonym; noun: A name for an inhabitant or native of a specific place that is derived from the name of the place.
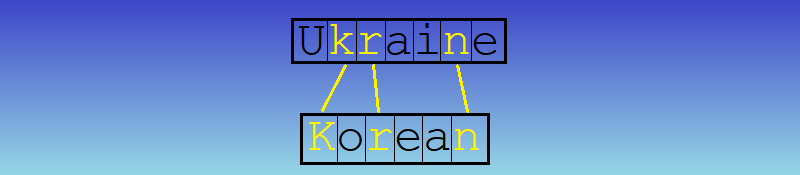
Synopsis
Well, that was a nice, easy, fun one! Happily, I already had a list of nations and their demonyms, so it was just a matter of making two lists and matching them against each other. Each of those two lists contains the original word plus its consonym. One list uses the country as the original word, the other uses nationality as the original word. We match the lists using the consonym.
I elected to use WPF once again, mainly because it produces a nice UI and I am pretty fast in it. The choice of UI is fairly unimportant for solving this puzzle, since there is almost no interaction with the user, other than clicking the Solve button.
If you read through to the end, I’ll explain my big learning moment writing this code. Yes, I made a big mistake because I misunderstood something tricky about Linq. Hopefully you can save time by learning from my goof!
In case anyone is following me, I hope I don’t sound too over-confident in my analysis, possibly discouraging you. I always do the write-up as if I knew what I was doing from the very start, as if solving the puzzle is inevitable due to my great skill 😏. But that is not the case at all! I have a lot of struggles and plenty of dead ends. So I hope you don’t feel unworthy if I accidentally make it sound easier than it truly is. Because in reality, it only seems easy after I finally succeed.
Screenshot Showing My Results:
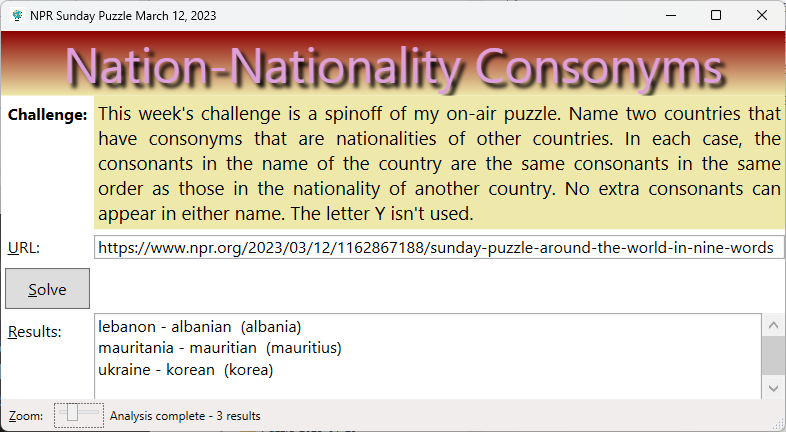
I got 3 results, but from Will’s description, I think he expects two results. I re-read his description a few times and don’t see anything I misinterpreted, so let’s see what he says come Sunday. Maybe there was some confusion over Mauritania and Mauritius, two very similar names.
Techniques Used
Difficulty Level
- Intermediate
- Dogged beginners
Algorithm
We start with a file that looks like the following (you can download your own copy below):
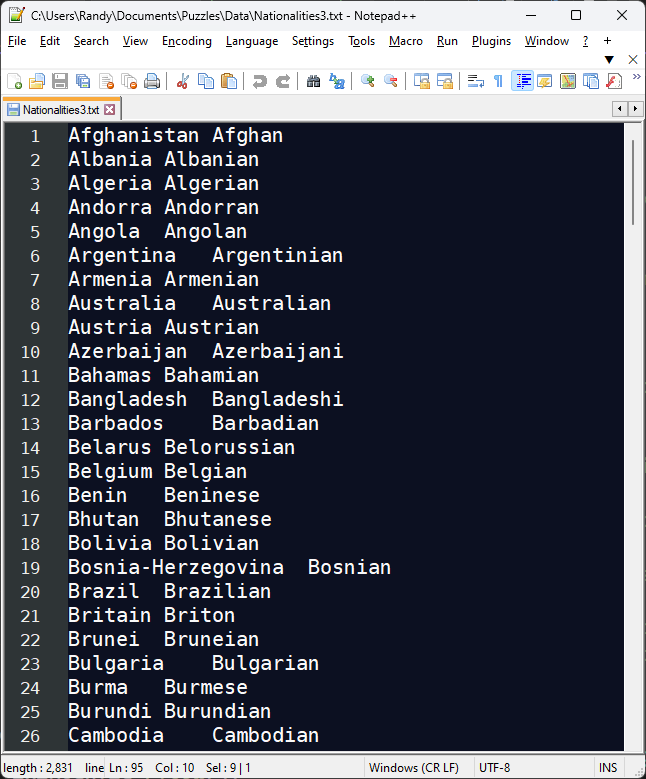
As you can see above, this file has two columns, separated by a tab character. The country comes first, followed by the demonym. Given this file structure, we take the following steps to find a solution:
- Open the file for reading
- Read one line at a time
- Split the line on the tab character, effectively separating the two words
- Build two lists,
- Using the two words from the line we just split
- One list for nationalities
- The other for demonyms
- Each list will contain a data type (a class in this case) which contains the original word and its consonym (refer to the image below)
- After we finish reading the file and building the list,
- Match the two lists using the consonym field
- Note that some countries will match against their own demonym, for example
- Britain → brtn → Briton (consonants “brtn” for both)
- Therefore, when we match the two lists, we need to avoid self-matching by requiring that the matched demonym not come from the original country
Illustration of Matching the Two Lists
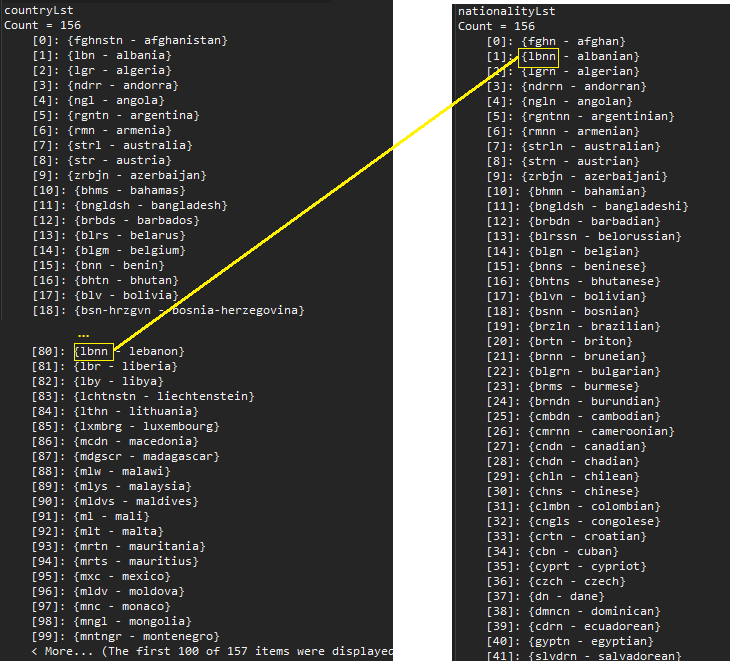
ConsonymWordPair , which consists of the consonants plus the original word. When we match entries on the left against those on the right, we find a match for “lbnn” in both lists. Now we know the two original words share a consonym, one word being a country and the other a nationality. Here’s The Code!
//This is the main method; it runs when user clicks the 'solve' button
private void btnSolve_Click(object sender, RoutedEventArgs e) {
txtResults.Clear();
txtMessage.Text = "";
//1) The subroutine (method) reads my file and builds the two lists:
var (countryLst, nationalityLst) = BuildCountryNationalityLists();
var solutionCount = 0;
//2) Loop through the country list and match against the nationality list
foreach (var c in countryLst) {
//3) Get all the nationalities whose Consonym matches the country's
var matches = nationalityLst.Where(n => n.Consonym == c.Consonym);
foreach (var m in matches) {
//4) 'Mate' is my term for the original country
//I call it 'Mate' to make the class name more generic
//If the country's consonym is the same as its nationalit's, skip it
if (m.Mate != c.Mate) {
//5) Display the results!
txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n";
solutionCount++;
}
}
}
txtMessage.Text = $"Analysis complete - {solutionCount} results";
}
Discussion – Main Method
🙆🏻I really like how short the main method is, it makes me feel good to write concise code that does something useful and, hopefully, something cool!
Numbered notes below correspond to the numbered comments above. If you already understand the code above, skip ahead to the next heading!
- The subroutine reads my file and builds the two lists
var (countryLst, nationalityLst) = BuildCountryNationalityLists();- That subroutine (‘
BuildCountryNationalityLists‘) is listed below - Note that this method returns two variables,
countryLstnationalityLst
- Which is one of my favorite features of .NET!
- Both lists contains
ConsonymWordPairelements (a class defined below)
- Loop through the country list and match against the nationality list
foreach (var c in countryLst) {- The variable ‘
c‘ is an instance of my class ‘ConsonymWordPair‘ - And we will examine all 156 of them, one per loop pass
- Get all the nationalities whose Consonym matches the country’s
- The Linq method
Wheredoes a search on the listnationalityLstvar matches = nationalityLst.Where(n => n.Consonym == c.Consonym);n.Consonymrefers to the nationality consonym- c
.Consonymrefers to the demonym consonym (say that 3 times fast!)
- And returns all the matches.
- Theoretically there could be more than one match, but not with this data
- The Linq method
- ‘Mate’ is my term for the original country
-
if (m.Mate != c.Mate) { - The class is named ‘
ConsonymWordPair‘, but I added an extra field ‘Mate'after naming it - So it isn’t really a pair any more 😑- whoops!
- The if-statement,
if (m.Mate != c.Mate)ensures that I don’t accidentally match, for example, Briton against Britain
-
- Display the results!
txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n";- That code appends a new solution to the textbox called ‘
txtResults‘ - The
+=operator causes the new string to be appended to the existing one - We build a string to append using the
$""nomenclature - This allows us to mix variables with text in a more natural way
- Variables are recognized inside the
{}brackets; everything else is plain text - Note that
\n(look at the end of the line) is how we specify a newline
Method ‘BuildCountryNationalityLists’
private (List<ConsonymWordPair>, List<ConsonymWordPair>) BuildCountryNationalityLists() {
//1) Build the two empty lists which we will populate and return:
var countryLst = new List<ConsonymWordPair>();
var nationalityLst = new List<ConsonymWordPair>();
//2) NATIONALITY_FILE is defined at the class-level; it is the file name
using var sr = File.OpenText(NATIONALITY_FILE);
//3) Read until end-of-file detected
while (sr.Peek() != -1) {
//4 Read the line, convert to lower case, split on tab character
//The split operation means that 'twain' is an array
var twain = sr.ReadLine().ToLower().Split('\t');
if (twain != null && twain.Length == 2) {
//5) twain[0] is the country name; build a pair with the
//word and its consonants
var c1 = RemoveVowels(twain[0]);
var cwp1 = new ConsonymWordPair(twain[0], c1, twain[0]);
countryLst.Add(cwp1);
//6) Now do the same for the nationality, which is in twain[1]:
var c2 = RemoveVowels(twain[1]);
var cwp2 = new ConsonymWordPair(twain[1], c2, twain[0]);
nationalityLst.Add(cwp2);
}
}
return (countryLst, nationalityLst);
}Discussion – BuildCountryNationalityLists
The method reads the file and builds two lists. As above, the list numbers below correspond to numbered comments above. The string operators used are ToLower and Split. The three File IO operators are File.OpenText, StreamReader.Peek and StreamRead.ReadLine. By putting this code in a separate method, the main method is simplified and easier to read.
- Build the two empty lists which we will populate and return
- Each list contains an instance of my class ‘
ConsonymWordPair‘
- Each list contains an instance of my class ‘
- NATIONALITY_FILE is defined at the class-level; it is the file name
- The variable
sris a StreamReader that can read a line at a time - The ‘
using‘ keyword guarantees that the stream will be closed and disposed
- The variable
- Read until end-of-file detected
- The StreamReader has a
Peekmethod that returns -1 whenEOFis detected, that terminates mywhile-loop
- The StreamReader has a
- Read the line, convert to lower case, split on tab character. The split operation means that ‘twain’ is an array
- I’m doing 3 things in this line:
var twain = sr.ReadLine().ToLower().Split('\t');
ReadLineshould be obviousToLowerconverts to lower case, so that I won’t try comparing ‘Lbnn’ against ‘lbnn’, because those two strings are not equal!- Split does what it says → it finds the tab character (\t) and splits the line every time it finds it
- The result is an array with two elements:
- Element 0: the country name (everything to the left of the tab)
- Element 1: And the nationality (everything to the right of the tab
- I’m doing 3 things in this line:
- twain[0] is the country name; build a pair with the word and its consonants
- The code below invokes my method
RemoveVowels, passing twain[i] as the inputvar c1 = RemoveVowels(twain[0]);
- For example, if the line was ‘Albania Albanian’
- Then twain[0] is ‘albania’ (note the lowercase ‘a’)
- The output from invoking
RemoveVowelsis ‘lbn’
- The code below invokes my method
- Now do the same for the nationality, which is in twain[1]:
- Following the example above,
twain[1]will be ‘albanian’ - The output from invoking RemoveVowels is ‘lbnn’
- Following the example above,
RemoveVowels Method
This method is really simple, so I won’t bore you with any unnecessary explanation. Here’s the code!
private string RemoveVowels(string input) {
//StringBuilder is easy to use and a more memory-efficient way to build a string
var result = new StringBuilder();
//Declare and initialize the array of char
var vowels = new[] { 'a', 'e', 'i', 'o', 'u' };
//Examine each char in the input string
foreach (var c in input)
if (!vowels.Contains(c))
result.Append(c);
return result.ToString();
}Class ‘ConsonymWordPair’
internal class ConsonymWordPair {
//1) My three public properties, the most important part of the class
public string Consonym { get; set; }
public string Word { get; set; }
public string Mate { get; set; }
//2) Default constructor
public ConsonymWordPair() {
Consonym = Word = Mate = "";
}
//3) 3-parameter constructor
public ConsonymWordPair(string newWord, string newConsonym, string newMate) : this() {
Word = newWord;
Consonym = newConsonym;
Mate = newMate;
}
public override string ToString() {
var result = $"{Consonym} - {Word}";
return result;
}
}Discussion – ConsonymWordPair
- My three public properties, the most important part of the class
- The remainder of the class is practically fluff
- As mentioned before, “pair” is not quite accurate any more, but “tuple” is harder to understand
- Default constructor
- Ensures that the public properties are initialized
- 3-parameter constructor
- The constructor used by the caller. Note that it actually invokes the default constructor with the code “
: this()“ - A pattern I try to follow which ensures the code in the default constructor is only written once
- The constructor used by the caller. Note that it actually invokes the default constructor with the code “
One other thing, the ToString method is not invoked when I solve the puzzle – so why did I write it? The answer is that Visual Studio uses it to display the list contents during debug sessions. When I hover my mouse over the pertinent variable (a list), it displays the contents using my method. Note that I built the image above (showing how the two lists are matched against each other) using the Immediate Pane in a debug session. Again, Visual Studio utilized my ToString method to display the data in that pane for me. Kind of the opposite of “immediate pain” 😉.
Lessons Learned
🙎🏼I made one big booboo writing this code: I used .NET’s Except method instead of my current method RemoveVowels. It didn’t work and I was surprised 😒! Except doesn’t work the way I thought it does, and I’ve been using it for years. I sure hope I didn’t create any bugs in production because of this.
Here’s some sample bad code that illustrates how I attempted to use Except:
var vowels = new[] { 'a', 'e', 'i', 'o', 'u' };
var twain = new[] {"albania", "albanian"};
var c1 = twain[0].Except(vowels).Aggregate("", (p,c) => p + c);
Console.WriteLine(c1);
var c2 = twain[1].Except(vowels).Aggregate("", (p,c) => p + c);
Console.WriteLine(c2);Can you guess what the output is for c2? I’ll keep you in suspense while I explain my code.
- Note that
twain[0]contains the string “albania” - When I invoke
Excepton it, passingvowelsas the input parameter, I get anIEnumerable<char>as the output (something like a list) that looks like the following:- ‘l’
- ‘b’
- ‘n’
- In other words, I get everything except the vowels. Just what we all expected.
- The code fragment
.Aggregate("", (p,c) => p + c)serves to create a string from the IEnumerable; basically it iterates the char elements and uses the+operator to concatenate them into a string
OK, now that I’ve explained how c1 is created, what do you think the value of c2 is? The code is the same for both, except the input for creating c2 is “albanian”. To my surprise, c1 is “lbn”. I expected “lbnn”, i.e. two n’s. .NET dropped one of my n’s.
What happened? Except works on IEnumerables, and I gave it a string, which .NET treated like a list of char. So far, so good. Reading the documentation, it doesn’t say anything about applying the Distinct operator, so all I can guess is that, under set operations, no one cares about preserving duplicates. Yes, I studied Set Theory in college, and I don’t remember anything like that, but it does seem somewhat consistent with how we did things then. So I don’t really know why it behaves that way, but now you know what to expect!
Efficiency Analysis
OK, my data file is only 156 lines long, and the code runs in just 7 milliseconds (according to .NET when running in debug mode, see below).
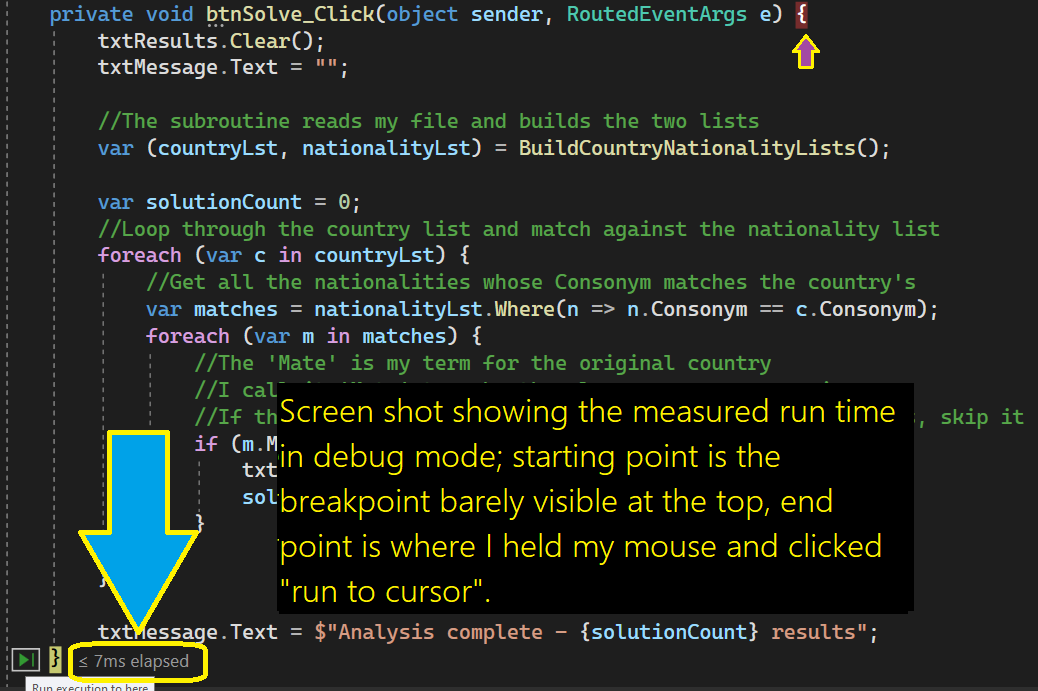
So, I must admit that we don’t care much about whether this code runs in 7 milliseconds, or 500 milliseconds – you’ve already burned thousands of milliseconds reading this😊 But it’s always good to understand the performance of your code, for one reason, it’s interesting!
The algorithm I used runs in O(n2), meaning that it first runs through the main list (the countries) and, for each pass through that list, makes another pass through the other list (nationalities), searching for a match. In this type of analysis, we ignore the fact that the 2nd search/array pass completes in an average of just half the array size; instead we focus on limiting behavior.
For our calculations, each pass in the first list means a pass through the second, so if the first array has length n, then the algorithm runs in n × n passes, or n2.
How to Improve Performance
I could have improved my performance by storing nationalities in a dictionary instead of a list. Note that .NET dictionaries use hashing instead of what I used, namely, a linear search. Hashing is much more efficient because we can determine whether some nationality exists in our dictionary in just O(1) run time, basically one calculation instead of examining the whole list. O(1) is generally the fastest possible run time.
By using a dictionary, my algorithm could have had a run time of O(n). Maybe that would shave a whole millisecond off my run time! I leave it as an exercise for the reader to make those sweet changes. Realistically, the bottleneck for this app is the file I/O, which typically runs 1000 times slower than memory calculations, though that won’t be anywhere near as bad if you have an SSD drive.
Improve Even More?
If we want to get ridiculous and shave off another millisecond, we can parallelize the main loop. That would also require that we use some sort of locking to make sure that different threads don’t update the display simultaneously and interfere with each other; either use of the lock keyword or else Dispatcher.Invoke.
The main loop would look like the following:
Parallel.ForEach(countryLst, (c) => {
var matches = nationalityLst.Where(n => n.Consonym == c.Consonym);
foreach (var m in matches) {
if (m.Mate != c.Mate) {
Dispatcher.Invoke(() => txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n");
solutionCount++;
}
}
});Since my PC has 20 cores, the code above would potentially run 20 times faster than my current main loop. Who knows what amazing things I could do with the time I saved using that technique! Seriously though, parallelization is a powerful tool for tackling certain difficult problems.
Download the Code
Here’s a copy of my code. If you choose to download it, remember to modify the file path (at the top of the code) to reference a location on your computer, not on mine. Here’s a copy of my nationalities file. You will need a free Dropbox account to download.
NPR Puzzle for November 20, 2022
Science Branch with Two Embedded Anagrams
Last week’s challenge came from Henri Picciotto, of Berkeley, Calif. He coedits the weekly “Out of Left Field” cryptic crossword. Name a branch of scientific study. Drop the last letter. Then rearrange the remaining letters to name two subjects of that study. What branch of science is it?
Link to the challenge
General Approach
I elected to use WPF for this one, for one reason, I was in a bit of a hurry, and I’m faster in WPF. Also, WPF is well suited for file handling, unlike web-based solutions, and the code needs to load a file containing English words, as well as a file containing fields of science. Finally, the code is a bit CPU intensive; Python would run slower, and building a nice UI in Python is harder, at least for me!
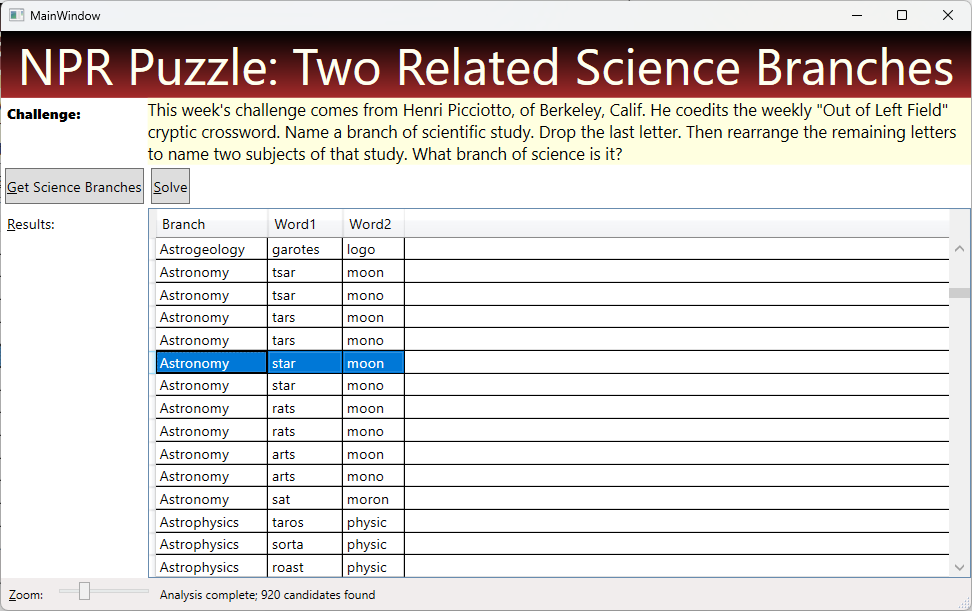
Here’s how my UI looks after clicking the ‘Solve’ button:
Techniques Used

Synopsis
We can get a list of 716 branches of study from Wikipedia. Using HtmlAgilityPack, we can extract the names from the raw HTML on that page. That is the list we will attempt to manipulate, so we need a list of English words, many of which are available on the web (including this one).
Using those two sources, proceed by first splitting each branch into two parts (after stripping the last letter). Note that each branch can be split at several points, so we use a loop to try every valid split point.
Having split the original, we anagram the two sub-words. To do so, we take advantage of a simple fact relating to anagrams:
Two words are anagrams if their sorted letters are the same

To capitalize on this principle, we build a dictionary, using every word in English, whose keys are the sorted letters, having an associated value composed of the list of words that share those sorted letters. That way, we can easily and efficiently find the anagrams of any word. Here’s what a sample dictionary entry looks like:
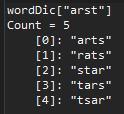
Interpretation: the image above is a screen shot from Visual Studio’s Immediate Pane. It shows the value associated with one particular dictionary key, “arst”, which is a list of 5 words, all of which are anagrams of each other. Just to make it ultra clear, here is the dictionary entry for “mnoo”:
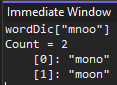
The dictionary will contain 75,818 such entries.
Using the dictionary, we can tell if a candidate has any anagrams by checking if its sorted letters exist in the key. If the key exists, we can get all the anagrams for the candidate by examining the value associated with that key. Remember, each entry in a dictionary is a key/value pair.
So, to recapitulate, we will build a dictionary from all English words, each entry has the sorted letters as the key, and the list of anagrams as the value. We loop through the science branches, splitting each into two candidates. If both candidates are in the dictionary (after sorting their letters), then we have a candidate solution.
Here’s the Code!
To save space, I will omit the part of my code which downloads the list of science branches. But have no fear, you can download all my code and examine it to satisfy your curiosity, using the link at the bottom.
Note that the code below is just an excerpt, representing the most important code. At the point where the excerpt begins, we already have the following variables:
branchList– a list of all 716 branches of science, a simple list of type stringwordDic– a dictionary constructed as described above, using sorted letters as the key to each entry
Obviously, if you want to see the code I haven’t discussed below, you can just download my entire project (link below); I believe the embedded comments in that code should satisfy your curiosity.
Note that each numbered comment in the listing below has a corresponding explanation after the code listing.
//Every candidate solution will go into this collection, which is bound to the display:
var answers = new ObservableCollection<Answer>();
grdResults.ItemsSource = answers;
//The syntax below allows the screen to remain responsive while the algorithm runs
await Task.Run(() => {
int count = 0;
foreach (var candidate in branchList) {
//1) remove the last letter
var trimmed = candidate.ToLower()[..^1];
//2) This inner loop tries splits the science branch at all possible points
//forming two parts, br1 and br2:
for (var i = 1; i < trimmed.Length - 1; i++) {
//3) Take the first part of the candidate and sort its letters
var br1 = trimmed[..i].OrderBy(c => c).Aggregate("", (p, c) => p + c);
//4) If the sorted letters are in the dictionary, work with
//the 2nd part of the branch:
if (wordDic.ContainsKey(br1)) {
//5) Grab the 2nd part of the branch and sort its letters
var br2 = trimmed[(i)..].OrderBy(c => c).Aggregate("", (p, c) => p + c);
//6) If br2 is in the dictionary, we have a potential solution:
if (wordDic.ContainsKey(br2)) {
//7) Each entry (the science branch name part) has a list associated with it
//(the entry's value); display all combinations from those 2 lists
foreach (var word1 in wordDic[br1]) {
foreach (var word2 in wordDic[br2]) {
var addmMe = new Answer { Branch = candidate, Word1 = word1, Word2 = word2 };
answers.Add(addmMe);
}
}
}
}
}
//Update the progress bar
var pct = (int)(100 * count++ / (float)branchList.Count);
Dispatcher.Invoke(() => prg.Value = pct);
}
});
Numbered Comment Explanation
var trimmed = candidate.ToLower()[..^1];- Each branch of science in the list is mixed case, so use “
ToLower” to match our dictionary - [..^1] means take a substring starting at the beginning, all the way to 1 before the end
- Each branch of science in the list is mixed case, so use “
for (var i = 1; i < trimmed.Length - 1; i++) {- The variable
icontrols the split point in the candidate; the first eligible position is 1, because we don’t want any zero-length strings. Similarly, the last split point is 1 before the end - For example, the word “astronomy” would be split as 7 different times, once for each pass through the loop, with the split points shown below, as well as the pertinent variables:
- i = 1, a – stronom, br1 = a, br2 = oomnrst
- i = 2, as – tronom, br1 = as, br2 = oomnrt
- i = 3, ast – ronom, br1 = ast, br2 = oomnr
- i = 4, astr – onom, br1 = arst, br2 = oomn
- i = 5, astro – nom, br1 = aorst, br2 = omn
- i = 6, astron – om, br1 = anorst, br2 = mo
- i = 7, astrono – m, br1 = anoorst, br2 = m
- The variable
var br1 = trimmed[..i].OrderBy(c => c).Aggregate("", (p, c) => p + c);- Take the substring ending at position i. Then sort the letters (“
OrderBy“). Note that the result isIEnumerable<char>– basically a list of characters. Now take the result of that operation andAggregateit so we get a string instead of a list of char. - Interpret the aggregation as follows:
- “” (Empty quotes) This is the seed, we start with an empty string and append everything to it
(p,c) =>this introduces the two parameters used in the operation, they represent the previous (p) value and the current valuec. Previous means the string we have built so farp + cWe simply append the current character to the previous value
- The upshot is this code converts a list of char into a string
- Take the substring ending at position i. Then sort the letters (“
if (wordDic.ContainsKey(br1)) {- Test if the sorted letters (
br1) have an anagram by asking the dictionary if it has a corresponding key. This is like asking the dictionary if ‘arst’ has an entry in the key. Remember, ‘arst’ is an anagram of ‘star’.
- Test if the sorted letters (
var br2 = trimmed[(i)..].OrderBy(c => c).Aggregate("", (p, c) => p + c);- Now take the second part of the science branch and do the same thing
- The only thing that is different is how we take the last part of the original, namely,
trimmed[(i)..]
- This means “take a substring starting at position i, up to the very end
if (wordDic.ContainsKey(br2))- Like before, check if the sorted letters “br2” have any anagrams,
- If so, we have a potential solution!
Remember, the list answers is bound to the display grid, so merely adding it causes it to be displayed. It is then up a human to decide whether the displayed anagrams are actually studied as part of the science branch.
Get the Code to Solve the Puzzle
You can download my complete code, including my list of 716 branches of science, here. Note that you will need a DropBox account to use that link, but that is free. Also, you will need a list of English words; you can get one here. You will need to modify your version of the code to reflect the path where you save this file.
NPR Sunday Puzzle, World Capital to Farm Animal
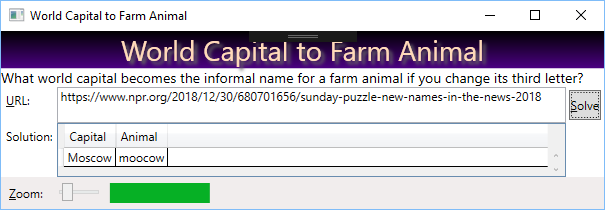
Synopsis
What makes this puzzle challenging is the lack of a good list of “informal” farm animals. There are lists of farm animal names, they don’t work. Also, the solution, “moocow”, requires a really big dictionary, though my PC has plenty of power to solve the puzzle in a few seconds. However, it is nice to have a progress bar, so my code does so.
Approach
I don’t have a list of informal farm animal names; maybe I can find an ordinary word which contains a farm animal inside it. Check every capital which can be morphed into other words, and then check to see if any of those words contain a farm animal name.
Specifics
- Build a dictionary of every word, the dictionary key will be the capital with the 3rd letter chopped out, each entry’s payload (value) will be the original word(s)
- For example, “moscow” → [“mocow”, “moscow”], i.e. the key is the chopped word and the value is the original word
- Sometimes the same dictionary key corresponds to multiple words, for example, Accra, acara and Acura all turn into ‘acra’ when you chop-out the 3rd letter
- Besides building the dictionary, build a list of every common farm animal, this will be pretty short
- Next, process the file containing capital names.
- For every capital, chop-out the 3rd letter and look-up the corresponding words in the dictionary
- At this point, we need to check every farm animal and see if any of them are a substring of any of the words the capital can morph into
- If so, display it as part of the solution
Additional Techniques
I used the IProgress construct, along with asynchronous invocation of my solving method to allow the UI to remain responsive, and update my progress bar, while the code runs.
The Code
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using System.Windows;
using System.Windows.Input;
using System.IO;
using System.Collections.ObjectModel;
namespace Dec30_2018 {
/// <summary>
/// Holds the controls and code to solve the puzzle
/// </summary>
public partial class MainWindow : Window {
/// <summary>Bound to the solution grid</summary>
private ObservableCollection<Tuple<string, string>> _SolutionList;
public MainWindow() {
InitializeComponent();
}
/// <summary>
/// Fires when user clicks the solve button
/// </summary>
/// <param name="sender">The buton</param>
/// <param name="e">Event args</param>
private async void BtnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
btnSolve.IsEnabled = false;
_SolutionList = new ObservableCollection<Tuple<string, string>>();
grdSolution.ItemsSource = _SolutionList;
//This code fires when the SolvePuzzle method reports progress:
var progress = new Progress<Tuple<int, string, string>>(args => {
prg.Value = args.Item1;
if (!string.IsNullOrWhiteSpace(args.Item2))
_SolutionList.Add(Tuple.Create(args.Item2, args.Item3));
});
//Run the solution on a different thread so the UI will be interactive
await Task.Run(() => SolvePuzzle(progress));
btnSolve.IsEnabled = true;
Mouse.OverrideCursor = null;
}
/// <summary>
/// Solves the puzzle using a big word list, a list of captials, and a list of farm animals
/// </summary>
/// <param name="rptProg">Basically a method to invoke when we want to report progress</param>
private void SolvePuzzle(IProgress<Tuple<int, string, string>> rptProg) {
string wordFile = @"C:\Users\User\Documents\Puzzles\Data\NPLCombinedWordList.txt";
//Key to the dictionary will be the word with its 3rd letter cut-out, the payload will
//be a comma-separated list of words that correspond to it.
//For example, for Moscow, the key will be 'mocow' and the value will be 'Moscow'
//For Accra, the key will be 'acra' and the value will be 'acara,accra, acura'
var wordDic = new Dictionary<string, string>();
var fSize = (new FileInfo(wordFile)).Length;
int processedBytes = 0;
int lastPct = 0;
using (StreamReader sr = File.OpenText(wordFile)) {
while (sr.Peek() != -1) {
string aWord = sr.ReadLine();
if (aWord.Length > 3) {
string key = (aWord.Substring(0, 2) + aWord.Substring(3)).ToLower();
if (wordDic.TryGetValue(key, out string fullWords))
wordDic[key] += "," + aWord;
else
wordDic.Add(key, aWord);
}
//Calculate the percentage of the file processd and report progress if it increase by 1 point
processedBytes += aWord.Length + 2;
var pct = (int)(100 * ((double)processedBytes / fSize));
if (pct != lastPct) {
rptProg.Report(Tuple.Create(pct, "", ""));
lastPct = pct;
}
}
}
//Build a list of farm animals:
var farmAnimalList = new List<string>();
string farmAnimalFile = @"C:\Users\User\Documents\Puzzles\Data\FarmAnimals.txt";
using (StreamReader sr = File.OpenText(farmAnimalFile)) {
while (sr.Peek() != -1) {
farmAnimalList.Add(sr.ReadLine());
}
}
//Process the list of capitals and, for each entry, check to see if it forms a solution
string capitalFile = @"C:\Users\User\Documents\Puzzles\Data\WorldCapitals.txt";
using (StreamReader sr = File.OpenText(capitalFile)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//A typical line looks like 'Moscow~Russia' or 'London~Great Britian'
int p = aLine.IndexOf('~');
string capital = aLine.Substring(0, p);
if (capital.Length > 3) {
//Chop-out the 3rd letter and get the words that correspond to it in the word dictionary:
string key = (capital.Substring(0, 2) + capital.Substring(3)).ToLower();
if (wordDic.TryGetValue(key, out string morphedWords)) {
//Build an array for all the words which share the same key:
var splitWords = morphedWords.Split(new[] { ',' }, StringSplitOptions.RemoveEmptyEntries);
//Perform a Cartesian product so we get every combination from the farm animal list and the words
//corresponding to the key:
var joinList = splitWords.Join(farmAnimalList,
s => "", f => "",
(s, f) => new { Word = s, Animal = f });
//Examine every combo in the cartesian product:
foreach (var candidate in joinList) {
//If the animal is a substring of the word, then we have a solution,
//such as "moocow".IndexOf("cow") = 3, because cow is a substring of moocow at position 3
if (candidate.Word.IndexOf(candidate.Animal) >= 0
&& capital.ToLower() != candidate.Word) {
//Report progress with the solution pair, which will disply it in the grid:
rptProg.Report(Tuple.Create(100, capital, candidate.Word));
}
}
}
}
}
}
}
}
}
Get the Code
Download the code here, from my dropbox account. Note: they will ask you to create a free account to perform the download.
Puzzle: US City With Only 3 Letters
The Sunday Puzzle Challenge:
The name of what well-known U.S. city, in 10 letters, contains only three different letters of the alphabet? Puzzle URL
Synopsis
Fun and Simple! You can get the census place name file from the US Census Bureau.

Techniques Used
Code to Solve the Puzzle
private void btnSolve_Click(object sender, RoutedEventArgs e) {
string cityFile =
@"C:\Users\User\Documents\Puzzles\Data\AmericanPlaces2k.txt";
using(StreamReader sr = File.OpenText(cityFile)) {
while(sr.Peek() != -1) {
string aLine = sr.ReadLine();
//File is fixed-width, city starts in column 9
string cityName = aLine.Substring(9, 30)
.TrimEnd();
//Place names end with town/city/CDP; remove it now:
if (cityName.EndsWith(" town"))
cityName = cityName.Substring(0, cityName.Length - 5);
else if (cityName.EndsWith(" CDP"))
cityName = cityName.Substring(0, cityName.Length - 4);
else if (cityName.EndsWith(" city"))
cityName = cityName.Substring(0, cityName.Length - 5);
//Remove spaces and other non-letters:
var letters = cityName.ToLower()
.Where(c => char.IsLetter(c));
//Check if the city has 10 letters and a distinct count of 3
if (letters.Count() == 10) {
int letterCount = letters.Distinct().Count();
if (letterCount == 3) {
txtSolution.Text += $"{cityName}\n";
}
}
}
}
}Any Tricky Parts?
When you use Linq on a string variable, it treats your variable as an array of char. That is how I can, for example, execute this line of code:
var letters = cityName.ToLower().Where(c => char.IsLetter(c));
In the code above, ‘c‘, refers to a char in the city name. Note that the result above, ‘letters‘, has data type ‘IEnumerble<char>’. I.e., everything is a char when you use Linq on a string.
Download the Code
You can download the code from my DropBox account. To do so, you will need to create a free account. If you run the downloaded code, you will need to adjust the path to the city name file. I included that file in the download.
Sunday Puzzle for Oct 1st, 2017
 I sure hope I found the solution Will was looking for! I’ve never heard of ‘flan’ until now. I know Will creates crossword puzzles for a living, so maybe flan is a common word to him. Or, maybe, as a New Yorker, he eats fancy desserts all the time.
I sure hope I found the solution Will was looking for! I’ve never heard of ‘flan’ until now. I know Will creates crossword puzzles for a living, so maybe flan is a common word to him. Or, maybe, as a New Yorker, he eats fancy desserts all the time.
According to Google, the dish pictured here is a ‘flan’. Sorry, it looks like cheese cake to me! I guess I’m not a gourmand.
Struggle Notes
If you look at the buttons on my screen shot, you might guess I tried pretty hard to get alternative word lists. (I wasn’t too happy with ‘flan’.)
- The button ‘Try All Words” uses a huge dictionary of English words (forget mere food words, try anything!), so if the solution used common words, like ‘corn’, that would have solved it
- The button “Get Name Brand Foods” downloads foods that might not be in my dictionary of English words.
- Since neither of those two methods found a different solution, I’m sticking with flan/gumbo.
Downloading Food Names

Note my other button, ”Get Food Names”.
- This button goes to Wikipedia’s page https://en.wikipedia.org/wiki/Lists_of_foods, which is a list of links…
- Follows each link, and grabs the food names from that page
- The result is 347 files of various food names, such as ‘List_of_pies,_tarts_and_flans’.
- If you’re a web guru, you might guess that takes a while to run. And you’d be correct; it took about 15 minutes to download them all.
Techniques Used
- String manipulation
- BinarySearch for lists
- Linq Aggregate
- Linq Select
- Removing diacritics (accents) from Unicode text
How To Shift Letters Using Linq
string shifted = aWord.Select(c => c == 'z' ? 'a' : (char)(c + 1))
.Aggregate("", (p, c) => p + c);
This code shifts each letter by one, as Will describes it in the challenge. For example, ‘flan’ becomes ‘gmbo’.
Notes:
- My variable ‘aWord’ might contain, for example, the word ‘flan’
- Linq Select treats aWord as a list of letters (i.e. list of char data type)
- The code examines each letter, c
- I use the ternary operator on each letter. ‘Ternary Operator” is a short-hand if-statement
- It takes the form condition ? first_expression : second_expression;
- If the letter c is ‘z’ (my condition)
- Return an ‘a’ (my first expression)
- Otherwise, add one to it and convert it back to char (2nd expression)
- The aggregate operator converts the list of char back into a string
- If ‘aWord’ contained “flan”, shifted would be assigned “gmbo”
How to Solve the Puzzle
The method below uses the code from above to shift a 4-letter word. My method needs a list of 4-letter foods and of 5-letter foods, passed as parameters
private void SearchListsForSolution(List<string> fiveLetterFoodList,
List<string> fourLetterFoodList) {
List<string> solutionList = new List<string>();
foreach (string aWord in fourLetterFoodList) {
if (!solutionList.Contains(aWord)) {
string shifted = aWord.Select(c => c == 'z' ? 'a' : (char)(c + 1))
.Aggregate("", (p, c) => p + c);
//Loop injects 'u' at 3 different positions to build candidate
//So we try 'gumbo', 'gmubo' and 'gmbuo'
for (int i = 1; i <= 3; i++) {
string candidate = shifted.Substring(0, i)
+ "u" + shifted.Substring(i);
//fiveLetterFoodList is a sorted list of foods
int p = fiveLetterFoodList.BinarySearch(candidate);
//if p is greater than zero, we found candidate in the list
if (p >= 0) {
//Add the 4-letter word, shifted version
//and 5-letter word to textbox
tbSolution.Text +=
$"{aWord } → {shifted} + u → {fiveLetterFoodList[p]}\n";
solutionList.Add(aWord);
}
}
}
}
}Notes
- There are only 3 places to inject a u into a 4-letter word
- My code tries all 3 places and checks to see if the result is a word
- By using Binary Search against the 5-letter word list
- The BinarySearch method returns an index > 0 if it finds the candidate
- So when that happens, I update my TextBox ‘tbSolution’ to include what I just found
- The list ‘SolutionList’ helps me avoid entering the same solution twice; I need it because ‘flan’ was present in multiple files
Removing Diacritics
Just in case, I tried fixing words like ‘Ragú‘, converting it to ‘Ragu‘ by removing the accent over the letter u. (It didn’t help.) It was pretty easy; I just copied the code from here: “Stripping is an Interesting Job…”
That code looked like this:
static string RemoveDiacritics(string text)
{
var normalizedString = text.Normalize(NormalizationForm.FormD);
var stringBuilder = new StringBuilder();
foreach (var c in normalizedString)
{
var unicodeCategory = CharUnicodeInfo.GetUnicodeCategory(c);
if (unicodeCategory != UnicodeCategory.NonSpacingMark)
{
stringBuilder.Append(c);
}
}
return stringBuilder.ToString().Normalize(NormalizationForm.FormC);
}Get the Code!
As usual, you can download my code from my DropBox account here. As usual, they will only let you download if you create a free account with them. Note: my zip file contains all the food lists, located in my bin folder.
Finding An Anagram with Linq and Regex
Once again, thanks to Will Shortz and NPR for supplying a challenging puzzle so we can play with some fun .NET features!

This time, the puzzle was easy; the challenge was getting a list of song titles. I experienced the following issues getting a song list:
- Wikipedia (normally the primo place for lists) didn’t have one.
- The first decent alternate site
- Spread its list over 85 pages
- Used an ‘anti-robot’ policy that blocked my IP if I tried to access too many pages too fast. Argh!
- Fortunately, I was able to find GoldStandardSongList.com, a nice site with 5,000 titles all on one page☺
Code Techniques Used
- Linq Where operator, Restriction Operator (“Select”), Ordering Operators
- Linq Aggregate Operator – you can use it on strings!
- Regular expressions,
- Including Negated Character Classes – a powerful way to match until some character
- WebClient to read from a website containing a song list
The Secret Trick to Solving Anagrams
 The first time you try to solve an anagram, you might try some inefficient method, like building every letter-combination of your candidate. That would be super-slow, because there are a lot of combinations for a 15 letter song title. Listing all combinations is an O(n!) algorithm. (Check-out Wikipedia Big-O Notation if you never took a class in algorithm analysis.)
The first time you try to solve an anagram, you might try some inefficient method, like building every letter-combination of your candidate. That would be super-slow, because there are a lot of combinations for a 15 letter song title. Listing all combinations is an O(n!) algorithm. (Check-out Wikipedia Big-O Notation if you never took a class in algorithm analysis.)
……
Faster Method: Sort Your Candidate’s Letters
 Here’s a better way: sort the letters for the target and candidate, then compare the result. For example:
Here’s a better way: sort the letters for the target and candidate, then compare the result. For example:
- ‘COOL HIT FARE IN LA’ → ‘aacefhiillnoort’
- ‘HOTEL CALIFORNIA’ → ‘aacefhiillnoort’
Obviously, because the the sorted strings are equal, the two original strings must be anagrams. This is much faster, because you can sort a string in O(n∙ ln) time.
Compare n-Factorial Vs. n ∙Ln(n)
For comparison,
- 15! = 1,307,674,368,000 – n factorial
- 15∙ln(15) = 17 – n ln n
Hint: if you don’t like staring at an hourglass, use my algorithm! Would you rather run 17 operations, or 1.3 billion?
 For fun, challenge your bone-headed co-worker to a race and laugh while he pounds his screen in frustration!
For fun, challenge your bone-headed co-worker to a race and laugh while he pounds his screen in frustration!
Use Linq to Clean-Up your Song Title and Sort Letters: Easy!
Here’s the method I wrote that takes a song title as input, cleans it up, and sorts the letters:
private string CleanAndSortLetters(string input) {
string result = input.Where(c => char.IsLetter(c))
.Select(c => char.ToLower(c))
.OrderBy(c => c)
.Aggregate("", (p, c) => p + c);
return result;
}Highlights
- char.IsLetter – Should be obvious! It removes spaces, quote marks, parenthesis, etc.
- OrderBy – Sorts the letters in the string. Note that Linq will treat your string as an IEnumerable. Basically a list of char’s.
- Aggregate – combines the char list back into a string
Use Regular Expressions to Extract Song Titles from a Web Site
The challenge is to extract just the song title from all the HTML markup.

Here’s the Some of the Same Table in HTML Markup

Regular Expressions Find Your Pattern!
 Regular expressions are a powerful means to match patterns, but kinda hard to learn. They’re worth the effort for a task like this, because doing it differently would take forever and be just as complicated.
Regular expressions are a powerful means to match patterns, but kinda hard to learn. They’re worth the effort for a task like this, because doing it differently would take forever and be just as complicated.
Here’s my Regular Expression in action – it looks crazy, but I’ll explain it below:
//Build a pattern to match the song titles:
string pattern = "class=\"table1column2\"[^>]+><p>" +
".*?<span[^>]+>([^<]+)</span>";
//Use the pattern to build a regular expression
Regex re = new Regex(pattern,
RegexOptions.Compiled | RegexOptions.IgnoreCase
| RegexOptions.Singleline);
//Find all the matches in the string 'pageText':
Match m = re.Match(pageText);Quick note: the RegexOptions “Compiled” and “IgnoreCase” should be obvious. But “SingleLine” is counter-intuitive: you should use it when you try to match text containing linebreaks.
Also, I have some other code to loop through the matches, very easy but shown below, and also to extract the capture group and use it, again shown below.
Explanation of the Regex Pattern
The Regex packs a lot of meaning into a small space. Here’s a detailed explanation of every section. As you can see, it takes longer to explain it than it does to just run it. Skip it unless you have a super attention span!
| Regex Fragment | Explanation | Match | Comment |
|---|---|---|---|
| class=”table1column2″ | Match the exact text | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California</span> |
|
| [^>]+ | Any character that is not >, one or more repetitions. | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California</span> |
The so-called “negated character class” is a great way to skip over text until it hits a special character you know is always present, like the > |
| > | Literal match | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California</span> |
|
| .*? | Any character, as few as possible (“lazy star”) | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California</span> |
I would prefer to use a negated character class, but there is a line-break in the text I wish to skip over. Lazy star grabs matches until we hit the expression below. |
| <span | Literal match | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California</span> |
This terminates the lazy star match above |
| [^>]+ | Any character that is not >, one or more repetitions | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California</span> |
Another negated character class – super helpful! |
| > | Another literal match | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California</span> |
|
| ([^<]+) | Finally! My Capture Group; grab everything until we hit a < | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California</span> |
Basically another negated character class, wrapped in parenthesis |
| </span> | Literal match | <td class=”table1column2″ width=”30%” style=”padding-top: 0in; padding-bottom: 0in” valign=”top”><p> <span style=”font-weight: bold; font-family:Arial, sans-serif”>Hotel California<span> |
Here’s the Code to Solve the Puzzle
As you can see, the actual code is quite short. Again, explaining it is harder than just doing it!
private const string SONG_URL =
@"https://www.goldstandardsonglist.com/Pages_Sort_2a/Sort_2a.htm";
private void btnSolve_Click(object sender, RoutedEventArgs e) {
string anagramThis = "COOL HIT FARE IN LA";
Mouse.OverrideCursor = Cursors.Wait;
string matchThis = CleanAndSortLetters(anagramThis);
string pageText;
//Open the song URL in a web client and read all the text
using (WebClient wc = new WebClient()) {
using (StreamReader sr = new StreamReader(wc.OpenRead(SONG_URL))) {
pageText = sr.ReadToEnd();
}
}
string pattern = "class=\"table1column2\"[^>]+" +
"><p>.*?<span[^>]+>([^<]+)</span>";
Regex re = new Regex(pattern,
RegexOptions.Compiled | RegexOptions.IgnoreCase);
Match m = re.Match(pageText);
//Examine every match
while (m.Success) {
//Grab the capture group and remove line breaks etc.
string songName = m.Groups[1].Value
.Replace("\r", "")
.Replace("\n", " ");
string candidate = CleanAndSortLetters(songName);
//The key to solving the puzzle:
if (candidate == matchThis)
txtAnswwer.Text += songName + "\n";
m = m.NextMatch();
}
Mouse.OverrideCursor = null;
}Code Comments
I left-out the method ‘CleanAndSortLetters‘ because I already listed it above.
If you download my code and run it, you can set a breakpoint and see that it takes several seconds to download the song list. But, after that slow operation, the rest of the code runs in a few milliseconds!
Summary
 Solving the puzzle is easy with Linq; you just use the Linq operators to sort the letters, remove spaces etc, and convert to lower case. After that, you compare it to the target; if they are the same, you’ve found a winner!
Solving the puzzle is easy with Linq; you just use the Linq operators to sort the letters, remove spaces etc, and convert to lower case. After that, you compare it to the target; if they are the same, you’ve found a winner!
The hard part is getting your list of song titles. Get the raw HTML with WebClient.Open, then use Regular Expressions to extract patterns from your HTML markup. Most of my Regex pattern consists of literal matches, or else negated character classes. As you remember, negated character classes allow you to match until you hit a designated character, such as < or >.
Download the Code
You can download my code here from my Dropbox account; note that they will force you to create a free account before proceeding with the download.
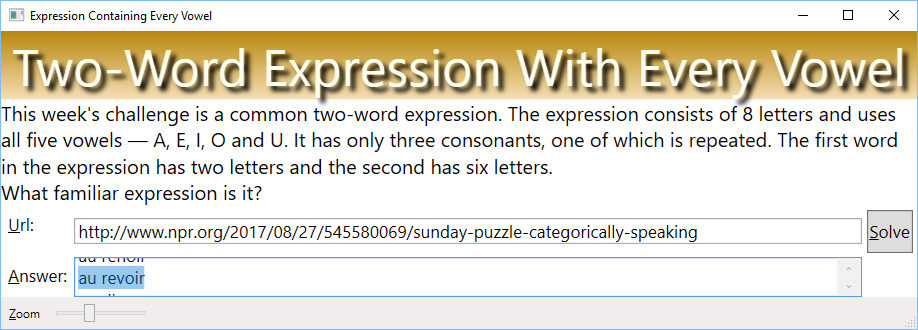
Fun With Linq – Solving the Sunday Puzzle
The Challenge
This week’s challenge is a common two-word expression. The expression consists of 8 letters and uses all five vowels — A, E, I, O and U.
It has only three consonants, one of which is repeated. The first word in the expression has two letters and the second has six letters.
Techniques to Solve
- File IO
- Complex dictionaries
- Linq operations, including
- Where
- Aggregate
- Except
- GroupBy
Comments on the Puzzle
That was kind of a tough puzzle! I found some phrase lists on the internet, but they weren’t very big and none of them contained the solution. Out of frustration, I elected to search word lists to construct word pairs that match Will’s description. Even that didn’t work until I get a really big word list that had some French words.
Finally, after plugging in my biggest word list, and manually sifting through 4,403 candidates, I found the answer. While looking at the candidates starting with “au”, something in the back of my mind pulled-up the answer “au revoir” before I actually saw it on screen.
Some Near Misses
I got a kick out of these, which met the rules, but probably aren’t “common expressions”:
- Go, Aussie!
- No Auntie!
- Oi, abuses
- Up roarie
 Overview of The Algorithm
Overview of The Algorithm
- Open the word list, read every word
- Length == 2 ? add to a list named “twoLetterWords”
- Length == 6 ? Store in a dictionary
- The dictionary uses the word’s vowels as a key,
- Such as key = “eio” for the word “revoir”
- For each key, keep a list of all the 6-letter words that contain those vowels
- So the data type for my dictionary is “Dictionary<string, List> sixLetterWordDic”
- So, under the dictionary key “eio”, I store a list of 1,227 words that use those three vowels, including “revoir”
- The dictionary uses the word’s vowels as a key,
- After building the dictionary and the 2-letter word list
- Iterate all the two-letter words
- Compute the vowels not used in the 2-letter word
- Use them as a key to the dictionary
- Loop through the word list stored under key composed of the remaining vowels
- Apply Will’s criteria “3 consonants, one of which is repeated”
- By using the GroupBy operator
Here’s the Code
private void btnSolveFromWordList_Click(object sender, RoutedEventArgs e) {
List<string> twoLetterWords = new List<string>();
//For speed, we look-up words using their vowels as a key
//For example,
// sixLetterWordDic["eio"] = { "belion", "beloid", .... "revoir" }
//To wit, the key "eio" represents all the vowels EXCEPT "au"
// The value is a list of words containing those vowels, 1,227 total, including "revoir"
Dictionary<string, List<string>> sixLetterWordDic = new Dictionary<string, List<string>>();
List<string> vowels = new List<string> { "a", "e", "i", "o", "u" };
//Open the word file and read every line, building the word list and the dictionary
using (StreamReader sr = new StreamReader(File.OpenRead(WORD_File))) {
while (sr.Peek() != -1) {
string aWord = sr.ReadLine().ToLower();
if (aWord.Length == 6) {
//Get all the vowels in the word and concatenate into a string
string vowelKey = vowels.Where(v => aWord.Contains(v))
.Aggregate("", (p, c) => p + c);
if (vowelKey.Length > 0) {
//Add to the dictionary using the vowels as a key; hopefully it does not need sorting
if (sixLetterWordDic.ContainsKey(vowelKey))
sixLetterWordDic[vowelKey].Add(aWord);
else
sixLetterWordDic.Add(vowelKey, new List<string> { aWord });
}
} else if (aWord.Length == 2 && !twoLetterWords.Contains(aWord))
twoLetterWords.Add(aWord);
}
}
//Now that we have the word list and dictionary, loop through seeking
//a solution:
int word2Count = 0;
foreach (string aWord in twoLetterWords) {
//Get just the vowels; for examle, if the word is "of", then foundVowels will be { "o }
List<string> foundVowels = vowels.Where(v => aWord.Contains(v)).ToList();
if (foundVowels.Count > 0) {
//get all the vowels NOT used in foundVowels
string remaining = vowels.Except(foundVowels)
.Aggregate("", (p, c) => p + c);
if (sixLetterWordDic.ContainsKey(remaining)) {
foreach (string partner in sixLetterWordDic[remaining]) {
//We know there should be two distinct consonants, and one of them is repeated
//so use GroupBy on the letters.
var consonantGroups = (aWord + partner)
.Where(l => "aeiou".IndexOf(l) < 0)
.GroupBy(l => l);
if (consonantGroups.Count() == 2 &&
(consonantGroups.First().Count() == 2 || consonantGroups.Last().Count() == 2)) {
txtAnswer.Text += aWord + " " + partner + "\n";
matchCount++;
}
}
}
}
}
}
What’s Up with the Dictionary?
My word list is huge – more than 775,000 entries. That results in 54,596 six letter words and 646 2-letter words. I can’t wait around while my code checks every 2-letter word against that huge list of 6-letter words. So I used a dictionary for speed.
The dictionary has a shorter list for every vowel combination. As I mentioned in my code comments, the key “eio” is linked to a list of 1,227 6-letter words. So when I encounter words like “au”, I don’t need to check all 56,596 6-letter words, I only need to check 1,227. So, for just that sample, it runs 46 times faster.
Explain the Aggregate Operation!
I used the Linq operation ‘Aggregate’ a couple of times, like here:
string vowelKey = vowels.Where(v => aWord.Contains(v)) .Aggregate(“”, (p, c) => p + c);
For example, if aWord = “revoir”, then vowelKey will be assigned “eoi”.
Here’s a step-by-step breakdown of what each clause does:
- “Vowels.Where(v => aWord.Contains(v))” means:
- Loop through my list of vowels
- Build a list of each vowel (string) that meats the Where clause
- Namely, if aWord contains that vowel, add it to that list
- If you want to be picky, it is an IEnumerable<string>, not a “list”
- Take the list we just built and pipe it into an aggregate operation
- “Aggregate(“”, (p, c) => p + c)” means:
- “” – The empty quotes represent the seed.
- We add everything else to the seed
- We could have used something else as a seed, like a hyphen
- In which case the result would have been “-eio”, not “eio”
- (p, c) => p + c – perform this operation on every entry in the list
- p represents the accumulated result so far
- c is the current list entry, i.e. a vowel
- In case you didn’t know, the “+” operator concatenates two strings
- So, on the first pass, p == “” and c == “e”
- Second pass, p == “e” and c == “i”
- Third pass, p == “ei” and c == “o”
- “” – The empty quotes represent the seed.
Summary
Linq operators shorten the code quite a bit. The hashing capabilities of the dictionary make the solution run a lot faster.
Get the Code
Here’s a link to my drop box account to download the code and run it yourself (note that DropBox will require you to set-up a free account to get the code). I didn’t include my word list (too big), but you can download it here.
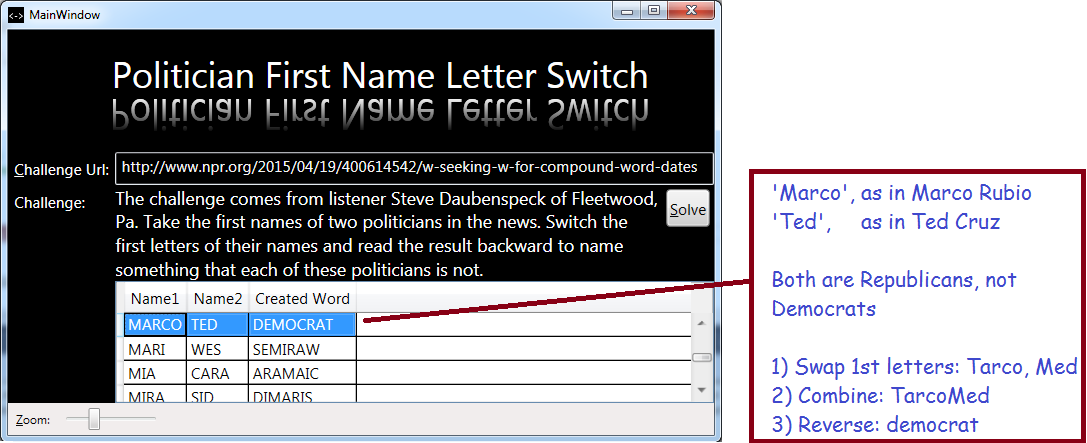
Puzzle Solved! Politician Name Swap
The Challenge
The challenge comes from listener Steve Daubenspeck of Fleetwood, Pa. Take the first names of two politicians in the news. Switch the first letters of their names and read the result backward to name something that each of these politicians is not.
Link: http://www.npr.org/2015/04/19/400614542/w-seeking-w-for-compound-word-dates
Techniques to Solve
My algorithm uses the following techniques:
- Background Workers
- Linq, Lambda Expressions and String Manipulation
- Binary Search
- File IO
Algorithm Overview
I don’t know of any list containing ‘politicians in the news’. I looked around on the web, and the closest thing I could find was a Wikipedia list of lists. It generally takes a quite while to chase down all those sub-lists, but I already had couple of nice lists of common first names (boy names and girl names). I elected to try checking all first names that might match the solution and then see how many names applied to politicians I recognized. Since only a small number (51) names could be manipulated to form an English word, it was relatively easy to look through those 51 and manually check if any matched-up with prominent politicians.
BackgroundWorker – Rationale
I used a BackgroundWorker because I wanted the grid to display work-in progress while it worked, instead of waiting until the end to see the all results. Since it takes over 2 minutes to solve, it’s a nice way to tell the users progress is being made. Important: in order to make this work, your grid should be bound to an ObservableCollection so that your grid will be aware of your updates.
When you use a BackgroundWorker, you hook-it-up to several methods which it will run at the appropriate time, including:
- DoWork – your method where you do the work!
- ProgressChanged – an event that is raised, where your other method can update the UI
- RunWorkerCompleted – fired when the DoWork method completes
The point is that we will update the UI in our ProgressChanged method, which will be on a different thread than the DoWork method. This allows the UI to update almost immediately, instead of waiting for the main thread to finish. Here’s how I set-up my worker:
//Declare the background worker at the class-level
private BackgroundWorker _Worker;
//... Use it inside my button-click event:
_Worker = new BackgroundWorker();
_Worker.WorkerReportsProgress = true;
//Tell it the name of my method, 'Worker_DoWork'
_Worker.DoWork += Worker_DoWork;
//Tell the worker the method to run when it needs to report progress:
_Worker.ProgressChanged += Worker_ProgressChanged;
//Likewise, tell it the name of the method to run when complete:
_Worker.RunWorkerCompleted += Worker_RunWorkerCompleted;
_Worker.RunWorkerAsync();
Hopefully this is pretty clear, my methods are nothing special. If you’re confused, I invite you to download my code (link at the bottom of this post) and take a look, Now let’s talk about the Linq and Lambda expressions I used inside my method ‘Worker_DoWork’.
Linq and Lambda Expressions
I didn’t use Linq/Lambda a lot, but I did use them to work with my list of names, specifically
- to perform a ‘self-join’ on my list of names
- to reverse my string (which gives me a list of char)
- and the ‘Aggregate’ method to convert my list of char back to a string
Here’s what I’m talking about:
var candidates = from n1 in allNames
from n2 in allNames
where n1 != n2
select new SolutionCandidate {
Combined = (n2[0] + n1.Substring(1) + n1[0] + n2.Substring(1))
.Reverse()
.Aggregate("", (p, c) => p + c),
Name1 = n1,
Name2 = n2
};
What is this code doing? It takes every entry in allNames, in combination with a corresponding entry in another instance of allNames (in case you’re wondering, ‘allNames’ is just a list of first names). The names in the first instance are referred to using the variable name ‘n1’, and the names in the second instance are referred to using name ‘n2’. In other words, create every possible 2-name combination. This is the equivalent of a Cartesian Product, which you should normally avoid due to huge results sets. But in this case, we actually want a Cartesian Product. If you’re thinking algorithm analysis, this code runs in O(n2) time. (Link explains my notation: http://en.wikipedia.org/wiki/Big_O_notation)
For every name pair (and there are quite a few!), the code above creates a SolutionCandidate, which is a little class with three properties, namely, ‘Combined‘, ‘Name1‘ and ‘Name2‘.
Take a look at how I create the ‘Combined’ property:
- n2[0] – this means: take the 0th char from n2 (i.e., the name from the 2nd instance of allNames)
- + n1.Substring(1) this means take a substrig of n1, starting at index 1, up to the end. In other words, all of it except the first letter (at index 0), and concatenate it the previous term (the plus sign means concatenate)
- + n1[0] this means get the 0th char of the name from the 1st instance of allNames, concatenate it too
- + n2.Substring(1) this means get all of the 2nd name except the first letter, and concatenate
After I do that, I invoke the ‘Reverse’ method on the result. Reverse normally works with lists (actually, with IEnumerable objects), but a string is actually a list of letters (char) so it will revers a string too. The problem is that the result is a list of char.
Finally, I convert my list of char back to a string using the ‘Aggregate‘ method. If I performed Aggregate on an list of numbers, I could use it to add each entry to create a sum, for example (I can do anything I want with each entry). But for a list of char, the equivalent to addition is concatenation.
Binary Searching
Binary search is an efficient way to check if some candidate is in your list. In our case, I want to check my list of all words to see if I created a real word by manipulating two first names. Here’s how I do that, remember that I build my list ‘candidates’ above and it contains a bunch of potential solutions:
foreach (var candidate in candidates)
if (allWords.BinarySearch(candidate.Combined) >= 0) {
//pass the candidate to a method on another thread to add to the grid;
//because it is on another theread, it loads immediately instead of when the work is done
_Worker.ReportProgress(0, candidate);
}
When I invoke ‘BinarySearch’, it returns the index of the entry in the list. But if the candidate is not found, it returns a negative number. BinarySearch runs in O(Log(n)) time, which is good enough for this app, which really only runs once. (I could squeeze out a few seconds by using a Dictionary or other hash-based data structure, but the dictionary would look a bit odd because I only need the keys, not the payload. The few seconds I save in run time is not worth the confusion of using a dictionary in a weird way.)
File IO
OK, I used some simple file IO to load my list of names, and also my list of all words. The code is pretty straightforward, so I’ll just list it here without any exegesis.
List//allNames will hold boy and girl names
//I run this code inside 'Worker_DoWork'
ReadNameFile(ref allNames, BOY_NAME_FILE, allWords);
ReadNameFile(ref allNames, GIRL_NAME_FILE, allWords);
//Here's the method that loads a file and adds the name to the list
private void ReadNameFile(ref List allNames, string fName, List allWords) {
string[] wordsArray = allWords.ToArray();
using (StreamReader sr = File.OpenText(fName)) {
while (sr.Peek() != -1) {
//The name is columns 1-16, so trim trailing blanks
string aName = sr.ReadLine().Substring(0, 15).TrimEnd();
int p = allNames.BinarySearch(aName);
if (p < 0)
//By inverting the result form BinarySearch, we get the position
//where the entry would have been. Result: we build a sorted list
allNames.Insert(~p, aName);
}
}
}
Notes on Improving the Efficiency
We pretty much need to perform a self-join on the list of names, and that is by far the slowest part of the app. It would be faster if we could reduce the size of the name list. One way to do that is to reject any names that could never form a solution. For example, ‘Hillary’ could not be part of a solution because,
- when we remove the first letter (H),
- we are left with hillar,
- which, when reversed, becomes ‘rallih’
- Since there are no English words that start with, or end with, ‘rallih’, I know that ‘Hillary’ is never part of the solution
I briefly experimented with this method; there are some issues. First, the standard implementation of BinarySearch only finds exact matches, not partial hits. Same thing for hash-based data structures, and a linear search is way too slow. You can write your own BinarySearch that will work with partial hits, but that leads us to the second issue.
The second issue is that, in order to do an efficient search for words that end with a candidate string, you need to make a separate copy of the word list, but with all the words spelled backwards, and run your custom binary search on it, again modifying the search to find partial matches.
After starting down that path, I elected to call it a wrap. My app runs in 2 minutes, which is slow but still faster than re-writing my code, perhaps to save 30 seconds of run time. To any ambitious readers, if you can improve my algorithm, please leave a comment!
Summary
I build a list of common names (with some simple file IO) and matched it against itself to form all combinations of common names (using Linq/Lambda Expressions); for each pair, I manipulated the names by swapping first letters and concatenating them. I then checked that candidate against my master list of all words, using a BinarySearch to check if the candidate exists in that list..
Download your copy of my code here
Defensive Coding with Linq and Generic Methods
Suppose you work with some off-shore programmers. Also suppose that those off-shore programmers write your BLL (Business Logic Layer) Code. Further, suppose those programmer constantly change your results without telling you. Finally, suppose they give you results in DataTable format, which is completely flexible and not strongly typed, thus making it hard to detect unannounced changes.
Given those assumptions, you’ve got a situation where they break your code all the time and leave you to clean-up the mess. And that is the situation I will address in this post.
Not to slam off-shore programmers per se, but perhaps something about working in a different time zone, in a different culture, makes it more likely they will not understand your needs, even if those needs seem blindingly obvious to you! So, my attitude is, just do the best you can under the circumstances and hope the blame falls on the right shoulders. Defensive coding will help. Even if your teammates work in the cube next to you, that type of coding can help.
What You Will Learn
- How to use Linq (actually Lambda expressions) on DataTables to check for missing columns
- How to use Generic Methods to simplify your logic for extracting data out of a DataTable while checking for misnamed columns
Step One: Check if the Table Returned by the BLL Team has the Columns You Need
If the result set lacks columns we need, we need to log that problem. Also, we should try to work with the data we get and avoid completely crashing. Here is my short-and-sweet method to log missing columns and check how many desired data columns are present in the data we get from the BLL. Basically, I use the ‘Except’ method to compare one list (the expected columns list) against another list (the actual column list in the data table):
public int ColumnMatchCount(DataTable dtReturnTable,
List<string> expectedColumnNames,
string callingMethod)
{
//Use the lambda expression 'Except' to determine which columns
//are not present in the data table provided by BLL
var unmatched = expectedColumnNames
.Except(dtReturnTable.Columns.Cast<DataColumn>()
.Select(c => c.ColumnName));
foreach (string missingCol in unmatched) {
//Log the problem column
_Logger.Log(LogLevel.Error, callingMethod +
" - expected BLL to provide column '"
+ missingCol
+ "' in the ReturnTable, but it was not present.");
}
//Tell the caller how many columns match
return expectedColumnNames.Count - unmatched.Count();
}
Key point: The data table has a columns collection we can compare using the Except method. Since DataTables are not quite the type of data that works with Linq, we use ‘Cast<DataColumn>() to make ti work. Because DataTables existed before Linq.
In my case, I will give my clients data if at all possible, i.e. if the BLL crew has given me at least one column that matches what they told me they would provide. I’ll provide some sample code shortly, but first, let’s look at my method to get the data out of the data table when the column I expect might not be there.
Step Two: Get Data from the DataTable When a Column is Missing
If the BLL gave me the column I expected, no big deal (of course, I also want to handle possible null values). But, if the column I want is not even present, a default value should be used instead. The method below does that, and it works for any data type, whether string, int, DateTime, etc. Because it is written as a Generic Method, it can handle any data type you provide.
public T CopyValueFromTable<T>(DataRow dr, string columnName)
{
T result = default(T);
if (dr.Table.Columns.Contains(columnName) && ! dr.IsNull(columnName))
result = (T)dr[columnName];
return result;
}The method takes a data row as input and examines that DataRow’s parent table.
dr.Table
That table has a Columns collection, and we can check it to see if the column exists or not.
if (dr.Table.Columns.Contains(columnName)
If the BLL crew remembered to give us the column we need, and it it is actually present and not null, then extract it.
dr[columnName]
If you understand Generic Methods, you will recognize that ‘T’ is the data type our caller wants us to use, so we convert the data column to type ‘T’. We cast it to type T using the parenthesis notation; remember that
‘T’ is a placeholder for any type, such as int, string, DateTime, etc.
result = (T)dr[columnName];
The first line in my method ensures that an appropriate default value will be returned if no other choice is available, the ‘default’ method will give us an empty string, a zero, etc., depending on what type is represented by ‘T’:
T result = default(T);
Putting it All Together
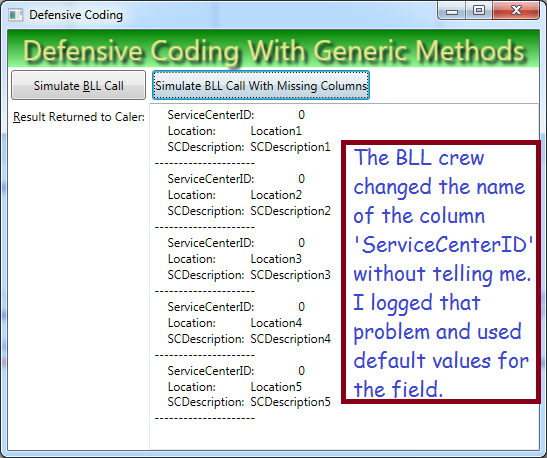
private void btnSimulateUnplanedChange_Click(object sender, RoutedEventArgs e) {
BLL dataFetcher = new BLL();
//Ask our simulated BLL to get some data, which will lack the column 'ServiceCenterID'
DataTable ReturnTable = dataFetcher.UnannouncedChange_GetServiceCenters();
List<string> expectedColumns = new List<string> { "Location",
"LocationDescription", "ServiceCenter", "SCDescription" };
List<InventoryResponse> response = new List<InventoryResponse>();
//If at least one column name matckes,
if (ColumnMatchCount(ReturnTable, expectedColumns, "GetResults") > 1) {
foreach (DataRow dr in ReturnTable.Rows) {
InventoryResponse invResp = new InventoryResponse();
invResp.ServiceCenterID = CopyValueFromTable<int>(dr, "ServiceCenterID");
invResp.Location = CopyValueFromTable<string>(dr, "Location");
invResp.SCDescription = CopyValueFromTable<string>(dr, "SCDescription");
response.Add(invResp);
}
txtResults.Text = RjbUtilities.DebuggerUtil.ComplexObjectToString(response);
} else {
_Logger.Log(LogLevel.Error, "No column names match the expected values");
}
}Summary
Sometimes you can’t work with top-quality programmers and possibly they don’t understand the concept of their teammates depending on their code. If you can’t force them to grow-up and communicate, at least you can make sure your code logs the problem and does the best it can with what they give you.
I showed you one method ‘ColumnMatchCount’ that checks how many expected columns are present the results the BLL crew gives you. I showed you another method ‘CopyValueFromTable’ that will provide default values and avoid crashing if the BLL crew renamed a column without telling you.
If you write similar defensive code, you might be lucky and your managers will blame the appropriate people!
Download my sample code here.
Sunday Puzzle Solved! Countries and Captials
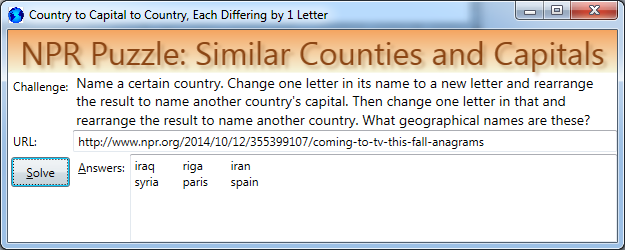
That one was fun, and pretty simple too! It was fun because I got to use some set-manipulation features of Linq. And it was easy because I already had the data files to solve with. Furthermore, I found two answers, and the puzzler thinks there is only one. Yipee, I found an extra answer! The only unsatisfactory part was suppressing duplicates in my answer list; perhaps some intrepid reader can suggest a more elegant solution.
The challenge:
Name a certain country. Change one letter in its name to a new letter and rearrange the result to name another country’s capital. Then change one letter in that and rearrange the result to name another country. What geographical names are these?
Challenge URL: http://www.npr.org/2014/10/12/355399107/coming-to-tv-this-fall-anagrams
What You Could Learn Here
- How to use Linq to compare lists in a fairly novel manner.
- How to use the Intersect method to tell if two words differ by just one letter. Hurray, set theory!
- How to sort strings using the Aggregate method
Algorithm
- Build a list of countries, all in lower case
- Build a list of capitals, also in lower case
- Using Linq, build a list of countries matching capitals…
- According to the following comparison method:
- They must have the same length (i.e., country must be same length as capital)
- And, when we take the intersection of the country with the capital, the result must have length 1 less than the original length
- When this condition is met, we have satisfied Will’s requirement to “change one letter in its name and rearrange the result to match another country’s capital”
- Take the resulting list from above and use Linq to compare it against the country list, using the same criteria
- The result will be a list containing our answer!
- The only problem is that each answer is listed twice, the countries having different order
- For example, Iraq/Riga/Iran will be listed, and so will Iran/Riga/Iraq
Here’s the Code
private void btnSolve_Click(object sender, RoutedEventArgs e) {
List<string> countryList, capitalList;
LoadTextFiles(out countryList, out capitalList);
//Match countries against capitals
var step1 = from cty in countryList
from cap in capitalList
where cap.Length == cty.Length
//Key functionality: the intersect function
&& cty.Intersect(cap).Count() == cty.Length - 1
select new { Country = cty, Capital = cap};
//Now match the result from above against the country list again
var step2 = from pair1 in step1
from cty in countryList
where pair1.Capital.Length == cty.Length
&& pair1.Country != cty
&& pair1.Capital.Intersect(cty).Count() == pair1.Capital.Length - 1
select new { Country1 = pair1.Country, Capital = pair1.Capital, Country2 = cty };
//At this point, we have the answers, but they are duplicated, for example
//"Iran Riga Iraq" vs. "Iraq Riga Iran"
//Use the list below to avoid displaying dups:
List<string> distinctLetters = new List<string>();
foreach (var answer in step2) {
//Concatenate the countryies/captial, then sort;
//the sorted letters will determine duplicates
string sortedLetters = (answer.Country1 + answer.Capital + answer.Country2)
.OrderBy(c => c)
//'Aggregate' transforms the list back into a string:
.Aggregate("", (p, c) => p + c);
//If we have not yet displayed this answer, do so now and
//record that fact in distinctLetters
if (!distinctLetters.Contains(sortedLetters)) {
distinctLetters.Add(sortedLetters);
string displayMe = string.Format("{0}\t{1}\t{2}\n",
answer.Country1, answer.Capital, answer.Country2);
txtAnswer.Text += displayMe;
}
}
}
/// <summary>
/// Load the Capital/Country file into two lists
/// </summary>
/// <param name="countryList">The list of countries</param>
/// <param name="captialList">The list of capitals</param>
private void LoadTextFiles(out List<string> countryList,
out List<string> captialList) {
countryList = new List<string>();
captialList = new List<string>();
using (StreamReader sr = File.OpenText(CAPITAL_FILE)) {
while (sr.Peek() != -1) {
//Sample line looks like this: Athens~Greece
string aLine = sr.ReadLine().ToLower();
//find the tilde so we can separate the capital from the country
int p = aLine.IndexOf("~");
captialList.Add(aLine.Substring(0, p));
countryList.Add(aLine.Substring(p + 1));
}
}
}
Download my code here: https://www.dropbox.com/s/wix8r5jb1pipjha/12Oct2014.zip?dl=0
