
coding for fun
Sunday Puzzle: Nationality, Demonyms and Consonyms!
This week’s challenge is a spinoff of my (e.g. Will’s) on-air puzzle. Name two countries that have consonyms that are nationalities of other countries. In each case, the consonants in the name of the country are the same consonants in the same order as those in the nationality of another country. No extra consonants can appear in either name. The letter Y isn’t used.
Link to the Challenge
Definition Demonym; noun: A name for an inhabitant or native of a specific place that is derived from the name of the place.
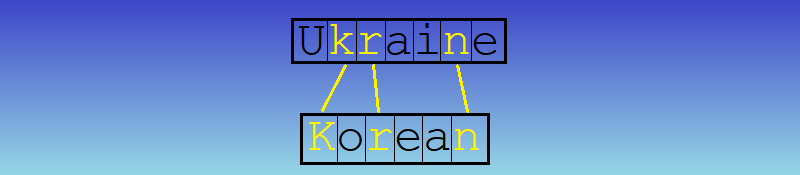
Synopsis
Well, that was a nice, easy, fun one! Happily, I already had a list of nations and their demonyms, so it was just a matter of making two lists and matching them against each other. Each of those two lists contains the original word plus its consonym. One list uses the country as the original word, the other uses nationality as the original word. We match the lists using the consonym.
I elected to use WPF once again, mainly because it produces a nice UI and I am pretty fast in it. The choice of UI is fairly unimportant for solving this puzzle, since there is almost no interaction with the user, other than clicking the Solve button.
If you read through to the end, I’ll explain my big learning moment writing this code. Yes, I made a big mistake because I misunderstood something tricky about Linq. Hopefully you can save time by learning from my goof!
In case anyone is following me, I hope I don’t sound too over-confident in my analysis, possibly discouraging you. I always do the write-up as if I knew what I was doing from the very start, as if solving the puzzle is inevitable due to my great skill 😏. But that is not the case at all! I have a lot of struggles and plenty of dead ends. So I hope you don’t feel unworthy if I accidentally make it sound easier than it truly is. Because in reality, it only seems easy after I finally succeed.
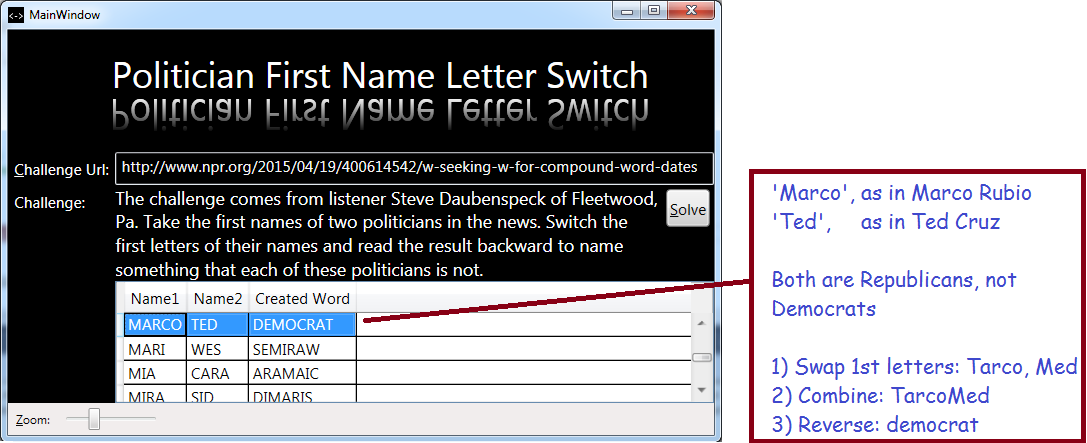
Screenshot Showing My Results:
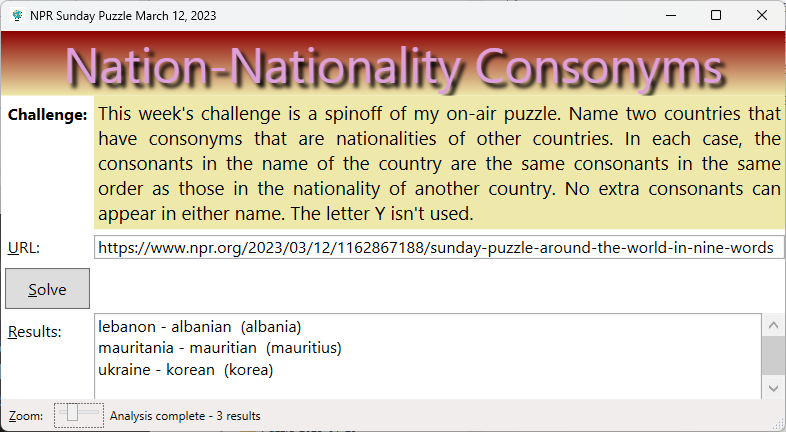
I got 3 results, but from Will’s description, I think he expects two results. I re-read his description a few times and don’t see anything I misinterpreted, so let’s see what he says come Sunday. Maybe there was some confusion over Mauritania and Mauritius, two very similar names.
Techniques Used
Difficulty Level
- Intermediate
- Dogged beginners
Algorithm
We start with a file that looks like the following (you can download your own copy below):
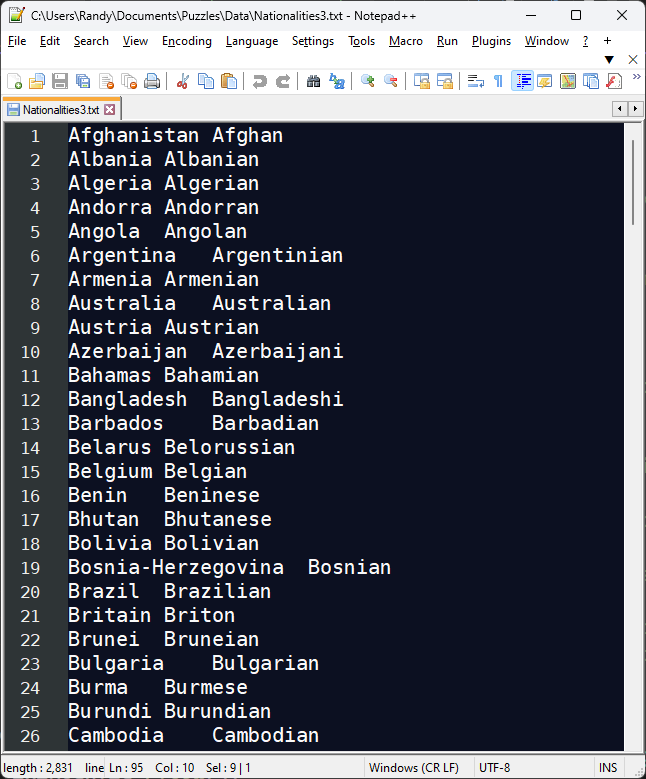
As you can see above, this file has two columns, separated by a tab character. The country comes first, followed by the demonym. Given this file structure, we take the following steps to find a solution:
- Open the file for reading
- Read one line at a time
- Split the line on the tab character, effectively separating the two words
- Build two lists,
- Using the two words from the line we just split
- One list for nationalities
- The other for demonyms
- Each list will contain a data type (a class in this case) which contains the original word and its consonym (refer to the image below)
- After we finish reading the file and building the list,
- Match the two lists using the consonym field
- Note that some countries will match against their own demonym, for example
- Britain → brtn → Briton (consonants “brtn” for both)
- Therefore, when we match the two lists, we need to avoid self-matching by requiring that the matched demonym not come from the original country
Illustration of Matching the Two Lists
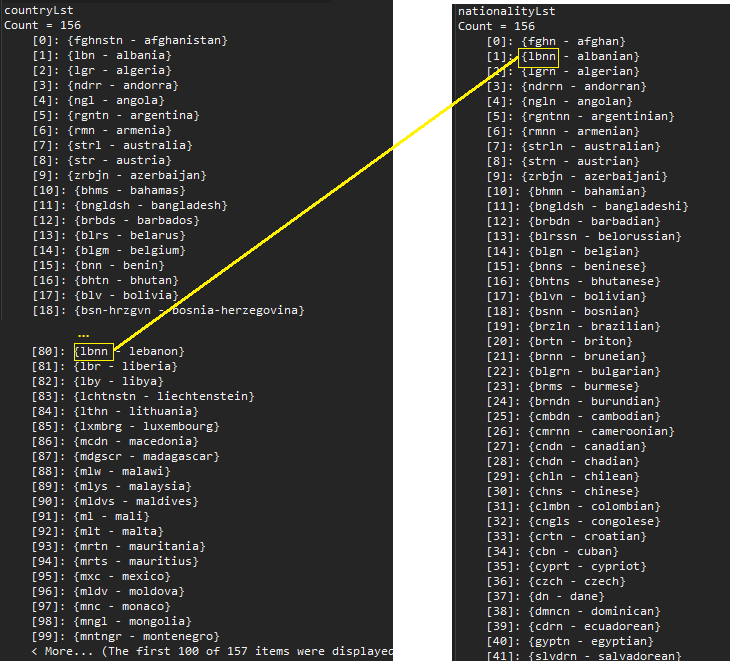
ConsonymWordPair , which consists of the consonants plus the original word. When we match entries on the left against those on the right, we find a match for “lbnn” in both lists. Now we know the two original words share a consonym, one word being a country and the other a nationality. Here’s The Code!
//This is the main method; it runs when user clicks the 'solve' button
private void btnSolve_Click(object sender, RoutedEventArgs e) {
txtResults.Clear();
txtMessage.Text = "";
//1) The subroutine (method) reads my file and builds the two lists:
var (countryLst, nationalityLst) = BuildCountryNationalityLists();
var solutionCount = 0;
//2) Loop through the country list and match against the nationality list
foreach (var c in countryLst) {
//3) Get all the nationalities whose Consonym matches the country's
var matches = nationalityLst.Where(n => n.Consonym == c.Consonym);
foreach (var m in matches) {
//4) 'Mate' is my term for the original country
//I call it 'Mate' to make the class name more generic
//If the country's consonym is the same as its nationalit's, skip it
if (m.Mate != c.Mate) {
//5) Display the results!
txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n";
solutionCount++;
}
}
}
txtMessage.Text = $"Analysis complete - {solutionCount} results";
}
Discussion – Main Method
🙆🏻I really like how short the main method is, it makes me feel good to write concise code that does something useful and, hopefully, something cool!
Numbered notes below correspond to the numbered comments above. If you already understand the code above, skip ahead to the next heading!
- The subroutine reads my file and builds the two lists
var (countryLst, nationalityLst) = BuildCountryNationalityLists();- That subroutine (‘
BuildCountryNationalityLists‘) is listed below - Note that this method returns two variables,
countryLstnationalityLst
- Which is one of my favorite features of .NET!
- Both lists contains
ConsonymWordPairelements (a class defined below)
- Loop through the country list and match against the nationality list
foreach (var c in countryLst) {- The variable ‘
c‘ is an instance of my class ‘ConsonymWordPair‘ - And we will examine all 156 of them, one per loop pass
- Get all the nationalities whose Consonym matches the country’s
- The Linq method
Wheredoes a search on the listnationalityLstvar matches = nationalityLst.Where(n => n.Consonym == c.Consonym);n.Consonymrefers to the nationality consonym- c
.Consonymrefers to the demonym consonym (say that 3 times fast!)
- And returns all the matches.
- Theoretically there could be more than one match, but not with this data
- The Linq method
- ‘Mate’ is my term for the original country
-
if (m.Mate != c.Mate) { - The class is named ‘
ConsonymWordPair‘, but I added an extra field ‘Mate'after naming it - So it isn’t really a pair any more 😑- whoops!
- The if-statement,
if (m.Mate != c.Mate)ensures that I don’t accidentally match, for example, Briton against Britain
-
- Display the results!
txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n";- That code appends a new solution to the textbox called ‘
txtResults‘ - The
+=operator causes the new string to be appended to the existing one - We build a string to append using the
$""nomenclature - This allows us to mix variables with text in a more natural way
- Variables are recognized inside the
{}brackets; everything else is plain text - Note that
\n(look at the end of the line) is how we specify a newline
Method ‘BuildCountryNationalityLists’
private (List<ConsonymWordPair>, List<ConsonymWordPair>) BuildCountryNationalityLists() {
//1) Build the two empty lists which we will populate and return:
var countryLst = new List<ConsonymWordPair>();
var nationalityLst = new List<ConsonymWordPair>();
//2) NATIONALITY_FILE is defined at the class-level; it is the file name
using var sr = File.OpenText(NATIONALITY_FILE);
//3) Read until end-of-file detected
while (sr.Peek() != -1) {
//4 Read the line, convert to lower case, split on tab character
//The split operation means that 'twain' is an array
var twain = sr.ReadLine().ToLower().Split('\t');
if (twain != null && twain.Length == 2) {
//5) twain[0] is the country name; build a pair with the
//word and its consonants
var c1 = RemoveVowels(twain[0]);
var cwp1 = new ConsonymWordPair(twain[0], c1, twain[0]);
countryLst.Add(cwp1);
//6) Now do the same for the nationality, which is in twain[1]:
var c2 = RemoveVowels(twain[1]);
var cwp2 = new ConsonymWordPair(twain[1], c2, twain[0]);
nationalityLst.Add(cwp2);
}
}
return (countryLst, nationalityLst);
}Discussion – BuildCountryNationalityLists
The method reads the file and builds two lists. As above, the list numbers below correspond to numbered comments above. The string operators used are ToLower and Split. The three File IO operators are File.OpenText, StreamReader.Peek and StreamRead.ReadLine. By putting this code in a separate method, the main method is simplified and easier to read.
- Build the two empty lists which we will populate and return
- Each list contains an instance of my class ‘
ConsonymWordPair‘
- Each list contains an instance of my class ‘
- NATIONALITY_FILE is defined at the class-level; it is the file name
- The variable
sris a StreamReader that can read a line at a time - The ‘
using‘ keyword guarantees that the stream will be closed and disposed
- The variable
- Read until end-of-file detected
- The StreamReader has a
Peekmethod that returns -1 whenEOFis detected, that terminates mywhile-loop
- The StreamReader has a
- Read the line, convert to lower case, split on tab character. The split operation means that ‘twain’ is an array
- I’m doing 3 things in this line:
var twain = sr.ReadLine().ToLower().Split('\t');
ReadLineshould be obviousToLowerconverts to lower case, so that I won’t try comparing ‘Lbnn’ against ‘lbnn’, because those two strings are not equal!- Split does what it says → it finds the tab character (\t) and splits the line every time it finds it
- The result is an array with two elements:
- Element 0: the country name (everything to the left of the tab)
- Element 1: And the nationality (everything to the right of the tab
- I’m doing 3 things in this line:
- twain[0] is the country name; build a pair with the word and its consonants
- The code below invokes my method
RemoveVowels, passing twain[i] as the inputvar c1 = RemoveVowels(twain[0]);
- For example, if the line was ‘Albania Albanian’
- Then twain[0] is ‘albania’ (note the lowercase ‘a’)
- The output from invoking
RemoveVowelsis ‘lbn’
- The code below invokes my method
- Now do the same for the nationality, which is in twain[1]:
- Following the example above,
twain[1]will be ‘albanian’ - The output from invoking RemoveVowels is ‘lbnn’
- Following the example above,
RemoveVowels Method
This method is really simple, so I won’t bore you with any unnecessary explanation. Here’s the code!
private string RemoveVowels(string input) {
//StringBuilder is easy to use and a more memory-efficient way to build a string
var result = new StringBuilder();
//Declare and initialize the array of char
var vowels = new[] { 'a', 'e', 'i', 'o', 'u' };
//Examine each char in the input string
foreach (var c in input)
if (!vowels.Contains(c))
result.Append(c);
return result.ToString();
}Class ‘ConsonymWordPair’
internal class ConsonymWordPair {
//1) My three public properties, the most important part of the class
public string Consonym { get; set; }
public string Word { get; set; }
public string Mate { get; set; }
//2) Default constructor
public ConsonymWordPair() {
Consonym = Word = Mate = "";
}
//3) 3-parameter constructor
public ConsonymWordPair(string newWord, string newConsonym, string newMate) : this() {
Word = newWord;
Consonym = newConsonym;
Mate = newMate;
}
public override string ToString() {
var result = $"{Consonym} - {Word}";
return result;
}
}Discussion – ConsonymWordPair
- My three public properties, the most important part of the class
- The remainder of the class is practically fluff
- As mentioned before, “pair” is not quite accurate any more, but “tuple” is harder to understand
- Default constructor
- Ensures that the public properties are initialized
- 3-parameter constructor
- The constructor used by the caller. Note that it actually invokes the default constructor with the code “
: this()“ - A pattern I try to follow which ensures the code in the default constructor is only written once
- The constructor used by the caller. Note that it actually invokes the default constructor with the code “
One other thing, the ToString method is not invoked when I solve the puzzle – so why did I write it? The answer is that Visual Studio uses it to display the list contents during debug sessions. When I hover my mouse over the pertinent variable (a list), it displays the contents using my method. Note that I built the image above (showing how the two lists are matched against each other) using the Immediate Pane in a debug session. Again, Visual Studio utilized my ToString method to display the data in that pane for me. Kind of the opposite of “immediate pain” 😉.
Lessons Learned
🙎🏼I made one big booboo writing this code: I used .NET’s Except method instead of my current method RemoveVowels. It didn’t work and I was surprised 😒! Except doesn’t work the way I thought it does, and I’ve been using it for years. I sure hope I didn’t create any bugs in production because of this.
Here’s some sample bad code that illustrates how I attempted to use Except:
var vowels = new[] { 'a', 'e', 'i', 'o', 'u' };
var twain = new[] {"albania", "albanian"};
var c1 = twain[0].Except(vowels).Aggregate("", (p,c) => p + c);
Console.WriteLine(c1);
var c2 = twain[1].Except(vowels).Aggregate("", (p,c) => p + c);
Console.WriteLine(c2);Can you guess what the output is for c2? I’ll keep you in suspense while I explain my code.
- Note that
twain[0]contains the string “albania” - When I invoke
Excepton it, passingvowelsas the input parameter, I get anIEnumerable<char>as the output (something like a list) that looks like the following:- ‘l’
- ‘b’
- ‘n’
- In other words, I get everything except the vowels. Just what we all expected.
- The code fragment
.Aggregate("", (p,c) => p + c)serves to create a string from the IEnumerable; basically it iterates the char elements and uses the+operator to concatenate them into a string
OK, now that I’ve explained how c1 is created, what do you think the value of c2 is? The code is the same for both, except the input for creating c2 is “albanian”. To my surprise, c1 is “lbn”. I expected “lbnn”, i.e. two n’s. .NET dropped one of my n’s.
What happened? Except works on IEnumerables, and I gave it a string, which .NET treated like a list of char. So far, so good. Reading the documentation, it doesn’t say anything about applying the Distinct operator, so all I can guess is that, under set operations, no one cares about preserving duplicates. Yes, I studied Set Theory in college, and I don’t remember anything like that, but it does seem somewhat consistent with how we did things then. So I don’t really know why it behaves that way, but now you know what to expect!
Efficiency Analysis
OK, my data file is only 156 lines long, and the code runs in just 7 milliseconds (according to .NET when running in debug mode, see below).
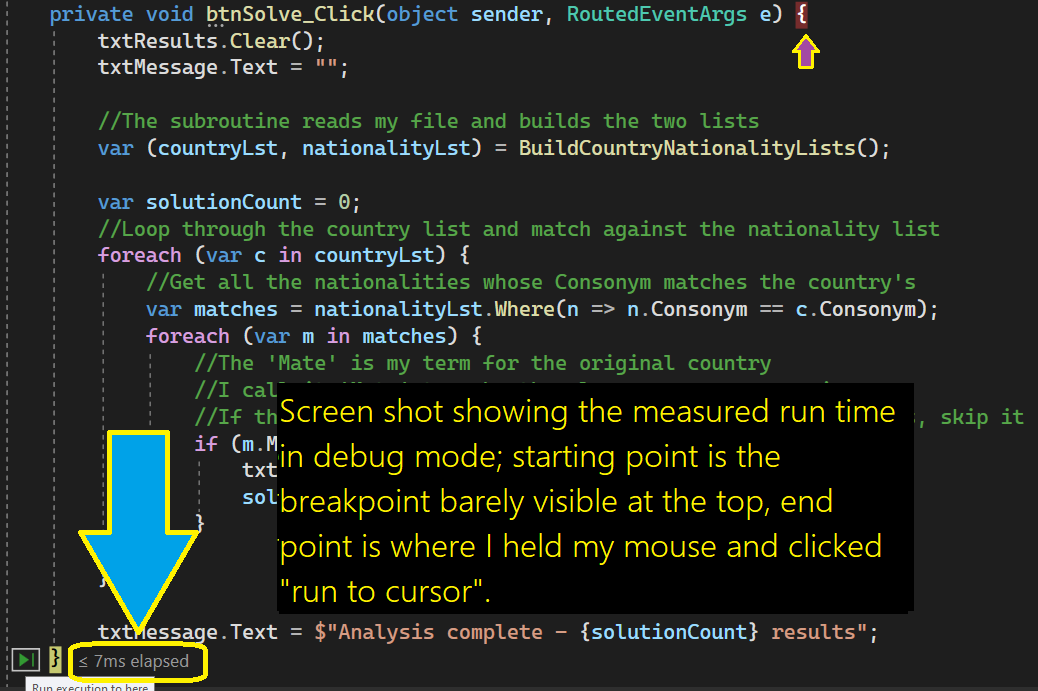
So, I must admit that we don’t care much about whether this code runs in 7 milliseconds, or 500 milliseconds – you’ve already burned thousands of milliseconds reading this😊 But it’s always good to understand the performance of your code, for one reason, it’s interesting!
The algorithm I used runs in O(n2), meaning that it first runs through the main list (the countries) and, for each pass through that list, makes another pass through the other list (nationalities), searching for a match. In this type of analysis, we ignore the fact that the 2nd search/array pass completes in an average of just half the array size; instead we focus on limiting behavior.
For our calculations, each pass in the first list means a pass through the second, so if the first array has length n, then the algorithm runs in n × n passes, or n2.
How to Improve Performance
I could have improved my performance by storing nationalities in a dictionary instead of a list. Note that .NET dictionaries use hashing instead of what I used, namely, a linear search. Hashing is much more efficient because we can determine whether some nationality exists in our dictionary in just O(1) run time, basically one calculation instead of examining the whole list. O(1) is generally the fastest possible run time.
By using a dictionary, my algorithm could have had a run time of O(n). Maybe that would shave a whole millisecond off my run time! I leave it as an exercise for the reader to make those sweet changes. Realistically, the bottleneck for this app is the file I/O, which typically runs 1000 times slower than memory calculations, though that won’t be anywhere near as bad if you have an SSD drive.
Improve Even More?
If we want to get ridiculous and shave off another millisecond, we can parallelize the main loop. That would also require that we use some sort of locking to make sure that different threads don’t update the display simultaneously and interfere with each other; either use of the lock keyword or else Dispatcher.Invoke.
The main loop would look like the following:
Parallel.ForEach(countryLst, (c) => {
var matches = nationalityLst.Where(n => n.Consonym == c.Consonym);
foreach (var m in matches) {
if (m.Mate != c.Mate) {
Dispatcher.Invoke(() => txtResults.Text += $"{c.Word} - {m.Word} ({m.Mate})\n");
solutionCount++;
}
}
});Since my PC has 20 cores, the code above would potentially run 20 times faster than my current main loop. Who knows what amazing things I could do with the time I saved using that technique! Seriously though, parallelization is a powerful tool for tackling certain difficult problems.
Download the Code
Here’s a copy of my code. If you choose to download it, remember to modify the file path (at the top of the code) to reference a location on your computer, not on mine. Here’s a copy of my nationalities file. You will need a free Dropbox account to download.
Puzzle Solved! Politician Name Swap
The Challenge
The challenge comes from listener Steve Daubenspeck of Fleetwood, Pa. Take the first names of two politicians in the news. Switch the first letters of their names and read the result backward to name something that each of these politicians is not.
Link: http://www.npr.org/2015/04/19/400614542/w-seeking-w-for-compound-word-dates
Techniques to Solve
My algorithm uses the following techniques:
- Background Workers
- Linq, Lambda Expressions and String Manipulation
- Binary Search
- File IO
Algorithm Overview
I don’t know of any list containing ‘politicians in the news’. I looked around on the web, and the closest thing I could find was a Wikipedia list of lists. It generally takes a quite while to chase down all those sub-lists, but I already had couple of nice lists of common first names (boy names and girl names). I elected to try checking all first names that might match the solution and then see how many names applied to politicians I recognized. Since only a small number (51) names could be manipulated to form an English word, it was relatively easy to look through those 51 and manually check if any matched-up with prominent politicians.
BackgroundWorker – Rationale
I used a BackgroundWorker because I wanted the grid to display work-in progress while it worked, instead of waiting until the end to see the all results. Since it takes over 2 minutes to solve, it’s a nice way to tell the users progress is being made. Important: in order to make this work, your grid should be bound to an ObservableCollection so that your grid will be aware of your updates.
When you use a BackgroundWorker, you hook-it-up to several methods which it will run at the appropriate time, including:
- DoWork – your method where you do the work!
- ProgressChanged – an event that is raised, where your other method can update the UI
- RunWorkerCompleted – fired when the DoWork method completes
The point is that we will update the UI in our ProgressChanged method, which will be on a different thread than the DoWork method. This allows the UI to update almost immediately, instead of waiting for the main thread to finish. Here’s how I set-up my worker:
//Declare the background worker at the class-level
private BackgroundWorker _Worker;
//... Use it inside my button-click event:
_Worker = new BackgroundWorker();
_Worker.WorkerReportsProgress = true;
//Tell it the name of my method, 'Worker_DoWork'
_Worker.DoWork += Worker_DoWork;
//Tell the worker the method to run when it needs to report progress:
_Worker.ProgressChanged += Worker_ProgressChanged;
//Likewise, tell it the name of the method to run when complete:
_Worker.RunWorkerCompleted += Worker_RunWorkerCompleted;
_Worker.RunWorkerAsync();
Hopefully this is pretty clear, my methods are nothing special. If you’re confused, I invite you to download my code (link at the bottom of this post) and take a look, Now let’s talk about the Linq and Lambda expressions I used inside my method ‘Worker_DoWork’.
Linq and Lambda Expressions
I didn’t use Linq/Lambda a lot, but I did use them to work with my list of names, specifically
- to perform a ‘self-join’ on my list of names
- to reverse my string (which gives me a list of char)
- and the ‘Aggregate’ method to convert my list of char back to a string
Here’s what I’m talking about:
var candidates = from n1 in allNames
from n2 in allNames
where n1 != n2
select new SolutionCandidate {
Combined = (n2[0] + n1.Substring(1) + n1[0] + n2.Substring(1))
.Reverse()
.Aggregate("", (p, c) => p + c),
Name1 = n1,
Name2 = n2
};
What is this code doing? It takes every entry in allNames, in combination with a corresponding entry in another instance of allNames (in case you’re wondering, ‘allNames’ is just a list of first names). The names in the first instance are referred to using the variable name ‘n1’, and the names in the second instance are referred to using name ‘n2’. In other words, create every possible 2-name combination. This is the equivalent of a Cartesian Product, which you should normally avoid due to huge results sets. But in this case, we actually want a Cartesian Product. If you’re thinking algorithm analysis, this code runs in O(n2) time. (Link explains my notation: http://en.wikipedia.org/wiki/Big_O_notation)
For every name pair (and there are quite a few!), the code above creates a SolutionCandidate, which is a little class with three properties, namely, ‘Combined‘, ‘Name1‘ and ‘Name2‘.
Take a look at how I create the ‘Combined’ property:
- n2[0] – this means: take the 0th char from n2 (i.e., the name from the 2nd instance of allNames)
- + n1.Substring(1) this means take a substrig of n1, starting at index 1, up to the end. In other words, all of it except the first letter (at index 0), and concatenate it the previous term (the plus sign means concatenate)
- + n1[0] this means get the 0th char of the name from the 1st instance of allNames, concatenate it too
- + n2.Substring(1) this means get all of the 2nd name except the first letter, and concatenate
After I do that, I invoke the ‘Reverse’ method on the result. Reverse normally works with lists (actually, with IEnumerable objects), but a string is actually a list of letters (char) so it will revers a string too. The problem is that the result is a list of char.
Finally, I convert my list of char back to a string using the ‘Aggregate‘ method. If I performed Aggregate on an list of numbers, I could use it to add each entry to create a sum, for example (I can do anything I want with each entry). But for a list of char, the equivalent to addition is concatenation.
Binary Searching
Binary search is an efficient way to check if some candidate is in your list. In our case, I want to check my list of all words to see if I created a real word by manipulating two first names. Here’s how I do that, remember that I build my list ‘candidates’ above and it contains a bunch of potential solutions:
foreach (var candidate in candidates)
if (allWords.BinarySearch(candidate.Combined) >= 0) {
//pass the candidate to a method on another thread to add to the grid;
//because it is on another theread, it loads immediately instead of when the work is done
_Worker.ReportProgress(0, candidate);
}
When I invoke ‘BinarySearch’, it returns the index of the entry in the list. But if the candidate is not found, it returns a negative number. BinarySearch runs in O(Log(n)) time, which is good enough for this app, which really only runs once. (I could squeeze out a few seconds by using a Dictionary or other hash-based data structure, but the dictionary would look a bit odd because I only need the keys, not the payload. The few seconds I save in run time is not worth the confusion of using a dictionary in a weird way.)
File IO
OK, I used some simple file IO to load my list of names, and also my list of all words. The code is pretty straightforward, so I’ll just list it here without any exegesis.
List//allNames will hold boy and girl names
//I run this code inside 'Worker_DoWork'
ReadNameFile(ref allNames, BOY_NAME_FILE, allWords);
ReadNameFile(ref allNames, GIRL_NAME_FILE, allWords);
//Here's the method that loads a file and adds the name to the list
private void ReadNameFile(ref List allNames, string fName, List allWords) {
string[] wordsArray = allWords.ToArray();
using (StreamReader sr = File.OpenText(fName)) {
while (sr.Peek() != -1) {
//The name is columns 1-16, so trim trailing blanks
string aName = sr.ReadLine().Substring(0, 15).TrimEnd();
int p = allNames.BinarySearch(aName);
if (p < 0)
//By inverting the result form BinarySearch, we get the position
//where the entry would have been. Result: we build a sorted list
allNames.Insert(~p, aName);
}
}
}
Notes on Improving the Efficiency
We pretty much need to perform a self-join on the list of names, and that is by far the slowest part of the app. It would be faster if we could reduce the size of the name list. One way to do that is to reject any names that could never form a solution. For example, ‘Hillary’ could not be part of a solution because,
- when we remove the first letter (H),
- we are left with hillar,
- which, when reversed, becomes ‘rallih’
- Since there are no English words that start with, or end with, ‘rallih’, I know that ‘Hillary’ is never part of the solution
I briefly experimented with this method; there are some issues. First, the standard implementation of BinarySearch only finds exact matches, not partial hits. Same thing for hash-based data structures, and a linear search is way too slow. You can write your own BinarySearch that will work with partial hits, but that leads us to the second issue.
The second issue is that, in order to do an efficient search for words that end with a candidate string, you need to make a separate copy of the word list, but with all the words spelled backwards, and run your custom binary search on it, again modifying the search to find partial matches.
After starting down that path, I elected to call it a wrap. My app runs in 2 minutes, which is slow but still faster than re-writing my code, perhaps to save 30 seconds of run time. To any ambitious readers, if you can improve my algorithm, please leave a comment!
Summary
I build a list of common names (with some simple file IO) and matched it against itself to form all combinations of common names (using Linq/Lambda Expressions); for each pair, I manipulated the names by swapping first letters and concatenating them. I then checked that candidate against my master list of all words, using a BinarySearch to check if the candidate exists in that list..
Download your copy of my code here
NPR Puzzle Solved! 9-Letter City → Two
Yippee-kai-yay! That was a super-fast solution.
What You will Learn
- Simple file IO
- Simple string manipulation
- Simple WCF layout, design, and other techniques
The challenge:
This week’s challenge comes from listener Steve Baggish of Arlington, Mass. Think of a U.S. city whose name has nine letters. Remove three letters from the start of the name and three letters from the end. Only two will remain. How is this possible, and what city is it?
Link to the challenge
And here’s a screen shot of my solution:

In case you don’t get it, the middle 3 letters of ‘Fort Worth’ are ‘two‘.
The Algorithm
- Loop through the file containing city names
- Convert each to lower case and remove spaces
- Take the substring representing the middle 3 characters
- If the result is ‘two’, ‘2’ or else has length 2, then we have a winner!
Here’s the short, sweet code:
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
StringBuilder sb = new StringBuilder();
//Open the file for reading:
using (StreamReader sr = File.OpenText(CITY_FILE)) {
//Loop until the end:
while (sr.Peek() != -1) {
string curLine = sr.ReadLine();
//send the input to lowercase and remove spaces:
string city = curLine
.ToLower()
.Replace(" ", "");
//Only look at cities having length 9:
if (city.Length == 9) {
string candidate = city.Substring(3, 3);
if (candidate == "two" || candidate == "2" || candidate.Length == 2)
sb.AppendFormat("Original city: '{0}'\nAfter removing first 3 and last 3: '{1}'\n",
curLine, city.Substring(3, 3));
}
}
}
lblResults.Visibility = txtResults.Visibility = System.Windows.Visibility.Visible;
txtResults.Text = sb.ToString();
Mouse.OverrideCursor = null;
}Comments
To be honest, I just got lucky with this one. I just wrote the code to chop-off the first 3 and last three and display it in a list. As it happens, the very first entry in my temporary results was the winner. Too bad there’s no way to profit on this one, as the reward divided by the effort was very favorable!
Als, I had the list of cities lying around from previous puzzle attempts, but I believe I originally downloaded it from wikipedia (after writing some code to clean-it-up. If you download my sample code, the file is included.
Calculator Letters Puzzle – Solved!
Or, Fun with Lambdas and Set Functions!
The challenge:
This three-part challenge comes from listener Lou Gottlieb.
If you punch 0-1-4-0 into a calculator, and turn it upside-down, you get the state OHIO.
What numbers can you punch in a calculator, and turn upside-down, to get a state capital,
a country and a country’s capital?

Puzzle Location:
http://www.npr.org/2014/09/14/348220755/the-puzzle-and-the-pea
The Solution Revealed!

- State Capitals
- World Capitals
- Countries
I’ve included those data files in my code download; if you run my code, note that their path will be different on your PC than mine.
Next, we’ll make a list of the available letters, which I have listed in the image below:

Once we have the data, it is basically a matter of determining whether one string set is entirely included within another string set. In other words, we will ask, for a number of solution candidates, whether it is a proper subset of the set of calculator letters.
To determine whether we have a subset, it is fun to use the Linq built-in set operators. In particular, we can use the method ‘Except‘. I also could have used the HashSet functionality, which actually has a method named ‘IsProperSubSet’, but HashSet is not as convenient as Linq and I just wanted to crank-out some code!
Using Linq, we can determine that one string is a proper subset of another if, when we use Except on them, the result is the empty set, i.e. a list with no members. Examples:
- “atlanta”.Except(“beignlos”) will return a list containing (‘a’, ‘t’), i.e. not a subset.
- “cheyenne”.Except(“beignlos”) will return a list containing (‘c’, ‘h’, ‘y’). Also not a subset.
- “boise”.Except(“beignlos”) returns the empty set, i.e. it is the answer!
Note: “beignlos” is a string containing all the calculator letters. The true benefit of the ‘Except’ method is apparent below:
Here’s a Super-Cool Sample of the .NET Set-Operator ‘Except’
var leftoverLetters = "boise".Except("beignlos");
if (leftoverLetters.Count() == 0)
Console.WriteLine("Ding ding ding - we have a winner!");
Conclusion: ‘boise’ is a subset of ‘beignlos’ –> you can spell ‘Boise’ using upside down calculator letters, and the Except function tells us that.
Use Set-Operators at Work, Too!
At work, I have recently used the ‘Except’ operator to find orders that were lost. Something along these lines: ‘var missing = outboundOrders.Except(inBoundOrders);‘
My guess is you can use the Except operator to identify a lot of other things!.
Using Lambdas as ‘First Class’ Objects
First, a little bit of terminiology: “First class objects” are objects that you can use like any other entity. Such uses include passing them as parameters. When you pass a Lambda expression as a parameter, you are taking advantage of the fact that Lambdas are first class objects.
Why did I tell you that? Because my code benefited from it in this fun little app. In particular, I have these needs:
- I need to perform the same work on 3 different files (state capitals, world capitals, countries)
- Each file has a different layout
- I would like to write a single method to do the same work for each file
- To do so, I could write 3 different lambdas; each knowing how to extract the candidate from a line in a file
- And then pass each lambda as an input parameter it to my method
- Benefit: I write one method, which uses a lambda to extract the candidate, instead of 3 methods, each with their own
techinque to extract the candidates
Here’s the Code
private void btnSolve_Click(object sender, RoutedEventArgs e) {
//Make a definition list of the calculator letters.
//This maps letters to the numbers they represent in a calculator.
//Each letter is in lower case to make matching easier
//Note: a 'tuple' is a type of anonymous class
List<Tuple<char, int>> calculatorLetterMap =
new List<Tuple<char, int>>() { Tuple.Create('b', 8),
Tuple.Create('e', 3),
Tuple.Create('i', 1),
Tuple.Create('g', 6),
Tuple.Create('n', 4),
Tuple.Create('l', 7),
Tuple.Create('o', 0),
Tuple.Create('s', 5)
};
//The next 3 lines process state capitals:
Func<string, string> extractStatCap = (aLine => {
//Look for hyphen, take the rest of the line, trimmed, in lowercase
return aLine.Substring(aLine.IndexOf('-') + 2)
.TrimEnd()
.ToLower();
});
List<string> stateCapHits = GetFileMatchesAgainstLetterSet(STATE_CAPITALS_FILE,
calculatorLetterMap, extractStatCap);
DisplayHits(stateCapHits, "State Capitals", calculatorLetterMap, txtResults);
//Now world capitals:
//The function is a bit more complicated because some names have spaces, such as 'Abu Dhabi'
Func<string, string> extractPlaceFunc = (aLine => {
//Look for a tilde and take everything prior to it, removeing non-letters
return aLine.Substring(0, aLine.IndexOf('~'))
.Where(c => char.IsLetter(c))
.Aggregate("", (p,c) => p + c);
});
List<string> worldCapHits = GetFileMatchesAgainstLetterSet(WORLD_CAPITALS_FILE,
calculatorLetterMap, extractPlaceFunc);
DisplayHits(worldCapHits, "World Capitals", calculatorLetterMap, txtResults);
//Finally, country names:
Func<string, string> extractCountryFunc = (aLine => aLine);
List<string> countryHits = GetFileMatchesAgainstLetterSet(COUNTRIES_FILE,
calculatorLetterMap, extractCountryFunc);
DisplayHits(countryHits, "Countries", calculatorLetterMap, txtResults);
}
/// <summary>
/// Loops through a file and returns a list of every entry which
/// can be composed solely with 'calculator letters'
/// </summary>
/// <param name="fName">The file containing things that might match</param>
/// <param name="calculatorLetterMap">List of letters derived from upside-down
/// calculator numbers</param>
/// <param name="extractPlaceFunc">Function to extract the item of interest
/// from each line in the file</param>
/// <returns></returns>
private static List<string> GetFileMatchesAgainstLetterSet(string fName,
List<Tuple<char, int>> calculatorLetterMap,
Func<string, string> extractPlaceFunc) {
List<string> result = new List<string>();
using (StreamReader sr = File.OpenText(fName)) {
while (sr.Peek() != -1) {
//Execute the Lambda provided by our caller:
string candidate = extractPlaceFunc(sr.ReadLine());
var leftOverLetters = candidate
.ToLower()
.Except(calculatorLetterMap.Select(m => m.Item1));
//If there are no leftover letters, we have a winner!
if (leftOverLetters.Count() == 0) {
string propperCase = char.ToUpper(candidate[0]) + candidate.Substring(1);
result.Add(propperCase);
}
}
}
return result;
}
/// <summary>
/// Displays every hit in the list with its equivalent in 'calculator letters'
/// </summary>
/// <param name="hitList">List if items to dispaly</param>
/// <param name="caption">Caption, such as 'State Capitals'</param>
/// <param name="calculatorLetterMap">List of letter/number pairs for translating</param>
/// <param name="txtResult">Textbox to hold the result</param>
private static void DisplayHits(List<string> hitList, string caption,
List<Tuple<char, int>> calculatorLetterMap, TextBox txtResult) {
txtResult.Text += caption + "\n";
foreach (string aHit in hitList) {
string number = MapLettersToCalculatorNumbers(aHit, calculatorLetterMap);
txtResult.Text += string.Format("\t{0} = {1}\n", number, aHit);
}
}
/// <summary>
/// Translates the puzzle answer ('candidate') back into 'Calculator letters'
/// </summary>
/// <param name="candidate">Such as 'boise' or 'benin' or 'lisbon'</param>
/// <param name="calculatorLetterMap">List of letter/number pairs</param>
/// <returns>A string composed of numerals</returns>
private static string MapLettersToCalculatorNumbers(string candidate,
List<Tuple<char, int>> calculatorLetterMap) {
string result = (from c in candidate
join m in calculatorLetterMap on c equals m.Item1
select m.Item2
).Aggregate("", (p, c) => p + c);
return result;
}
Download the code here: Puzzle Code
NPR Puzzle Solved: 3 Similar Names
That puzzle was the fastest solve ever, I had the whole thing done in less than an hour! Yee-haw! The funny thing is that, just last week, Will actually said that he designs the puzzles to be just as hard to solve manually as with code. But solving this one in code was so easy that perhaps Will didn’t understand what that means…
The Challenge
This week’s challenge comes from listener Matt Jones of Portland, Ore. There are three popular men’s names, each six letters long, that differ by only their first letters. In other words, the last five letters of the names are all the same, in the same order. Of the three different first letters, two are consonants and one is a vowel. What names are these?
Challenge URL: http://www.npr.org/2014/07/27/335590211/a-flowery-puzzle-for-budding-quizmasters

What You Will Learn from Reading!
- Improve your understanding of generic dictionaries in .NET
- Specifically, how dictionary entries can contain complex structures, such as lists
- String manipulation, specifically searching for substrings and extracting them from larger strings
- A sample use of a lambda expression, using the operator ‘Aggregate’, which I use to build a comma-delimited list from a list of string
Solving the Puzzle
I have a file of the to 1,219 most common boy’s names, and was able to use it to find the three forming the solution. Sorry, I don’t remember where I got it; I thought it was from the Census Bureau, but now I can’t find it on their site. Using that file,
- Build a dictionary to hold candidate names
- Open the file of names for reading
- Examine every name whose length is 6
- Extract the last 5 letters from each name
- Check if the dictionary already has a pre-existing entry, using the last 5 letters of each name as the key
- If so, append the current name to the dictionary entry
- Each entry in the dictionary is a list (because a dictionary can use any data type for the entries)
- But, if the dictionary lacks an entry identified by the current last 5 letters, add one now
- After loading the dictionary,
- Traverse all its entries
- If any entry has exactly 5 names in its list, we have a candidate!
- Check the vowel/consonant counts, if there are 2 consonants, we’ve got a winner
Here’s the heart of the code:
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Dictionary<string, List<string<< nameDic = new Dictionary<string, List<string<<();
//Open the file and read every line
using (StreamReader sr = File.OpenText(NAME_FILE)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//Sample lines looks like this:"DUSTIN 0.103 70.278 176"
// "JUSTIN 0.311 49.040 56"
// "AUSTIN 0.044 78.786 301"
//The name is position 1-15, the other columns are frequency counts and rank
//Locate the end of the name
int p = aLine.IndexOf(' ');
if (p == NAME_LEN) {
//grab the first 6 characters:
string aName = aLine.Substring(0, NAME_LEN);
//Now grab the last 5 letters of the name:
string last5 = aName.Substring(1);
//If we already have an entry (grouping) for the last 5 letters, add to the name list:
if (nameDic.ContainsKey(last5)) {
nameDic[last5].Add(aName);
} else {
//Start a new grouping using the last 5 letters as the key and the full name as the first strin entry
List<string< nameList = new List<string< { aName };
nameDic.Add(last5, nameList);
}
}
}
}
//Now find groups of names having length 3, such as 'Justin', 'Dustin', 'Austin'
foreach (KeyValuePair<string, List<string<< kvp in nameDic) {
if (kvp.Value.Count == 3) {
int vowelCount = 0;
int consonantCount = 0;
//Get the vowel/consonant counts of the first letters:
foreach (string aName in kvp.Value) {
//Binary search returns a non-negative value if it finds a match:
//In retrospect, a binary search is not appropriate for an array of size 5, but it doesn't hurt
if (Array.BinarySearch(vowels, aName[0]) <= 0)
vowelCount++;
else
consonantCount++;
}
//according to the rules, there should be 1 name starting with a vowel and 2 with consonants:
if (consonantCount == 2) {
//We can use a lambda expression to concatenate the list entries with commas
string combined = kvp.Value.Aggregate("", (p,c) =< p + ", " + c);
txtAnswer.Text += combined.Substring(2) + "\n";
}
}
}
}
I’ve posted the complete project here if you would like to download it. The code should run in Visual Studio 2010 or higher; you can use the free version of Visual Studio (“Express”) if you like. The data file is included in the zip folder; you can find it in the bin folder.
NPR Puzzle Solved: Actress From the Past
The Challenge
Name a famous actress of the past whose last name has 5 letters. Move the middle letter to the end to name another famous actress of the past. Who are these actresses?
Challenge URL
http://www.npr.org/2014/07/06/328876287/if-you-cut-in-the-middle-go-to-the-end-of-the-line
Summary
I downloaded every kind of actress list I could find (Romanian, Scottish, Khmer, actors who have played Elvis, actors who have played Santa Claus, yada, yada, yada,) After screen-scraping 109 different actor/actress lists, you can bet I was relieved that my code finally worked!
What You Could Learn Here
- .NET string manipulation techniques – useful for many tasks!
- Simple file I/O
- Simple dictionary usage

My Approach
- Read all the actress files, each in turn
- In every file, identify the last name for each actress
- Store the actress in a dictionary,
- Using the last name as the dictionary key
- And the full name as the value
- Now, iterate the dictionary,
- Manipulate the letters in each entry’s key, moving the middle letter to the end, to form a candidate
- For example, “garbo” → “gabor”
- If the dictionary contains a key matching the candidate, we have a solution!
- We check this using the dictionary method ‘ContainsKey’
Code That does the Magic!
Here is the code that does most of the work. It uses a subroutine ‘LoadActressFile’ to build the dictionary from a file.
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Dictionary<string, string> actressDic = new Dictionary<string, string>();
//Load all the text files in current folder
string[] allActressFiles = Directory.GetFiles(".", "*.txt");
foreach (string fName in allActressFiles) {
//If the file name contains 'Actress', proceed
if (Regex.IsMatch(fName, ".*?actress.*", RegexOptions.IgnoreCase)) {
LoadActressFile(actressDic, fName);
}
}
foreach (KeyValuePair<string, string> kvp in actressDic) {
//Combine the first 2 letters, then the last, then letters 2-3
string candidate = kvp.Key.Substring(0, 2)
+ kvp.Key.Substring(3)
+ kvp.Key.Substring(2, 1);
//For some actresses, when you manipulate their names,
//you get the same result, such as 'Foxxx' --> 'Foxxx', so ignore
if (candidate != kvp.Key) {
//Do we have a winner?
if (actressDic.ContainsKey(candidate)) {
//Append the result to the textbox:
txtAnswer.Text += kvp.Value + " - "
+ actressDic[candidate] + "\n";
}
}
}
}
Here is my method to load the dictionary, ‘LoadActressFile’
private static void LoadActressFile(Dictionary<string, string> actressDic, string fileName) {
using (StreamReader sr = File.OpenText(fileName)) {
while (sr.Peek() != -1) {
string anActress = sr.ReadLine();
//Find the last name, it is after the last space char:
int p = anActress.LastIndexOf(' ');
string lastName= anActress.Substring(p + 1).ToLower();
if (lastName.Length == 5) {
//If there is a duplicate key, append to existing value
if (actressDic.ContainsKey(lastName)) {
actressDic[lastName] += "," + anActress;
} else {
actressDic.Add(lastName, anActress);
}
}
}
}
}
Dictionaries are Fun!

- Dictionaries utilize hashing lookups for extreme efficiency
- This means I can check if ‘garbo’ is in the dictionary without looking at every entry, which would be slow!
- Dictionaries use brackets and a key to fetch a value out of the dictionary, like this:
- string anActress = actressDic[“garbo”];
- The key above is ‘garbo’. I used a string, but a variable containing ‘garbo’ also works.
- But, this would cause an error if there is no entry with a key of ‘garbo’!
- So, to avoid errors, you always test before retrieving with a key:
- if (actressDic.ContainsKey(“garbo”)) { … }
- To add to a dictionary, use the ‘Add’ method and provide a key and a value, like this:
- actressDic.Add(“gabor”, “Eva Gabor”);
- If the dictionary already has a key ‘garbo’, that would cause an error. Keys must be unique!
- So, when building the dictionary, if I find a collision, I append the second actress to the pre-existing value
-
-
if (actressDic.ContainsKey(lastName)) { //Append the new actress to the existing entry: actressDic[lastName] += "," + anActress; } else { actressDic.Add(lastName, anActress); }
-
Summary
Once you have the correct list of actresses, solving is a simple matter of string manipulation and checking if your manipulation results in another last name.
NPR Puzzle Solved: June 29, 2014
The Challenge:
This week’s challenge comes from Steve Baggish of Arlington, Mass., the father of the 11-year-old boy who created the challenge two weeks ago. Name a boy’s name and a girl’s name, each in four letters. The names start with the same letter of the alphabet. The boy’s name contains the letter R. Drop that R from the boy’s name and insert it into the girl’s name. Phonetically, the result will be a familiar two-word phrase for something no one wants to have. What is it?
Challenge URL
Link to the Sunday Puzzle
Overview
This was kind of interesting: even though my code won’t yield an exact solution, I was still able to produce a short list of potential solutions and then manually pick the best answer from that list. Main problem: the English language does not have simple pronunciation rules! I am using the Soundex algorithm to compare the pronunciation of phrases against words I construct (from boy/girl names), and the Soundex algorithm is only an approximation. Among its many drawbacks, Soundex doesn’t account for differences in vowel pronunciation. Creating your own replacement for Soundex is a lot of work, email me if you have a better way!
The soundex algorithm is a very useful algortithm; if you read this article, you will learn one good way to use it. You can download implementations of the algorithm from many places; I think I got my version from the Code Project. I have a link below to its description on Wikipedia.
You can also learn from my examples using Linq and .NET Dictionaries, both very useful tools to master!
Solution

Algorithms I Used
Soundex Algorithm for Mapping Pronunciation
The Soundex function takes a string for input and generates a number that corresponds to the pronunciation. Words that sound alike have similar soundex values. For example,
- Soundex(“Robert”) == R163
- Soundex(“Rupert”) == R163
- Soundex(“Rubin”) == R150
- Since Robert sounds a lot like Rubert, both names have the same soundex value.
- As you can see, the soundex algorithm is just an approximate way to match similar words; according to soundex, “bated” sounds the same as as “bad” (because they both have the same soundex value of B300)
In my solution (explained below), I manipulate boy/girl names to construct candidate solutions. If my two candidate names have the same soundex values as a common phrase, then I know that boy and girl might be the answer I seek.
You could use the Soundex algorithm for a customer service app, when the customer talks with marbles in their mouth and your users need to quickly find possible spellings for what customer is telling them!
Levenshtein Distance for Measuring String Similarity
The Levenshtein Distance indicates the similarity of two strings. The modified algorithm I used, computes a distance between 0 and 100; when the distance is 100, the two strings have nothing in common, when their distance is 0, they are identical. The lower the number, the more similar. For example,
- LevenshteinDistance(“kitten”, “kitting”) == 28
- LevenshteinDistance(“kitten”, “sitting”) == 42
- ImprovedLevenshteinDistance(“kitten”, “asdf”) == 100
Thanks to Sten Hjelmqvist for his improved implementation of the Levenshtein altorithm, which you can download here: Code Project Article by Sten.
Why do I need the Levenshtein distance? Because the soundex algorithm is an imperfect mapping. For example, “Bated breath” and “bad breath” have the same soundex scores. But, by using Levenshtein, whenever to phrases have the same soundex score, I can pick the phrase which is closest to the original words. In this case, “BadBreth” is closer to “bad breath” than “bated breath”, because the the Levenshtein distance is smaller.
Sten uses Levenshtein distance to judge how much web pages have changed; apparently he crawls a lot of sites and needs to know who has been updated a lot.
Data
I got a list of boy and girl names from government web site a few years ago and now I can’t find the link. It might have been from the census bureau. If anyone wants a copy of my name files, leave a comment with your email and I can send them.
I got the list of phrases from various web sites and built my own list, using regular expressions and screen scraping techniques that I have explained in previous articles. Again, if anyone wants a copy of my list, leave a comment with your email.
My Approach
- Build a dictionary ‘phraseSoundexPairs’ containing:
- For dictionary value, use Phrases . Per puzzle instructions, only use 2-word phrases where each word has length == 4
- For the dictionary entry keys, use the Soundex values of the two words
- For example, the dictionary entry for “bad breath” will receive a key of “B300B630”, where B300 is the soundex of “bad” and B630 is the soundex of “breath”.
- Why did I construct my key this way? Because I can easily determine if any a candidate boy/girl matches (based on soundex) the pronunciation of any phrase in the dictionary. If the candidate soundex does not match any dictionary keys, then I know it is not a solution.
- Find all the boy names with length 4, make a list
- Find all the girl names with length 4, make a list
- Using Linq, join (match) the two lists on their first letters, rejecting any boy names that don’t contain the letter ‘r’
- Now, iterate the result of the join above
- For each match, remove the r from the boy and insert it into the girl’s name (there are 5 possible positions to insert it)
- For example, manipulate “brad” –> “bad”, “beth” –> “rbeth”, “breth”, “berth”, “betrh”, “bethr”
- Compute the soundex for the manipulated boy/girl name and check if it is in the dictionary. If so, we have a possible solution!
-
- Soundex(“bad”) == B300
- Soundex(“breth”) == B630
- Candidate key –> “B300B630”
- My dictionary has a matching key!
- phraseSoundexPairs[“B300B630”] == “bad breath”, telling us we have the solution!
- Since my dictionary actually has several entries with similar soundex values, use the Levenshtein distance to find the best among those similar entries.
- For example, “bated breath” and “bad breath” both have the same soundex scores, but the Levenshtein distance is better for “bad breath”
The Top-Level Code
Take a look at the top-level code that solves the puzzle and writes the answer to a textbox named ‘tbAnswer’:
private void btnSolve_Click(object sender, RoutedEventArgs e) {
tbAnswer.Clear();
//Load the boy and girl names into the list, restricting them to length 4:
List<string> boyList = LoadNameFile(
DATA_FOLDER + BOY_FILE, NAME_LENGTH);
List<string> girlList = LoadNameFile(
DATA_FOLDER + GIRL_FILE, NAME_LENGTH);
//Build a dictionary containing value= phrases, key=soundex scores
Dictionary<string, string> phraseSoundexPairs
= BuildSoundex_PhraseDictionary();
//Join the two lists on their first letters:
var namePairs = from b in boyList join g in girlList
on b.Substring(0, 1) equals g.Substring(0, 1)
where b.Contains('r') &&
b.Length == 4 &&
g.Length == 4
select new { Boy = b, Girl = g };
//Iterate the joined result and construct candidate soundex values:
foreach (var aPair in namePairs) {
string boyName = aPair.Boy.Replace("r", "");
string boySoundex = PuzzleHelper.Soundex(boyName);
//There are 5 ways to construct each girl name,
//because there are 5 places to insert the 'r'
for (int p = 0; p < 5; p++) {
string girlName = aPair.Girl.Insert(p, "r");
string girlSoundex = PuzzleHelper.Soundex(girlName);
//Check if we have a dictionary entry composed
//of both soundex values
if (phraseSoundexPairs.ContainsKey(boySoundex + girlSoundex)) {
//Use Levenstein distance to find the best match
//if multiple are present:
string closestPhrase = ClosestMatchFromCSVEntries(
phraseSoundexPairs[boySoundex + girlSoundex],
boyName + girlName);
tbAnswer.Text +=
string.Format
("Phrase: {0}/Boy:{1} Girl: {2} (Manipulated boy: {3}, Manipulated girl:{4})\n",
closestPhrase, aPair.Boy, aPair.Girl, boyName, girlName);
break;
}
}
}
}
Finding the Closest Match using Levenshtein Distance
This method takes an entry from the dictionary and splits it on commas. (Because when I have multiple phrases with the same soundex value, I append the new phrase using a comma to separate them.) Using Linq, I make a list of anonymous type containing the distance and the phrase, then choosing the first entry from that list, which has the lowest distance.
private string ClosestMatchFromCSVEntries(string csvPhrases, string combinedName) {
var distList = from p in csvPhrases.Split(',')
select new {
dist = PuzzleHelper.ImprovedLevenshteinDistance(combinedName, p),
Phrase = p };
return (from p in distList
orderby p.dist
select p
).First().Phrase;
}
Notes: Loading the Name Lists and Building the Dictionary
I don’t bother to explain function “LoadNameFile”; you should find it pretty easy to load the boy/girl names from file and construct a list; I only used simple C# IO methods. For examples, please refer to some of my previous puzzle solutions. Constructing the dictionary is a little bit tricker, only because of how I handle duplicate keys. It is easier just to display the code:
private static Dictionary<string, string> BuildSoundex_PhraseDictionary() {
Dictionary<string, string> result = new Dictionary<string,string>();
using (StreamReader sr = File.OpenText(DATA_FOLDER + PHRASE_FILE)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine().ToLower().Trim();
//Look for phrases containing exactly 1 space,
//ie. 2-word phrases
if (aLine.Where(c => c == ' ').Count() == 1) {
int p = aLine.IndexOf(' ');
string word1 = aLine.Substring(0, p);
string word2 = aLine.Substring(p + 1);
if (PuzzleHelper.AllLettersAreAlpha(word1 + word2)) {
string soundex = PuzzleHelper.Soundex(word1)
+ PuzzleHelper.Soundex(word2);
//The only tricky part: if two phrases have the same
//soundex, then append the second phrase after a comma:
if (result.ContainsKey(soundex)) {
result[soundex] += ", " + aLine;
} else {
result.Add(soundex, aLine);
}
}
}
}
}
return result;
}
Alternative Solution
I am not totally happy with this approach, due to difficulties with pronouncing English words, as discussed above. I considered using my list of common words mapped to their phonemes, which I downloaded from Carnegie Mellon University. (A phoneme is a way to pronounce a single syllable; the list of Phonemes for English consists of every possible sound we use in our common language.) That approach would have had the advantage of mapping words onto a value one-to-one. That would eliminate any duplicates from my list. Unfortunately, that list does not have any mappings for imaginary words like ‘breth’, so I can’t use it.
Summary
I hope you enjoyed this solution; Soundex has a number of uses, as does the Levenshtein distance. If you can use either of these in your code, leave a comment to that effect! I also hope you enjoyed my simple example of using Linq to join the list of boys and girls, I found that particular piece of code rather pleasing.
Solved the NPR Sunday Puzzle from June 1, 2014
The Challenge
This challenge comes from listener Dan Pitt of Palo Alto, Calif. Take the name of a well-known American businessman — first and last names. Put the last name first. Insert an M between the two names. The result names a food item. What is it?
Challenge URL: http://www.npr.org/2014/06/01/317697851/getting-to-know-the-in-crowd
Facing the Challenge
Writing the code to solving this one was simple; the real challenge was getting the right data to solve! For some reason, businessmen don’t get much attention on Wikipedia or other sites. Wikipedia has lists of chefs, dentists, copyrighters, etc. but no list of businessmen! I was able to find a list of Entrepreneurs and CEOs, but those are not quite the same thing. Fortunately, the two lists were sufficient to solve the puzzle.
Likewise, finding the foods was not too easy, mainly because I found a huge list at USDA, but said list turned-out to be a list of processed foods that did not include the answer. Fortunately, I was able to solve using the next place I looked for foods, namely, a list of fruits from Wikipedia. I guess USDA doesn’t need to list fruits on their web site.
Nonetheless, it was quite satisfying to solve the puzzle!

Code to Solve the Puzzle, Given that the Data is Available
Let’s jump right into the guts of the issue, solving the puzzle. First, here is the code to test if a given name is a solution.
//This method will return true if fullName can be manipulated to match a key
//in the food dictionary, and will set the output variable 'answer'
public bool NameIsASolution(string fullName,
Dictionary<string, string> foodDic, out string answer) {
answer = string.Empty;
//Only look at names that have at least one space, i.e. a first and last name
if (fullName.Contains(' ')) {
//Get the first and last name, using the
//positions of the first and last space in the name
string firstName = fullName.Substring(0, fullName.IndexOf(' '));
int p = fullName.LastIndexOf(' ');
string lastName = fullName.Substring(p + 1, fullName.Length - p - 1);
//Reverse the last and first names, while
//inserting the letter 'm'
string candidate = lastName + 'm' + firstName;
//The dictionary uses hashing technology to efficiently
//tell us if the candidate is a key in it:
if (foodDic.ContainsKey(candidate)) {
answer = foodDic[candidate];
}
return foodDic.ContainsKey(candidate);
} else {
return false;
}
}
Note:
- We identify the first name (if present) using IndexOf(‘ ‘)
- In other words, find the first space in the name
- We identify the last name using LastIndexof(‘ ‘)
- Which won’t work if a name ends with “Jr.”, but we don’t care for this puzzle
- The dictionary has already been constructed to strip-out spaces and punctionation in the key
- But each value contains the original, unmanipulated fruit name
The code above gets called for every entry in two files:
- BUSINESSMAN_FILE
- CEO_FILE
Why two files? Because I elected to save the businessmen in a different format, including their country and area of specialization. So processing each line in the file requires slightly more work, to extract just the name from each line. In contrast, the food and CEO files list a simple name on each line.
Here is the code that fires when user clicks the button to solve the puzzle:
private void btnSolve_Click(object sender, RoutedEventArgs e) {
//The original food name is the value, the key is the food in lower case with no spaces or punctuation
Dictionary<string, string> foodDic = new Dictionary<string, string>();
using (StreamReader sr = File.OpenText(FOOD_FILE)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//Use Linq to get only letters (the Where-clause) and then reassemble
//them from char to string (the Aggregate clause)
string aKey = aLine
.ToLower()
.Where(c => c >= 'a' && c <= 'z')
.Aggregate("", (p, c) => p + c);
if (!foodDic.ContainsKey(aKey)) {
foodDic.Add(aKey, aLine);
}
}
}
//Process each line in the businessman file
string answer = string.Empty;
using (StreamReader sr = File.OpenText(BUSINESSMAN_FILE)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//The full name is all the text preceding the first tab:
string fullName = aLine.Substring(0, aLine.IndexOf('\t'));
if (NameIsASolution(fullName.ToLower(), foodDic, out answer)) {
txtAnswer.Text += answer + "<-->" + fullName + "\n";
stbMessage.Text = "Solved!";
}
}
}
//Now process each line in the CEO file:
using (StreamReader sr = File.OpenText(CEO_FILE)) {
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
if (NameIsASolution(aLine.ToLower(), foodDic, out answer)) {
txtAnswer.Text += answer + "<-->" + aLine + "\n";
stbMessage.Text = "Solved!";
}
}
}
}
As you can see, the code above
- Opens the food file and builds a dictionary with the contents
- Opens the businessmen file, finds the name on each line, and tests it to see if it is a solution
- Does the same thing for the CEO file
Getting the Data
If you have read my blog before, you know that I generally adopt the same approach:
- Go to a URL with a .NET WebClient
- Download the html via the OpenRead method
- Identify the data using a regular expression
- Save the regular expression matches to a file
You can read one of my other blog entries to get the code for that technique; today I will just list the regular expression that I used for each URL.
| URL | Regex |
|---|---|
| http://en.wikipedia.org/ wiki/List_of_chief_executive_officers | <li><a #Literal [^>]+ #Anything but > > #Literal ([^<]+) #Capture group, anything but < </a> #Literal ( #Start capture group \s* #Whitespace \( #Escaped parenthesis [^)]+ #Anything but ) \), #Escaped parenthesis, comma )? #End capture group, optional ([^<]+)? #Start capture group, anything but <, optional </li> #Literal |
| http://en.wikipedia.org/ wiki/ List_of_fruits |
<span #Literal \s+ #Whitespace id=” #Literal ([^”]+) #Capture group, anything but quote ” #Literal |
| http://en.wikipedia.org/wiki/List_of_chief_executive_officers | <tr> #Literal \r?\n? #Optional carriage return linefeed <td><a #Literal [^>]+ #Anything but > > #Literal .*? #Anything, lazy match </a></td> #Literal match \r?\n? #Optional carriage return linefeed <td><a #Literal [^>]+ #Anything but > > #Literal ([^<]+) #Capture Group, anything but < </a></td> #Literal match |
| http://ndb.nal.usda.gov/ndb/foods | <a #Literal \s+ #Whitespace href=”/ndb/foods/show #Literal [^>]+ #Anything but > > #Literal ([^<]+) #Capture group, anything but < </a> #Literal \r?\n? #Optional carriage return linefeed \s+ #Whitespace </td> #Literal |
Summary
Use regular expressions to capture the data from web sites. Use string manipulation to reverse the businessman name and inject the letter ‘M’. Build a dictionary of foods using the food name as the key. For each manipulated businessman name, test if the dictionary contains that value as a key; if so, we have a winner!
Body Parts From Literary Character – NPR Puzzle!
The Challenge:
This week’s challenge comes from listener Steve Baggish of Arlington, Mass. Name a title character from a classic work of fiction, in 8 letters. Change the third letter to an M. The result will be two consecutive words naming parts of the human body. Who is the character, and what parts of the body are these?
Link to the puzzle: http://www.npr.org/2014/02/09/273644645/break-loose-break-loose-kick-off-your-sunday-shoes

Satisfying, But Complex!
I was able to solve this one with
- A list of book titles I previously harvested from http://www.goodreads.com
- A list of boy and girl names I got from the census bureau a long time ago (sorry, can’t find the exact link)
- Various lists of body parts I scraped from some English Vocabulary sites, such as http://www.enchantedlearning.com/wordlist/body.shtml
- A list of English words I got from puzzlers.org
- A list of prepositions I got from http://www.englishclub.com/grammar/prepositions-list.htm
The Algorithm
The hard part was identifying names from my book list, especially when you consider that the winner is no longer a common name, even though he is featured in the title of three books. Many more book characters are not common names! The basic idea is to examine the list of books and consider, as a name candidate, any words that meet the following criteria:
- If it is used in a possessive, such as “Charlotte’s Web”
- Or if it is found in our first-name list (boys and girls), and has 8 letters
- Or if it is a word pair, starting with an entry in our first-name list
- Or if the length of the title is exactly 8 letters, excluding spaces, hyphens, like “Jane Eyre”
- Finally, if it is a word or word pair preceded by a preposition, such as “Flowers for Algernon”
Once we have the list of candidate names, we compare them against our list of body parts. After, of course, substituting ‘m’ for the 3rd character.
The shortest body part in my list has length 3; each literary name has length 8. We also know, from Will’s directions, that the two body-part words are consecutive. Therefore, each literary name can be split three different ways, which we perform with a loop htat splits the name into 3 candidates, such as
- gum/liver
- guml/iver
- gumli/ver
I elected to store my books and associated names in a dictionary; the name (e.g. ‘gulliver’) will be my key, while the value will be the book title. You can loop through a .NET dictionary using a for-each loop, and each entry will be a KeyValuePair, in my case, using string data type for the key and string data type for the value.
For each dictionary pair (name/book title), split the name, and if we can find both resulting words in our body parts list, we have a winner! As discussed above, there are 3 ways to split each name.
Code Snippet for the Win
//Loop through the dictionary 'characterDic'; each entry is a name (the key) and a value (book title)
foreach (KeyValuePair<string, string> kvp in characterDic) {
//replace 3th letter with 'M',
//for example 'gulliver' --> 'gumliver'
string theCharacter = kvp.Key.Substring(0, 2)
+ "m" + kvp.Key.Substring(3);
//Chop theCharacter at several points to see
//if they might be body parts
for (int divPt = 3; divPt <= 5; divPt++) {
string word1 = theCharacter.Substring(0, divPt);
string word2 = theCharacter.Substring(divPt);
//Check if both words are found in our body
//parts list using BinarySearch
//Binary search returns an index, which will be
//greater or equal to zero, where the search item was found
if (bodyPartsList.BinarySearch(word1) >= 0
&& bodyPartsList.BinarySearch(word2) >= 0) {
//Append the two words, plus the book
//title(s) to the text box for ansers
txtAnswers.Text += word1 + "+" + word2 + " ? " + kvp.Value + "\n";
}
}
}
Notes
- Binary search is very fast (it runs in O(Log(n)) time; I could have used a dictionary for even more speed but my lists aren’t that big. As noted above, when you run a .NET binary search, it returns the index of the entry if it finds what you searched for.
- I used a dictionary for the characters and their associated title characters, not for the speed, but because it offers a convenient way to store a pair and avoid duplicates. As you probably noticed from my solution screen shot, ‘Gulliver’ is the title character in 3 books
- To handle that, I elected to use ‘Gulliver’ for the dictionary key, when I found other books with the same title character, I simply appended the new book name to the entry whose key is ‘Gulliver’
Code Listing
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Input;
using System.IO;
using System.Text.RegularExpressions;
namespace Feb_9_2014 {
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window {
private const string BOOK_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\CleanedBookList.txt";
private const string BODY_PARTS_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\BodyPartsList.txt";
private const string BOY_NAME_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\CommonBoyNames.txt";
private const string GIRL_NAME_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\CommonGirlNames.txt";
private const string PREPOSITION_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\EnglishPrepositions.txt";
private const string WORD_LIST
= @"C:\Users\Randy\Documents\Puzzles\Data\web2.txt";
//links to body parts list:
//http://www.ego4u.com/en/cram-up/vocabulary/body-parts
//http://www.enchantedlearning.com/wordlist/body.shtml
//Booklist from http://www.goodreads.com
public MainWindow() {
InitializeComponent();
}
/// <summary>
/// Fired when user clicks the Solve button
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
//Build a unique list of names from the census list of first names:
List<string> firstNameList = new List<string>();
AugmentNameListFromFile(BOY_NAME_LIST, firstNameList);
AugmentNameListFromFile(GIRL_NAME_LIST, firstNameList);
//Most of the work is done here, creating potential
//character names from m list of books
Dictionary<string, string> characterDic
= Build8LetterCharcterList(firstNameList);
List<string> bodyPartsList = BuildBodyPartsList();
//Now use our list of potential character names
//and the body parts list to solve:
foreach (KeyValuePair<string, string> kvp in characterDic) {
//replace 3th letter with 'M',
//for example 'gulliver' --> 'gumliver'
string theCharacter = kvp.Key.Substring(0, 2)
+ "m" + kvp.Key.Substring(3);
//Chop theCharacter at several points to see
//if they might be body parts
for (int divPt = 3; divPt <= 5; divPt++) {
string word1 = theCharacter.Substring(0, divPt);
string word2 = theCharacter.Substring(divPt);
//Check if both words are found in our body
//parts list using BinarySearch
//Binary search returns an index, which will be
//greater or equal to zero, where the search item was found
if (bodyPartsList.BinarySearch(word1) >= 0
&& bodyPartsList.BinarySearch(word2) >= 0) {
//Append the two words, plus the book
//title(s) to the text box for ansers
txtAnswers.Text += word1 + "+" + word2 + " ? " + kvp.Value + "\n";
}
}
}
Mouse.OverrideCursor = null;
}
/// <summary>
/// Reads a file, finds the boy/girl name at position 1-15,
/// and adds to the list if not already present
/// </summary>
/// <param name="fName">File Name containing boy/girl names</param>
/// <param name="firstNameList">List to augment</param>
/// <remarks>
/// The list we build will be sorted by virtue of how we insert new names
/// </remarks>
private void AugmentNameListFromFile(string fName, List<string> firstNameList) {
using (StreamReader sr = File.OpenText(fName)) {
while (sr.Peek() != -1) {
string aName = sr.ReadLine().ToLower().Substring(0, 15).TrimEnd();
int p = firstNameList.BinarySearch(aName);
if (p < 0) {
//When p < 0, it means the name is not present in the list
//Also, when we invert p, that becomes the index where
//it belongs to keep the list sorted
firstNameList.Insert(~p, aName);
}
}
}
}
/// <summary>
/// Builds a dictionary of character names (8 letters long)
/// and the book titles they are found in
/// </summary>
/// <param name="firstNameList">List of fist names</param>
/// <returns>The dictionary</returns>
/// <remarks>
/// We will consider a word a name if
/// 1) it is used in the possessive, such as "Charlotte's Web"
/// 2) It is found in our first-name list and has 8 letters
/// 3) It is a word pair starting with an entry in our first-name list
/// 4) The length of the title is 8 letters,
/// excluding spaces, hyphens, like Jane Eyre
/// 5) It is a word or word pair preceded by a preposition,
/// such as Flowers for Algernon
/// </remarks>
private Dictionary<string, string> Build8LetterCharcterList(List<string> firstNameList) {
Dictionary<string, string> result = new Dictionary<string, string>();
//the word list will contain almost every English
//word that is not in our firstname list
List<string> wordList = BuildWordList(firstNameList);
//A list of 50 words like to/as/for
List<string> prepositionList = BuildPrepositionList();
//This Regular expression will detect 8 (or 9 with a space)
//letter words followed by apostrphe s
Regex rePossive = new Regex(@"
( #start capture group
\b #Demand a word break
[A-Za-z\s] #any letter a-z, lower or upper case, plus space
{8,9} #The preceeding must have length 8 or 9
\b #demand another word break
) #close our capture group
's #demand apostrphe s",
RegexOptions.Multiline | RegexOptions.IgnorePatternWhitespace);
//Loop through the book list and see if each title
//matches any of the listed conditions
//Each method will add to the dictionary using the
//character name as the key and the title as the value
using (StreamReader sr = File.OpenText(BOOK_LIST)) {
while (sr.Peek() != -1) {
string title = sr.ReadLine();
CheckPossive(title, rePossive, result, wordList);
Check8LetterNames(firstNameList, result, title);
CheckFullTitle(title, result);
CheckPreposition(title, prepositionList, wordList, result);
}
}
return result;
}
/// <summary>
/// Opens the WORD_LIST file and adds every entry which
/// is not found in the list of first names
/// </summary>
/// <param name="firstNameList">Sorted list of first names</param>
/// <returns><The list of words/returns>
/// <remarks>
/// The word list is useful to reject potential character names
/// which might be a common English word
/// </remarks>
private List<string> BuildWordList(List<string> firstNameList) {
List<string> result = new List<string>();
using (StreamReader sr = File.OpenText(WORD_LIST)) {
while (sr.Peek() != -1) {
string aWord = sr.ReadLine().ToLower();
if (firstNameList.BinarySearch(aWord) < 0) {
result.Add(aWord);
}
}
}
return result;
}
/// <summary>
/// Builds a list of prepositions (string) from the file
/// PREPOSITION_LIST, which is already sorted
/// </summary>
/// <returns>The list of words</returns>
private List<string> BuildPrepositionList() {
List<string> result = new List<string>();
using (StreamReader sr = File.OpenText(PREPOSITION_LIST)) {
while (sr.Peek() != -1) {
result.Add(sr.ReadLine());
}
}
return result;
}
/// <summary>
/// Examines every word in the specified title to determine
/// if it matches the possive form (and have 8-9 characters)
/// </summary>
/// <param name="title">A book title to search</param>
/// <param name="rePossive">A regular expression that will
/// match a possessive form</param>
/// <param name="characterTitleDic">Dictionary to add results to</param>
/// <param name="wordList">List of english words to exclude</param>
private void CheckPossive(string title, Regex rePossive,
Dictionary<string, string> characterTitleDic,
List<string> wordList) {
Match m = rePossive.Match(title);
if (m.Success) {
string candidate = m.Groups[1].Value.ToLower().Trim().Replace(" ", "");
if (candidate.Length == 8 && wordList.BinarySearch(candidate) < 0) {
if (characterTitleDic.ContainsKey(candidate)) {
characterTitleDic[candidate] += ", " + title;
} else {
characterTitleDic.Add(candidate, title);
}
}
}
}
/// <summary>
/// Examines the specified title to see if any words could
/// be an 8-letter first name or else a first name followed
/// by any other word when the pair has a combined length of 8
/// </summary>
/// <param name="firstNameList">List of first names</param>
/// <param name="characterTitleDic">List to add the result to</param>
/// <param name="title">Book title that might contain names</param>
/// <remarks>
/// We could have a hit under two conditions:
/// 1) We find an 8-letter name in the title, such as 'JONATHAN'
/// 2) We find a name of any length followed by another word,
/// such as 'Jane Eyre', the two having a combined
/// length of 8
/// </remarks>
private void Check8LetterNames(List<string> firstNameList,
Dictionary<string, string> characterTitleDic, string title) {
string[] words = title.ToLower().Split(' ');
for (int i = 0; i< words.Length; i++) {
string aWord = words[i];
//Check case 1, 8 letter names
if (aWord.Length == 8 && firstNameList.BinarySearch(aWord) >= 0) {
if (characterTitleDic.ContainsKey(aWord)) {
characterTitleDic[aWord] += ", " + title;
} else {
characterTitleDic.Add(aWord, title);
}
} else if (i < words.Length - 1
&& firstNameList.BinarySearch(aWord) > 0) {
//Case two, we have a first name followed
//by another name with total length of 8
if (aWord.Length + words[i + 1].Length == 8) {
string candidate = aWord + words[i+1];
if (candidate.Length == 8) {
if (characterTitleDic.ContainsKey(candidate)) {
characterTitleDic[candidate] += ", " + title;
} else {
characterTitleDic.Add(candidate, title);
}
}
}
}
}
}
/// <summary>
/// We will identify any titles having length 8 (excluding
/// spaces) and add them to the dictionary
/// </summary>
/// <param name="title">A book title</param>
/// <param name="characterTitleDic">Where we store hits</param>
/// <remarks>
/// For example, 'Jane Eyre'
/// </remarks>
private void CheckFullTitle(string title,
Dictionary<string, string> characterTitleDic) {
string candidate = title.Replace(" ", "").ToLower();
if (candidate.Length == 8) {
if (characterTitleDic.ContainsKey(candidate)) {
characterTitleDic[candidate] += "," + title;
} else {
characterTitleDic.Add(candidate, title);
}
}
}
/// <summary>
/// Identify 8-letter words following a preposition
/// that are not common English words
/// </summary>
/// <param name="title">A book title</param>
/// <param name="prepositionList">List of prepositions</param>
/// <param name="wordList">List of English words
/// that are not first names</param>
/// <param name="characterTitleDic">Dictionary to
/// augment with hits</param>
/// <remarks>
/// Sample: 'A Ball for Daisy'. 'for' is the preposition,
/// 'Daisy' is the word that follows.
/// </remarks>
private void CheckPreposition(string title, List<string> prepositionList,
List<string> wordList, Dictionary<string, string> characterTitleDic) {
string[] words = title.ToLower().Split(' ');
for (int i = 0; i < words.Length; i++) {
string aWord = words[i];
if (prepositionList.BinarySearch(aWord) > 0
&& i < words.Length - 1
&& words[i+1].Length == 8
&& wordList.BinarySearch(words[i+1]) < 0) {
if (characterTitleDic.ContainsKey(words[i + 1])) {
characterTitleDic[words[i + 1]] += ", " + title;
} else {
characterTitleDic.Add(words[i + 1], title);
}
}
}
}
/// <summary>
/// Builds a string list from the body parts in the
/// file BODY_PARTS_LIST, which is already sorted
/// </summary>
/// <returns>The sorted list</returns>
private List<string> BuildBodyPartsList() {
List<string> result = new List<string>();
using (StreamReader sr = File.OpenText(BODY_PARTS_LIST)) {
while (sr.Peek() != -1) {
result.Add(sr.ReadLine().ToLower());
}
}
return result;
}
}
}
Now, the XAML
<Window x:Class="Feb_9_2014.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Title Character to Body Parts" Height="350" Width="725"
WindowStartupLocation="CenterScreen"
Icon="/Feb_9_2014;component/Images/Book.jpg">
<Grid>
<Grid.Background>
<ImageBrush Opacity=".3"
ImageSource="/Feb_9_2014;component/Images/gullivers600x390.jpg" />
</Grid.Background>
<Grid.RowDefinitions>
<RowDefinition Height="auto" />
<RowDefinition Height="auto" />
<RowDefinition />
</Grid.RowDefinitions>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="auto" />
<ColumnDefinition Width="auto" />
<ColumnDefinition />
</Grid.ColumnDefinitions>
<Border Grid.ColumnSpan="3">
<Border.Background>
<LinearGradientBrush EndPoint="0.5,1" StartPoint="0.5, 0">
<GradientStop Color="Black" Offset="0" />
<GradientStop Color="#FFD5CCC0" Offset="1" />
</LinearGradientBrush>
</Border.Background>
<TextBlock HorizontalAlignment="Center" FontSize="36"
Foreground="Chartreuse"
Text="Title Character Plus M ? 2 Body Parts">
<TextBlock.Effect>
<DropShadowEffect />
</TextBlock.Effect>
</TextBlock>
</Border>
<TextBlock Grid.Row="1" Grid.ColumnSpan="3" FontSize="14"
TextWrapping="Wrap" Margin="3" >
This week's challenge comes from listener Steve Baggish of
Arlington, Mass. Name a title character from a classic work
of fiction, in 8 letters. Change the third letter to an M.
The result will be two consecutive words naming parts
of the human body. Who is the character, and what parts
of the body are these?
</TextBlock>
<Button Grid.Row="2" Content="_Solve" Name="btnSolve"
Height="30" VerticalAlignment="Top" Margin="5 0"
Click="btnSolve_Click" FontSize="14" FontWeight="Black" />
<Label Grid.Row="2" Grid.Column="1" Content="_Answer:"
Target="{Binding ElementName=txtAnswers}" FontWeight="Bold" />
<TextBox Grid.Row="2" Grid.Column="3" Name="txtAnswers"
AcceptsReturn="True" TextWrapping="Wrap"
Background="Transparent" FontWeight="Bold"
FontSize="16"/>
</Grid>
</Window>
That’s all!
Puzzle Victory – Word Synonym Pair/Remove Double-S
The challenge:
What word, containing two consecutive S’s, becomes its own synonym if you drop those S’s?
Link to the challenge: http://www.npr.org/2014/01/26/266210037/take-synonyms-for-a-spin-or-pirouette

Fun With Linq!
Since I had a nice synonym list already, I was able to dive into this one and come up with an elegant solution using a couple lines of Linq (Language INtegrated Query). “Linq” is Microsoft’s built-in query language that allows you process all kinds of lists and a lot more.
Sorry, faithful readers, I don’t remember exactly where I got my synonym list, but you can get a similar list here, even it is formatted differently than mine.
Algorithm
The following code snippet analyzes a single line from my file and puts the result into the variable ‘answer’ if a solution is found. It does almost all the work, yet takes only six lines. A detailed explanation follows, but if you examine it closely, you should be able to figure-out most of it:
var answer = from word1 in aLine.Split('|')
let wp = new { Original = word1, WordNoSS = word1.Replace("ss", "") }
join word2 in aLine.Split('|') on wp.WordNoSS equals word2
where word1.Contains("ss")
&& !distinctAnswers.Contains(word1)
select wp;
Detailed Explanation
- Open the synonym file fore reading, using a stream reader named ‘sr’
- Each line contains synonyms, separated by a pipe character, like this:
- bloom|blossom|flower|flourish|coloration
- Within a Linq query, split every line from the file on the | character,
- Into an array,
- Name each array entry ‘word1’
- Use the Linq ‘where’ operator to select only entries in the array containing ‘ss’
- Join the first Linq query against another query
- Which we build by again splitting the line, referring to its entries as ‘word2’
- If the join operation has any match whatsoever,
- Then we have a potential solution
- But reject any answer we have already discovered, by comparing current against previous entries from a list called ‘distinctAnswers’
- If our potential answer is not in the list, display the answer, and add it to the distinctAnswers list
Here’s the entire code listing
using System;
using System.Collections.Generic; //For my list (of word pairs)
using System.Windows;
using System.IO; //To open synonyms file
using System.Windows.Input; //To display hourglass while waiting
using System.Linq;
namespace Jan26_2014 {
/// <summary>Code to solve the puzzleThe buttonEvent args();
/// <summary>Code to solve the puzzle</summary>
/// <remarks>
/// Solution loads a list of synonyms from a file
/// Each line has several synonyms on it, separated by |
/// Use split the line into an array of words and use linq on it.
/// Linq provides an elegant solution that is also pretty efficient.
/// </remarks>
public partial class MainWindow : Window {
private const string SYNONYM_FILE =
@"C:\Users\Randy\Documents\Puzzles\Data\Synonyms.txt";
/// <summary>Default constructor</summary>
public MainWindow() {
InitializeComponent();
}
/// <summary>
/// Fires when user clicks the Solve button
/// </summary>
/// <param name="sender">The button</param>
/// <param name="e">Event args</param>
private void btnSolve_Click(object sender, RoutedEventArgs e) {
Mouse.OverrideCursor = Cursors.Wait;
txtAnswer.Clear();
//Open the file for reading
using (StreamReader sr = File.OpenText(SYNONYM_FILE)) {
//Each line in the file contains words separted by |
//There is an issue with the file (for our purposes)
//For example, both these lines are in the file:
// - bloom|blossom|flower|flourish|coloration
// - blossom|bloom|flower|flourish
//Use the list of distinct answers to deal with that issue and
//avoid reporting the same answer twice:
List<string> distinctAnswers = new List<string>();
//Keep reading while there is more to be read
while (sr.Peek() != -1) {
string aLine = sr.ReadLine();
//Use Linq to join words lacking 'ss' against the same words in the the line
var answer = from word1 in aLine.Split('|')
//Hold word1 in anonymous class/1)original value 2)word lacking 'ss'
let wp = new { Original = word1, WordNoSS = word1.Replace("ss", "") }
//Word2 values also come from the words in the line
join word2 in aLine.Split('|') on wp.WordNoSS equals word2
//Only use word1 if it has ss and we haven't found it already
where word1.Contains("ss")
&& !distinctAnswers.Contains(word1)
select wp;
//'answer' is an IEnumerable (a kind of list) containing entries
//of an anonymous type; each entry has properties 'Original' and 'WordNoSS'
//If the list has any entry, each will be a valid answer pair
foreach (var wp in answer) {
txtAnswer.Text += wp.Original + " - " + wp.WordNoSS + "\n";
distinctAnswers.Add(wp.Original);
}
}
}
MessageBox.Show("Done Solving", "Mission Accomplished",
MessageBoxButton.OK, MessageBoxImage.Information);
Mouse.OverrideCursor = null;
}
}
}
Now, here’s the XAML, you should be able to run it except for the background, which you can either comment-out, or else download yourself from here.
A couple comments:
- Since the solution was related to flowers, I decided to use a field of flowers for the background
- And make the answer textbox partly transparent using an opacity setting of .5
- The title bar uses a drop shadow effect for a little pizzaz
- Like previous puzzle solutions, I elected to draw my own icon instead of linking to a file
<Window x:Class="Jan26_2014.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Synonym Pair with Double-S" Height="350" Width="710"
WindowStartupLocation="CenterScreen" >
<Grid>
<!-- The Title with a drop shadow effect -->
<TextBlock FontSize="36" Grid.ColumnSpan="3"
Text="Two Synonyms Spelled Same Except for SS"
Foreground="DarkRed" HorizontalAlignment="Center">
<TextBlock.Effect>
<DropShadowEffect BlurRadius="5" Color="LightGray"
Opacity=".8" />
</TextBlock.Effect>
</TextBlock>
<!-- The Challenge textblock -->
<TextBlock Grid.Row="1" Grid.ColumnSpan="5" TextWrapping="Wrap"
FontSize="16" Margin="3">
<Bold>Challenge:</Bold> What word, containing two consecutive S's,
becomes its own synonym if you drop those S's?
</TextBlock>
<!-- The 3rd row has a label/textbox for the answer, plus the Solve button-->
<Label Grid.Row="2" Content="Answer(s):"
Target="{Binding ElementName=txtAnswer}"
VerticalAlignment="Top" FontSize="16" FontWeight="Bold" />
<TextBox Grid.Row="2" Grid.Column="1" Name="txtAnswer"
TextWrapping="Wrap" AcceptsReturn="True" Opacity=".5"
FontWeight="Black" FontSize="16"
/>
<Button Grid.Row="2" Grid.Column="2" Name="btnSolve"
Content="_Solve" Height="30"
FontSize="16" FontWeight="Black"
VerticalAlignment="Top" Margin="3" Click="btnSolve_Click" />
<!-- Comment-out the next 3 lines if you don't have a background file with that name -->
<Grid.Background>
<ImageBrush ImageSource="/Jan26_2014;component/Images/Flowers.jpg" Opacity=".6" />
</Grid.Background>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="auto" />
<ColumnDefinition />
<ColumnDefinition Width="auto" />
</Grid.ColumnDefinitions>
<Grid.RowDefinitions>
<RowDefinition Height="auto" />
<RowDefinition Height="auto" />
<RowDefinition />
</Grid.RowDefinitions>
</Grid>
<!-- I elected to use a icon drawn in XAML, a flower was too hard -->
<Window.Icon>
<DrawingImage>
<DrawingImage.Drawing>
<GeometryDrawing Brush="Gold">
<GeometryDrawing.Pen>
<Pen Brush="Yellow" Thickness="1" />
</GeometryDrawing.Pen>
<GeometryDrawing.Geometry>
<EllipseGeometry RadiusX="25" RadiusY="25" />
</GeometryDrawing.Geometry>
</GeometryDrawing>
</DrawingImage.Drawing>
</DrawingImage>
</Window.Icon>
</Window>
That’s all, good luck!
